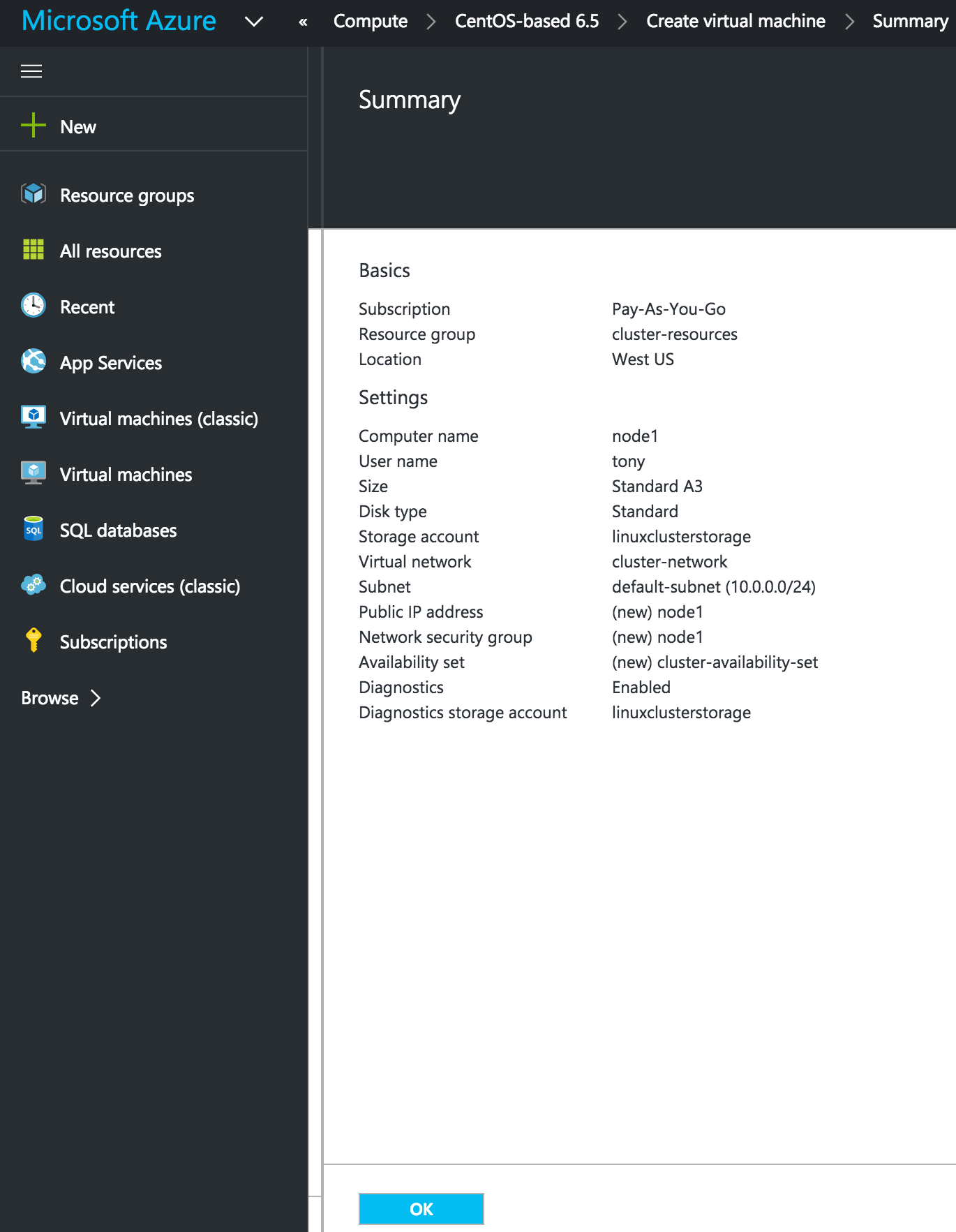
In this step by step guide I will take you through all steps required to configure a highly available, 2-node MySQL cluster (plus witness server) in Google Cloud Platform (Google Compute Engine, aka GCE). The guide includes both screenshots, shell commands and code snippets as appropriate. I assume that you are somewhat familiar with Google Cloud Platform and already have an account. If not, you can sign up for a free trial today. I’m also going to assume that you have basic linux system administration skills as well as understand basic failover clustering concepts like Virtual IPs, quorum, etc.
Disclaimer: The cloud is a rapidly moving target. As such, features/screens/buttons are bound to change over time so your experience may vary slightly from what you’ll see below. While this guide will show you how to make a MySQL database highly available, you could certainly adapt this information and process to protect other applications or databases, like SAP,PostgreSQL, Oracle, WebSphere MQ, NFS file servers, and more.
These are the high level steps to create a highly available MySQL database within Google Compute Engine:
- Create a Project
- Create Instances (Virtual Machines)
- Create Instance Groups
- Create Firewall Rule to allow VNC access
- Linux OS Configuration
- Install and Configure MySQL
- Install and Configure Cluster
- Create an Internal Load Balancer
- Create Firewall Rules for Internal Load Balancer
- Test Cluster Connectivity
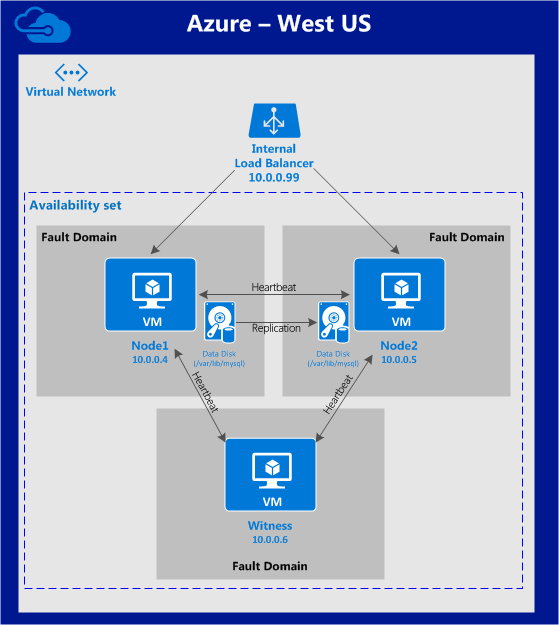
Overview
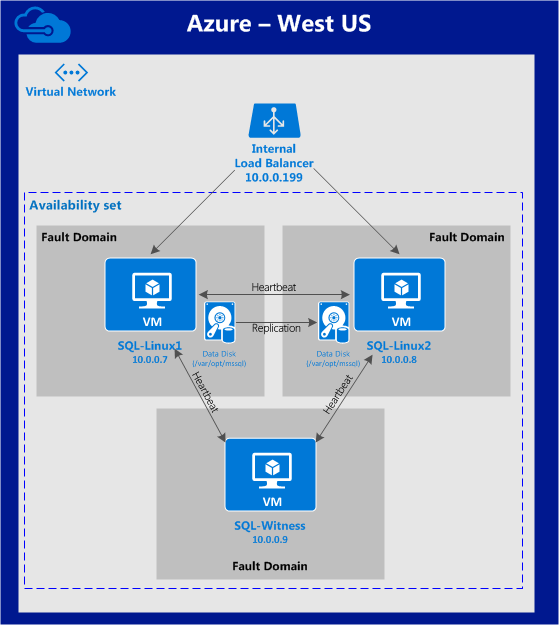
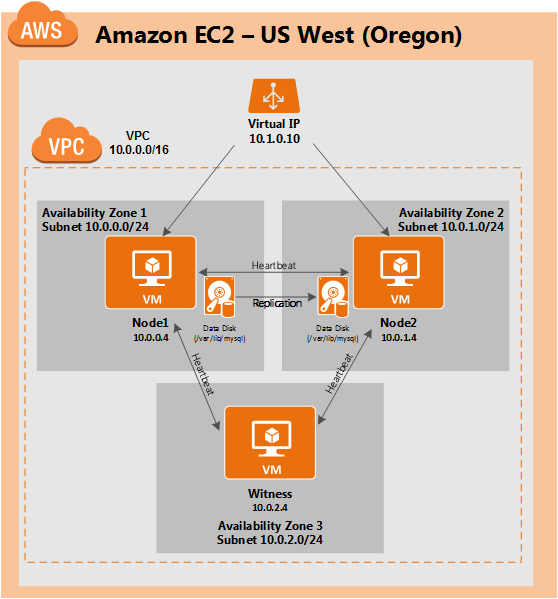
This article will describe how to create a cluster within a single Google Cloud region. The cluster nodes (node1, node2 and the witness server) will all reside in the region “us-central1” (10.128.0.0/20 network) but you can select your region accordingly.
The configuration will look like this:
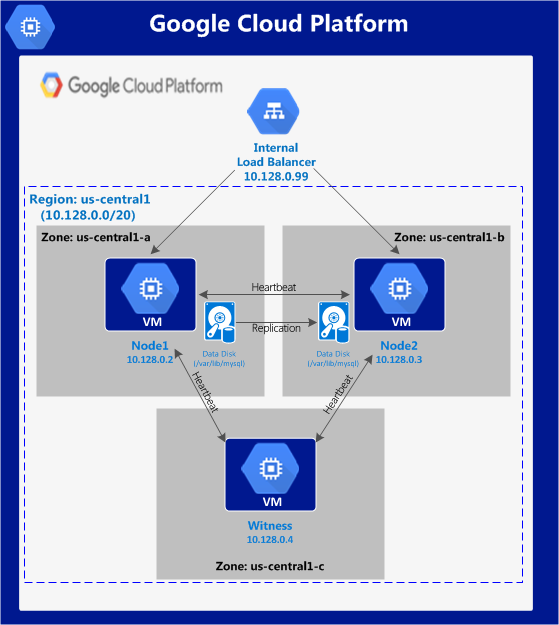
The following IP addresses will be used:
- node1: 10.128.0.2
- node2: 10.128.0.3
- witness: 10.128.0.4
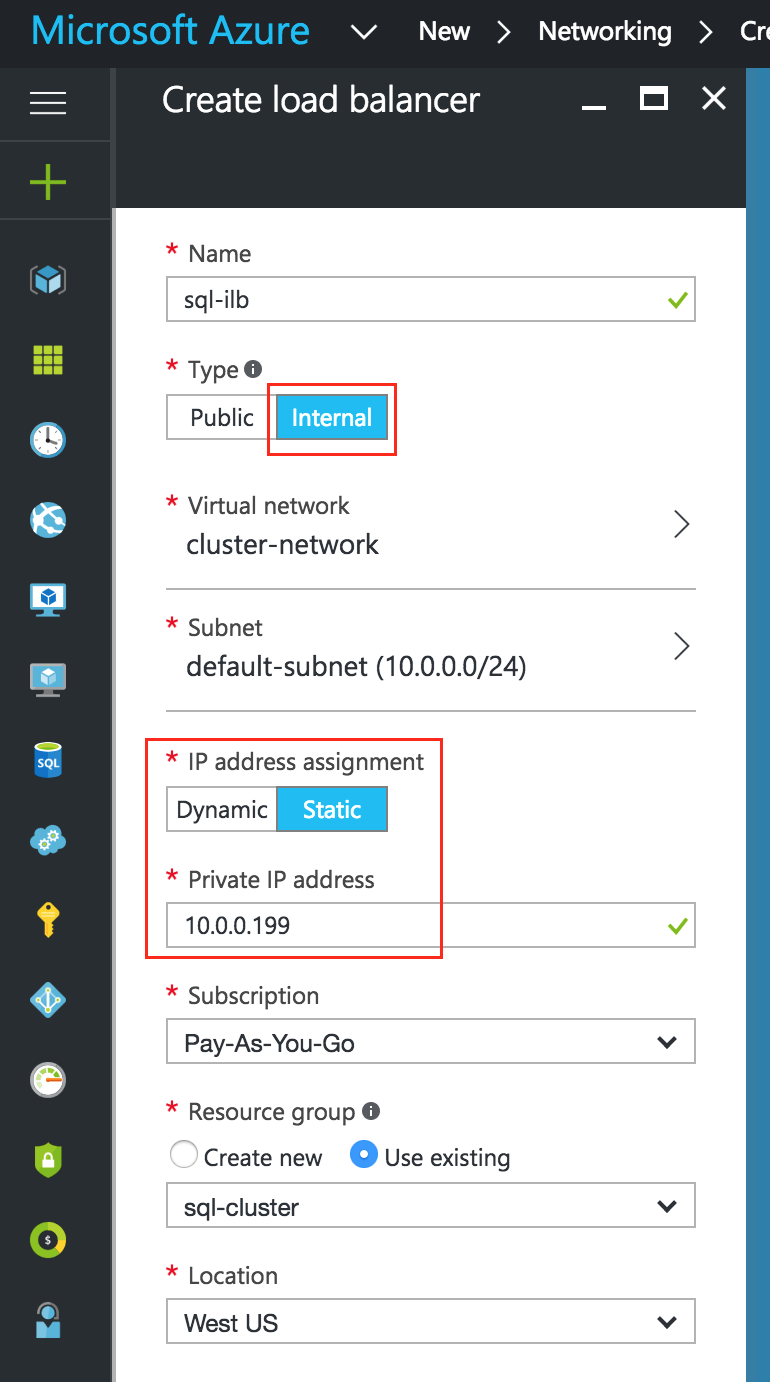
- Internal Load Balancer IP: 10.128.0.99
- MySQL port: 3306
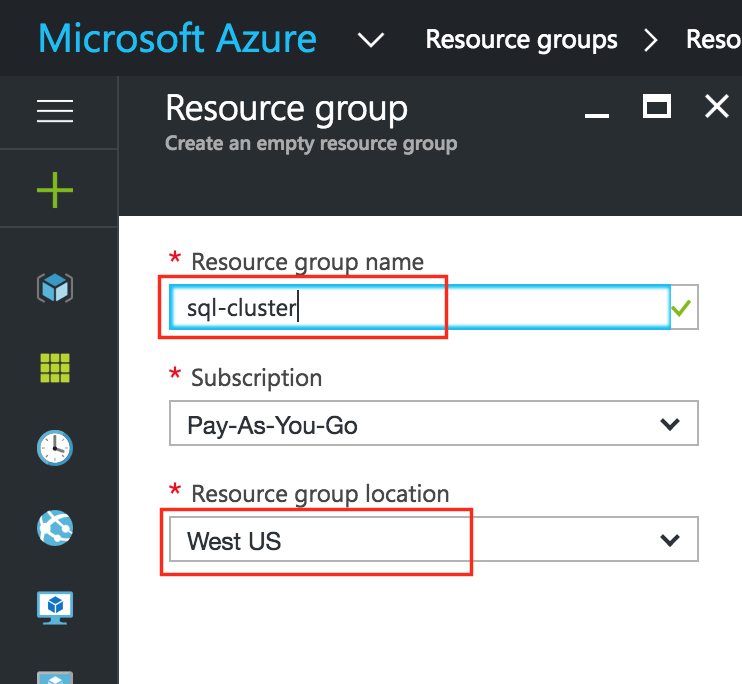
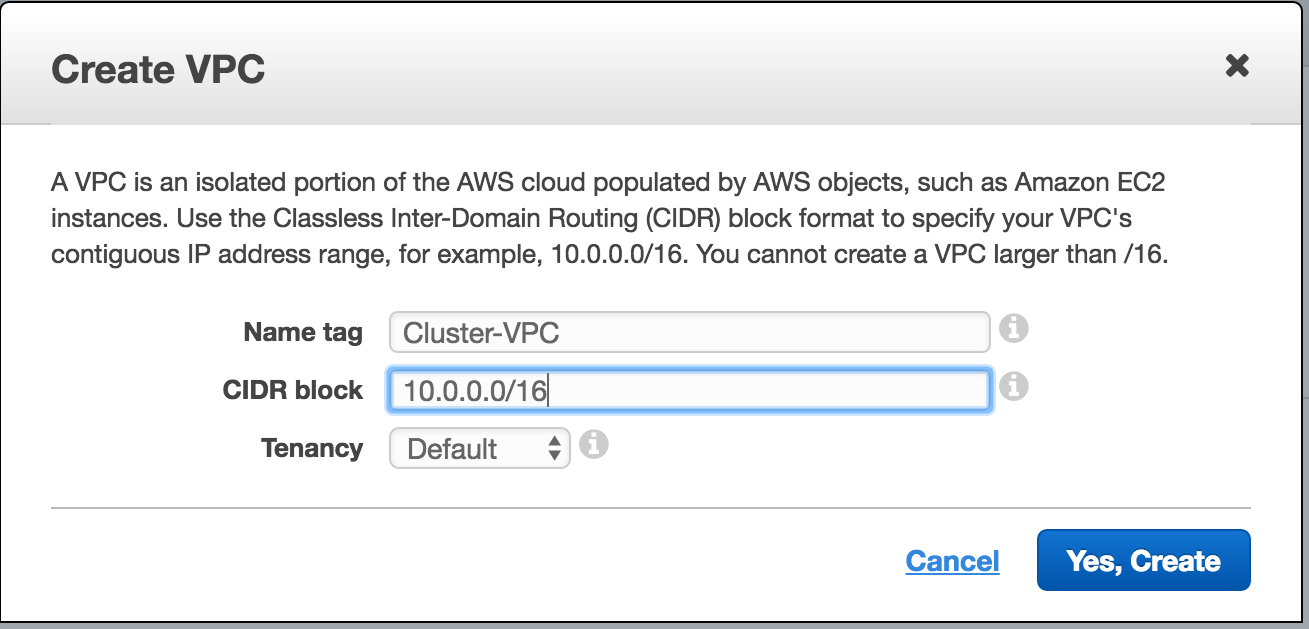
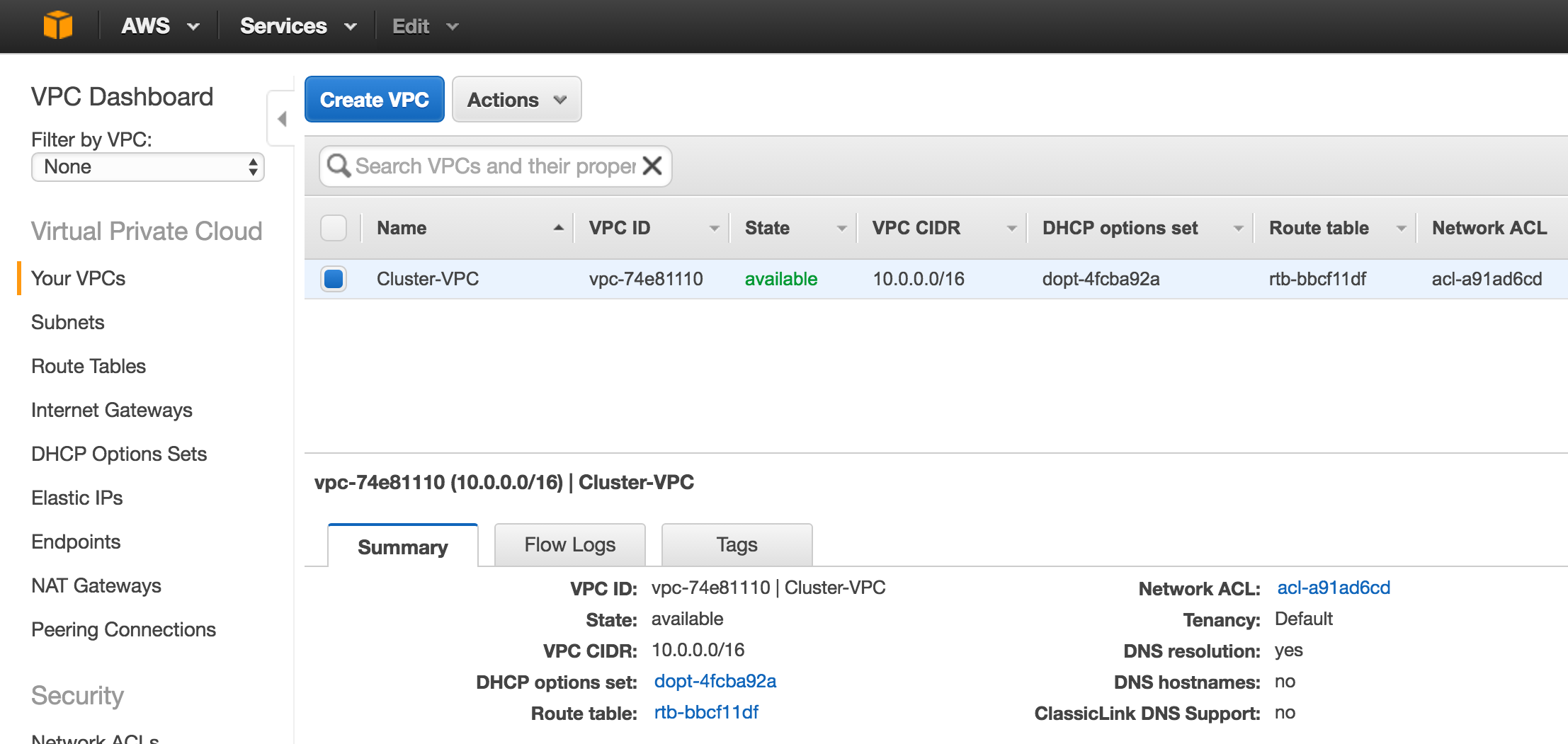
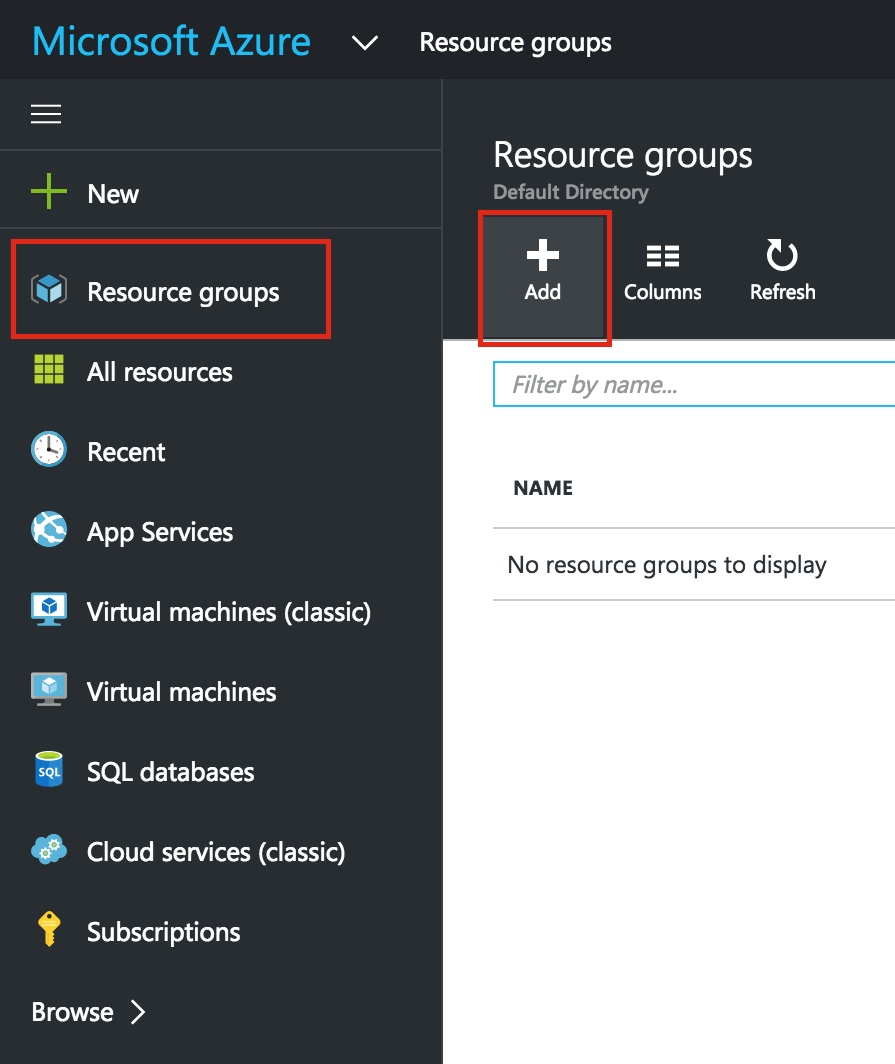
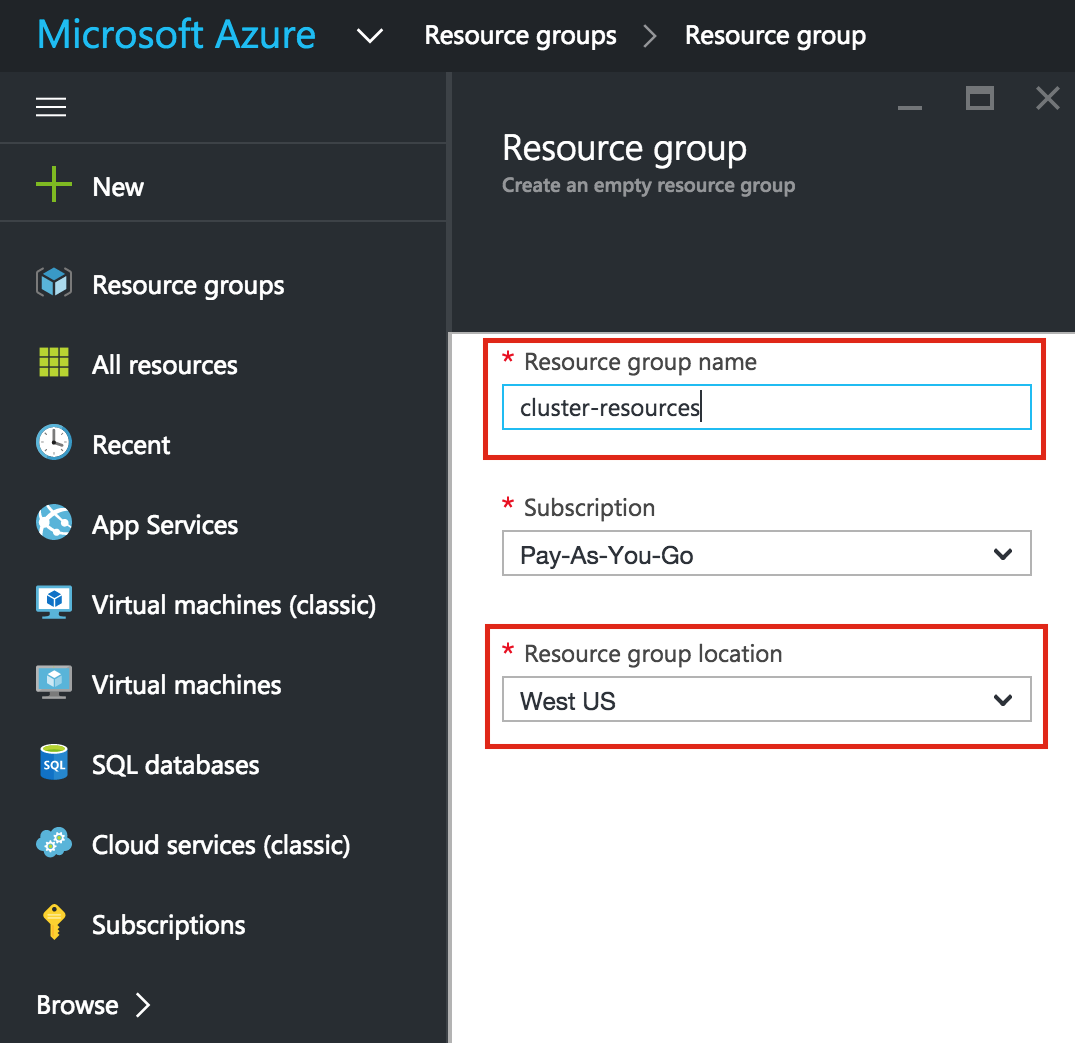
Create a Project
Upon first login, you’ll see an empty Home Dashboard and will be asked to create a Project. All Google Compute Engine resources we will be creating will belong to this Google Cloud Platform project.
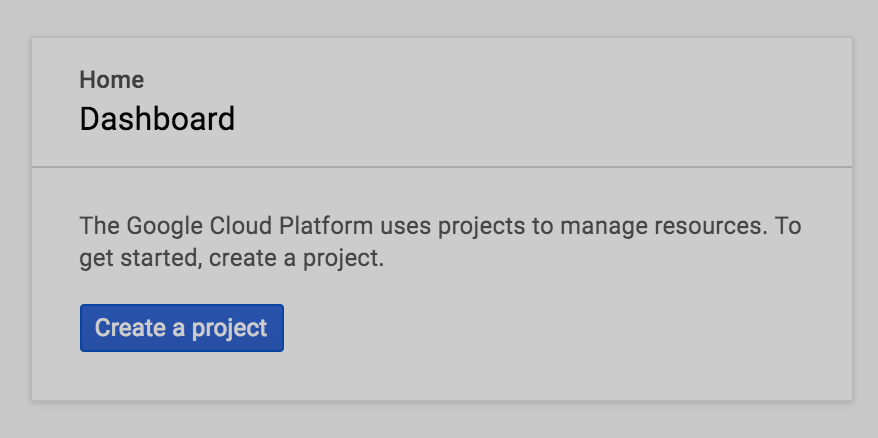
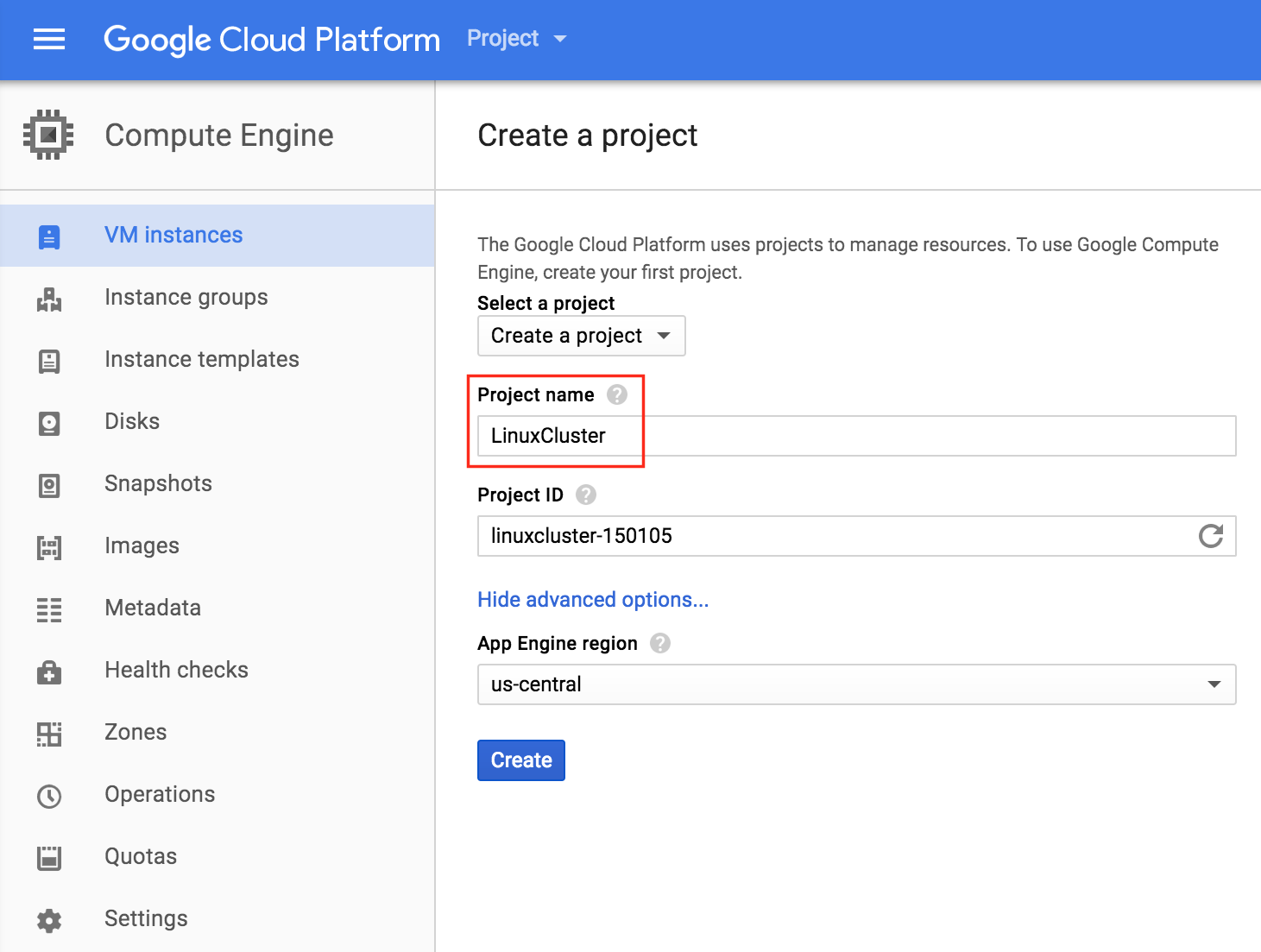
Here we will call our newly created Project “LinuxCluster”:
Create Instances (Virtual Machines)
We will be provisioning 3 Virtual Machines in this guide. The first two VMs (I’ll call them “node1” and “node2”) will function as cluster nodes with the ability to bring the MySQL database and it’s associated resources online. The 3rd VM will act as the cluster’s witness server for added protection against split-brain.
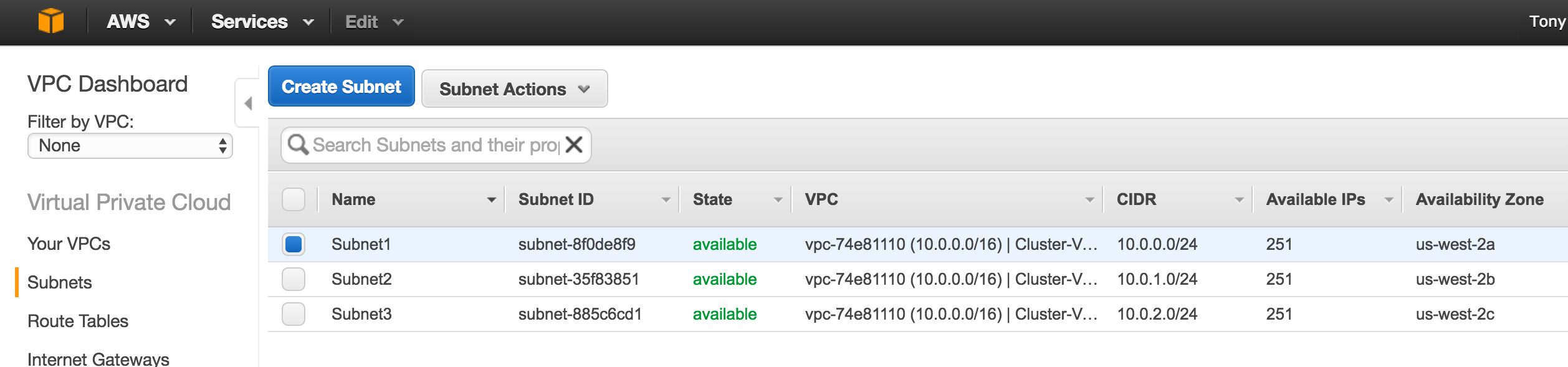
To ensure maximum availability, all 3 VMs will reside in different zones within the region (in this example: us-central1-a, us-central1-b, us-central1-c).
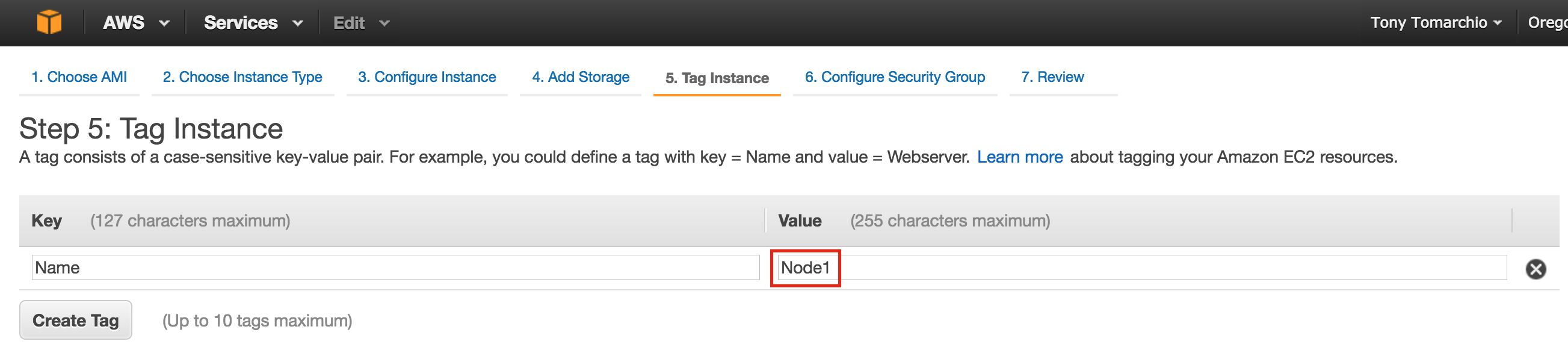
Create “node1” Instance
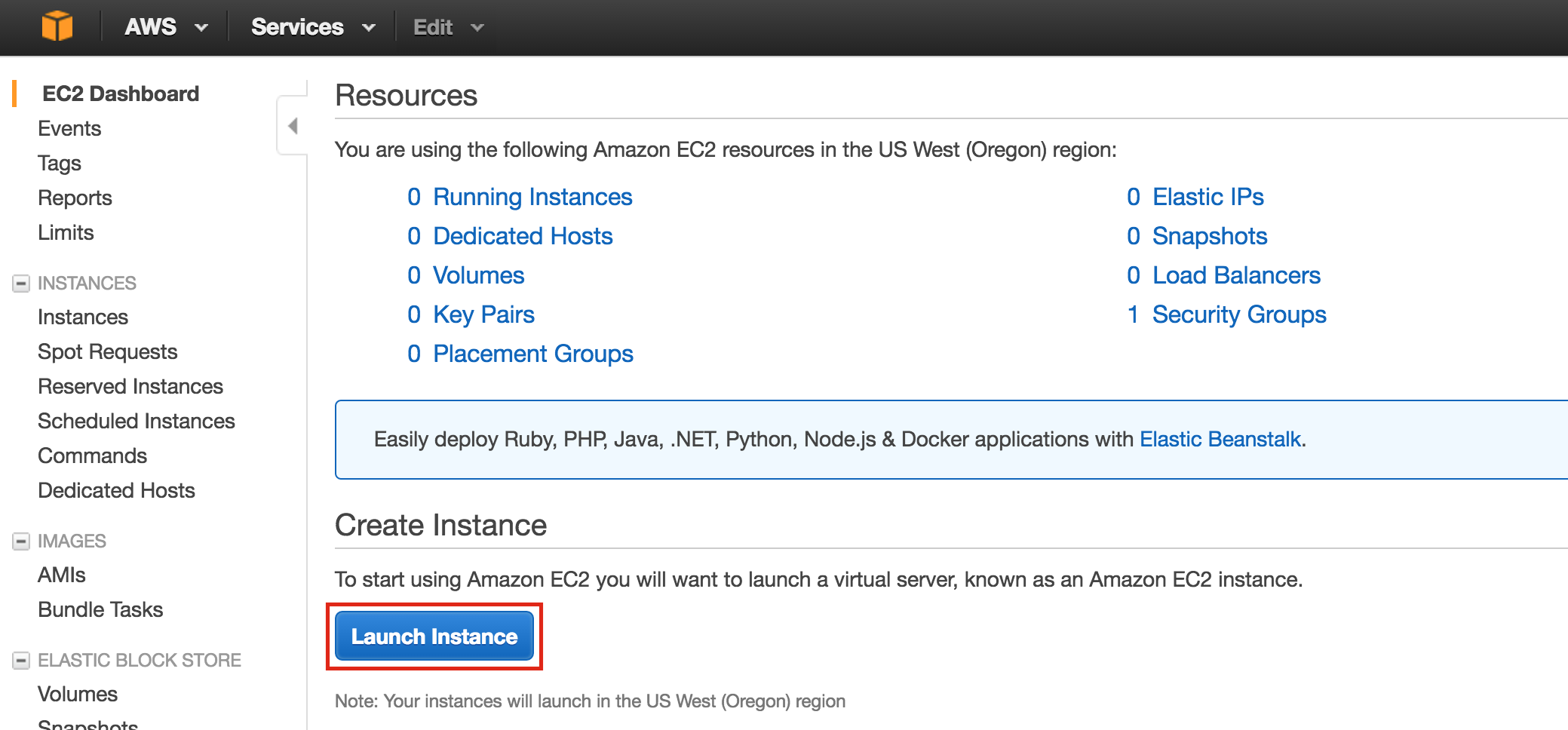
Create your first VM instance (“node1”). If this is the first time you’ve created an instance, your screen will look something like the image below. Click “Create Instance” button in the center of your screen:
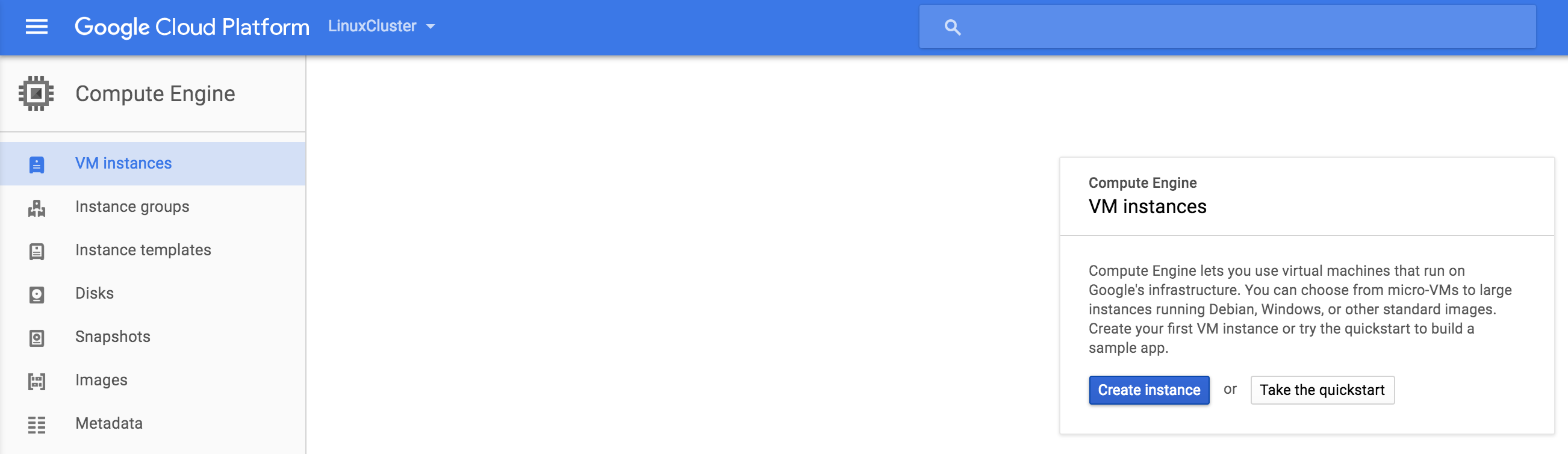
If you have other instances already running in GCE, your screen will look a bit different. Still, click “create instance” to continue:

By default, Debian linux is usually selected by default. We *DON’T* want this as we’ll be using CentOS 6.X in this guide.
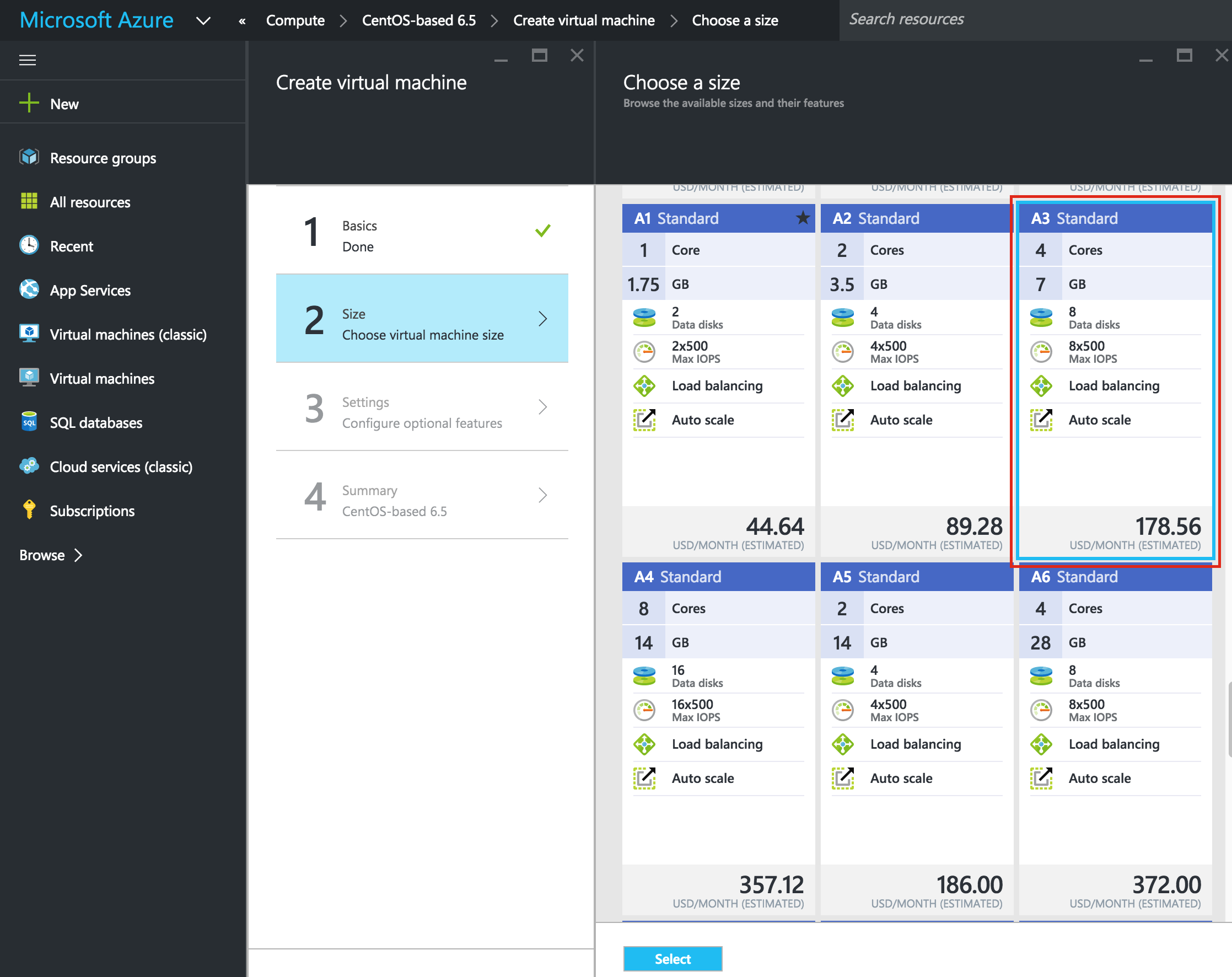
Give the instance a name (“node1”), select the first zone (a) within our region (us-central1) and make sure to click “Change” to select the proper boot image. You can size the instance based on your workload requirements, but for the purposes of this guide we’ll be using the default size to minimize cost, which is a fairly small VM (1 vCPU and only 3.75GB RAM)
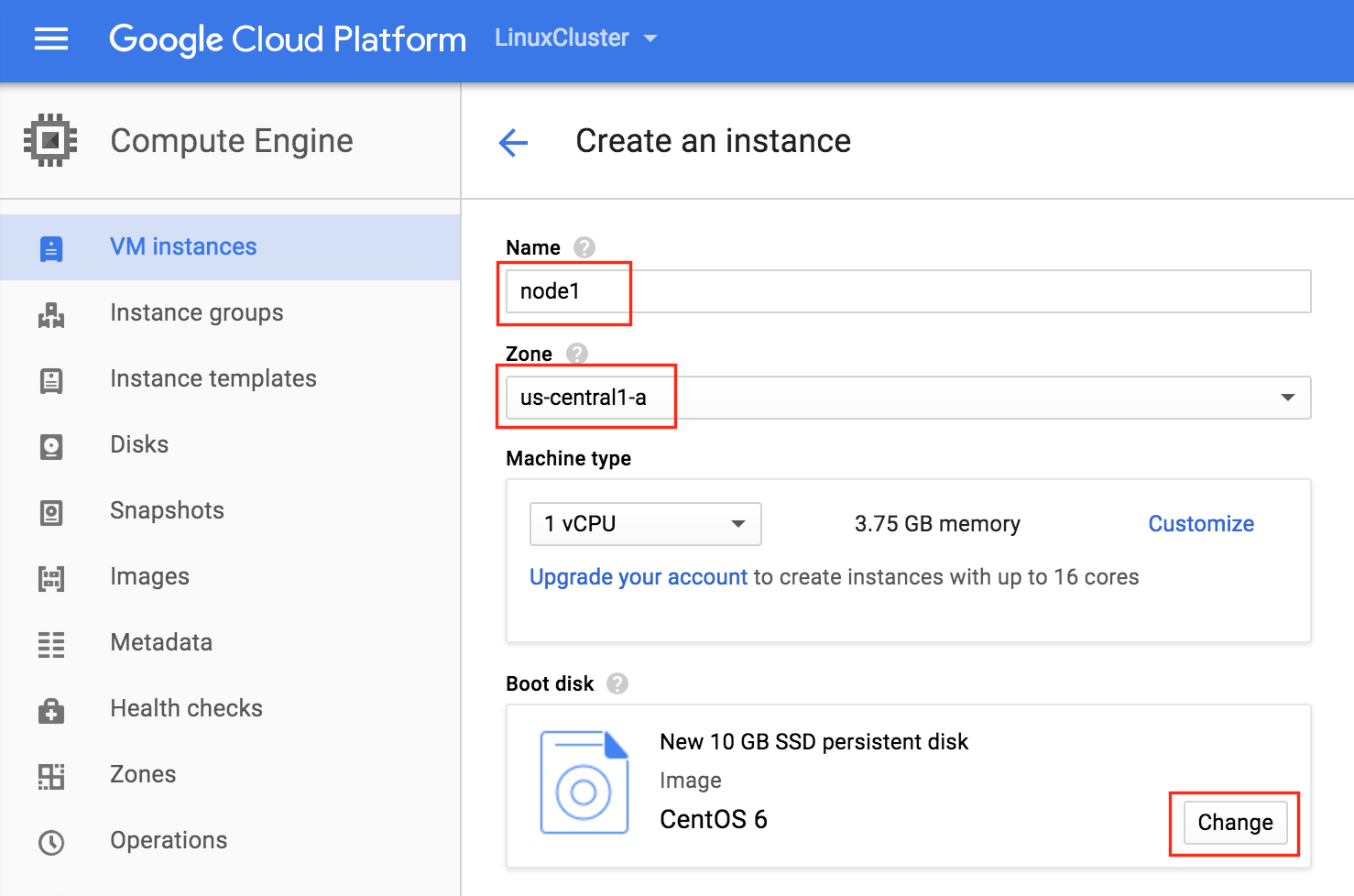
In the Boot disk pop up screen, select CentOS 6 and at the bottom we will go with an SSD boot disk. 10GB is more than sufficient for the purposes of this guide. You can size your systems accordingly:
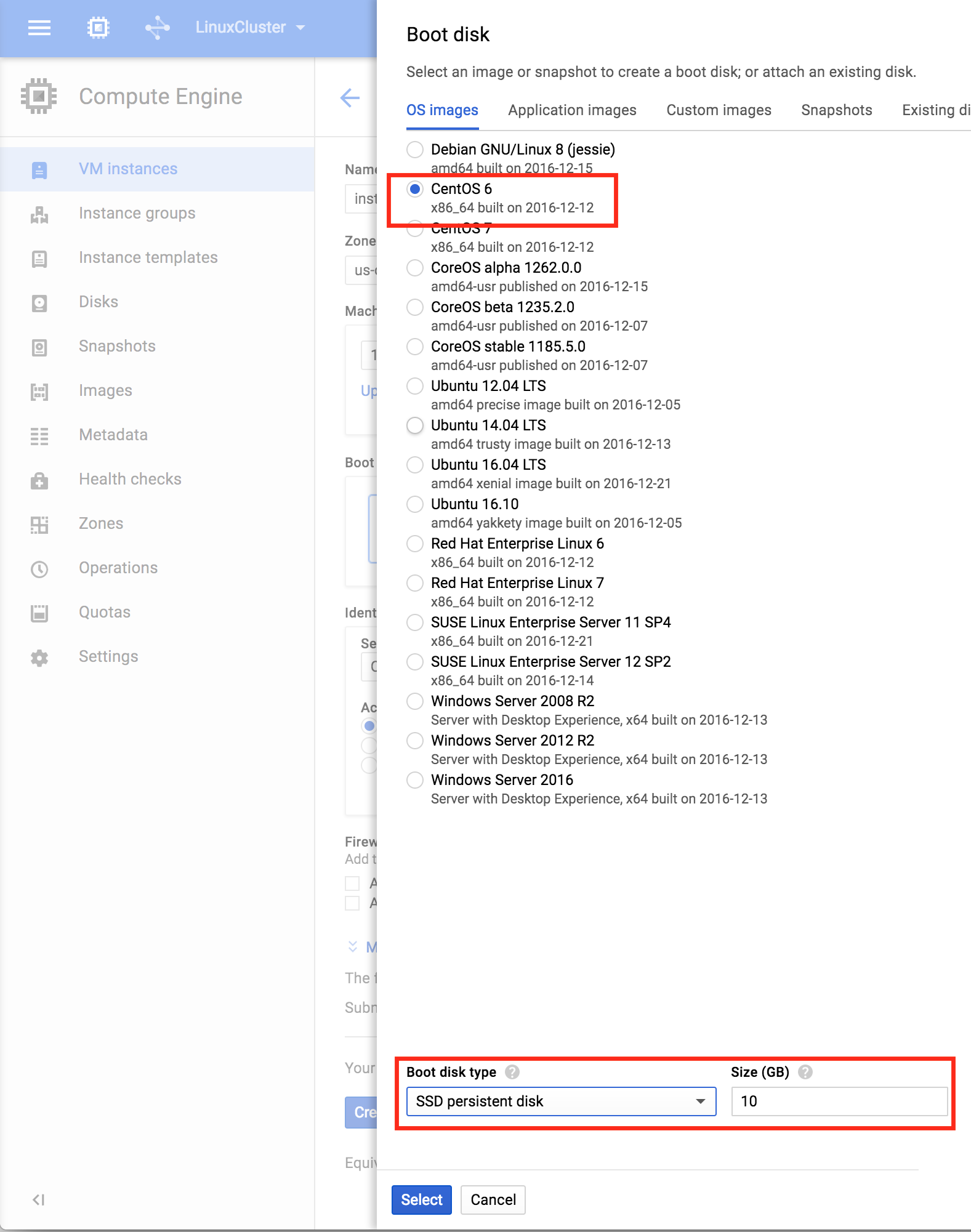
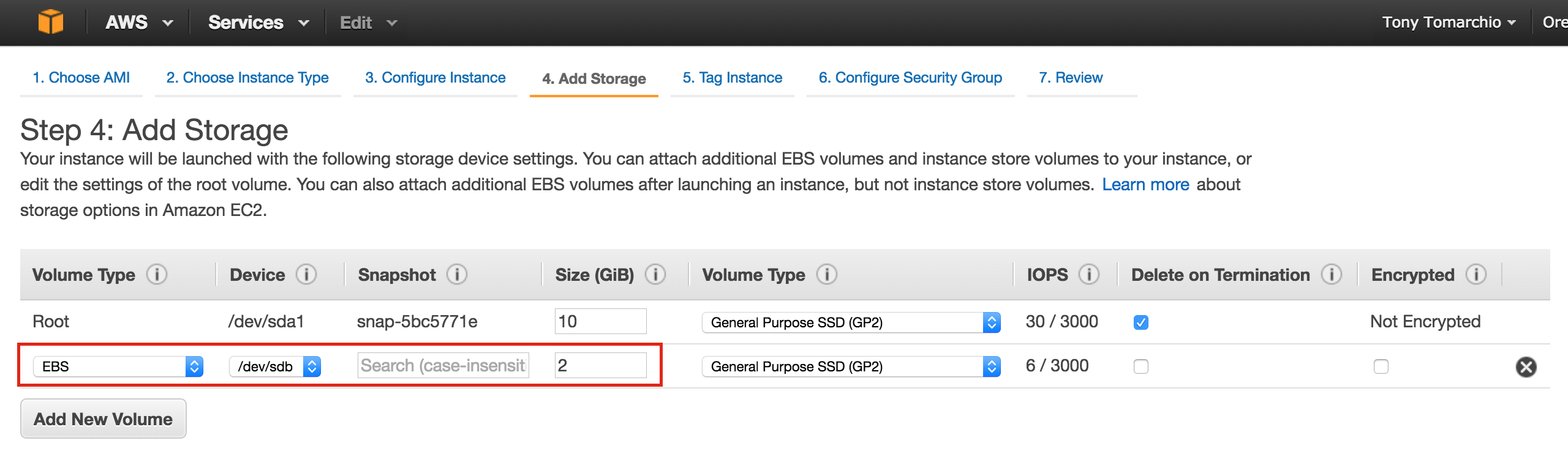
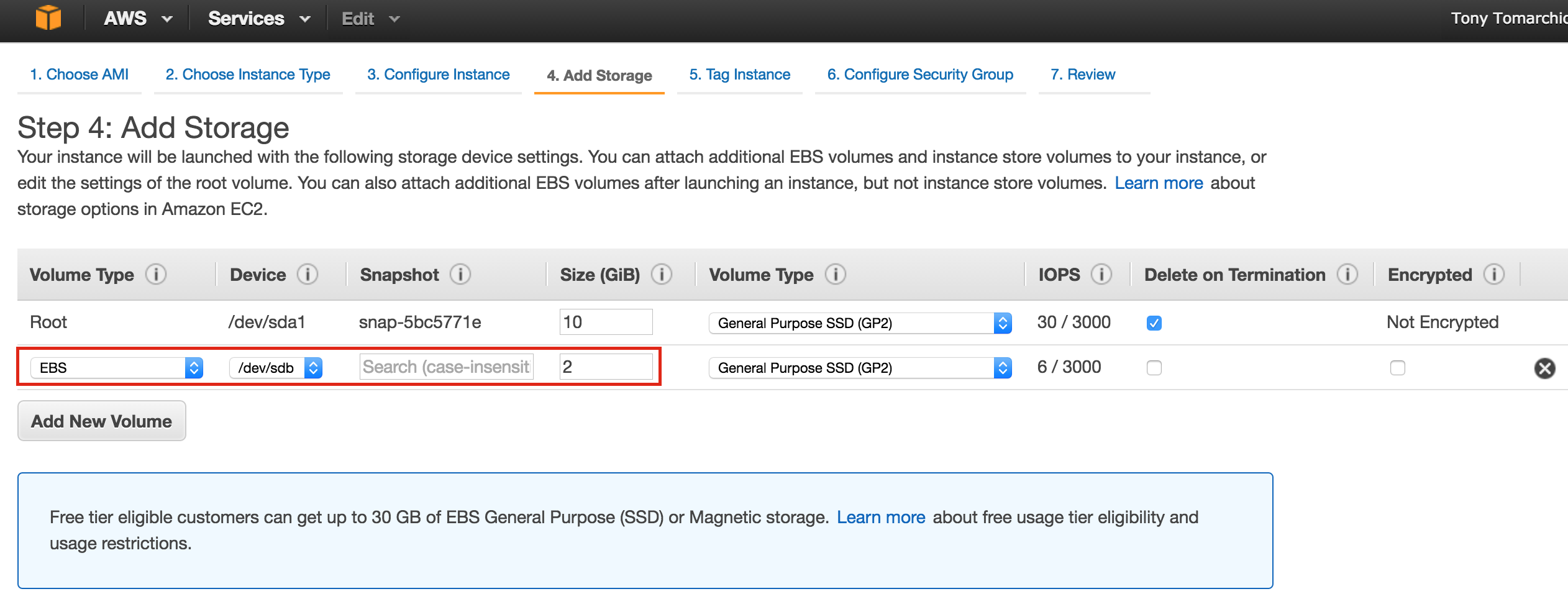
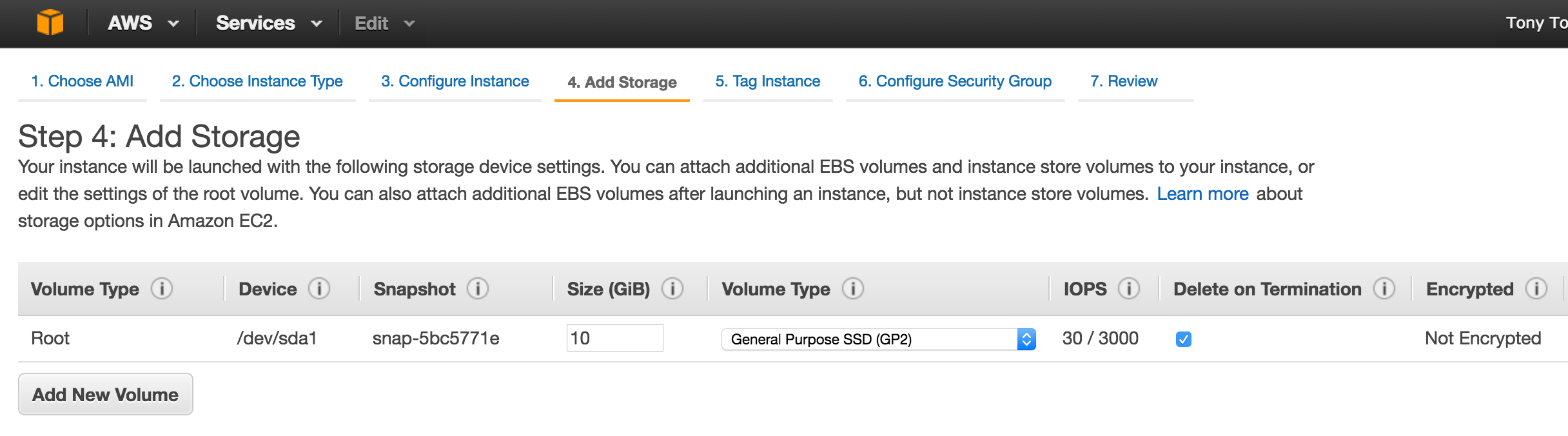
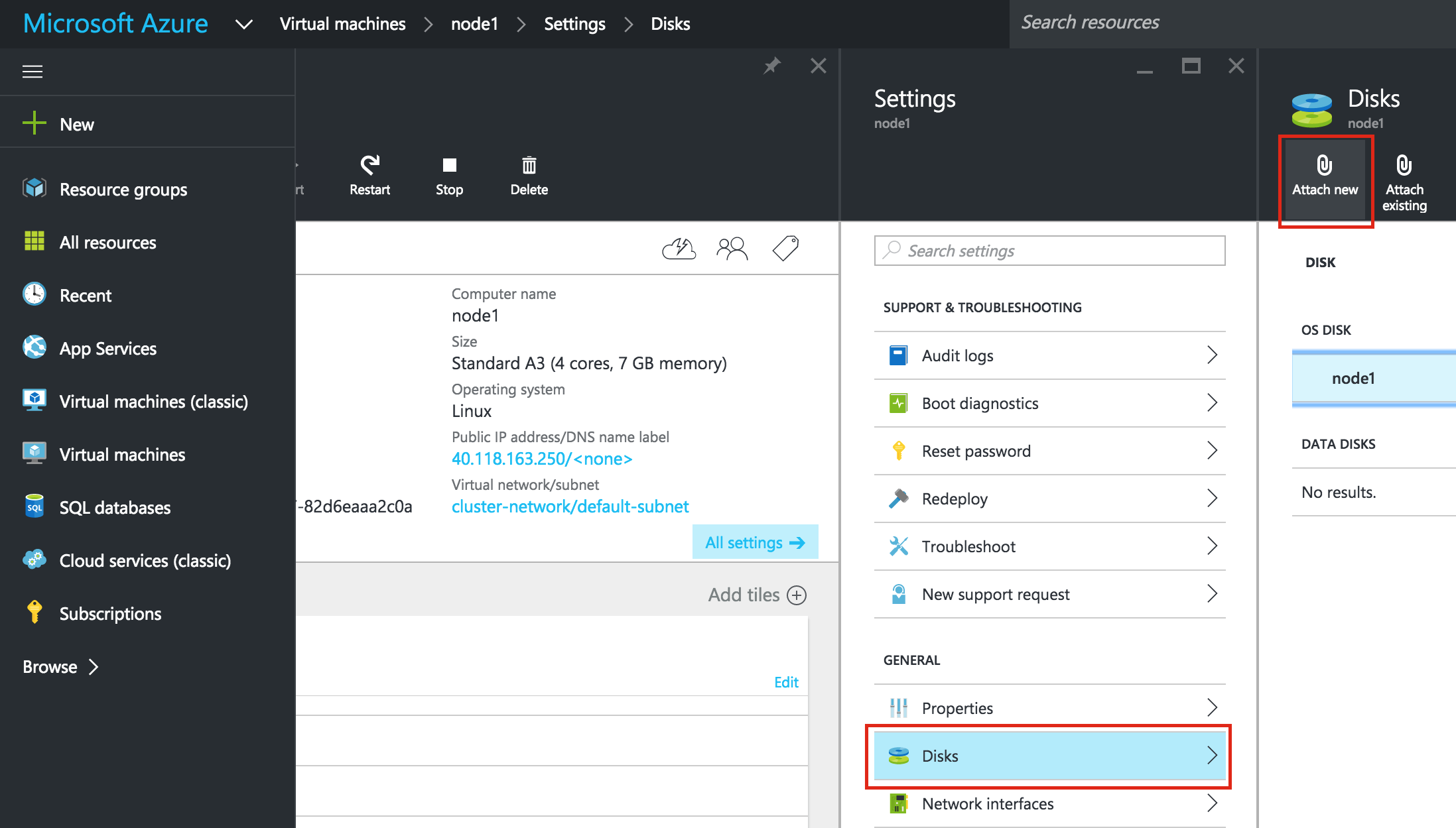
After clicking “Select”, you’ll be brought back to the Create An Instance screen. Towards the bottom, click “Management, disk, networking, SSH keys” because we will be adding a 2nd disk to our VM. This 2nd disk will be used to store our databases, and it’s what will later be replicated/synchronized by the clustering software.
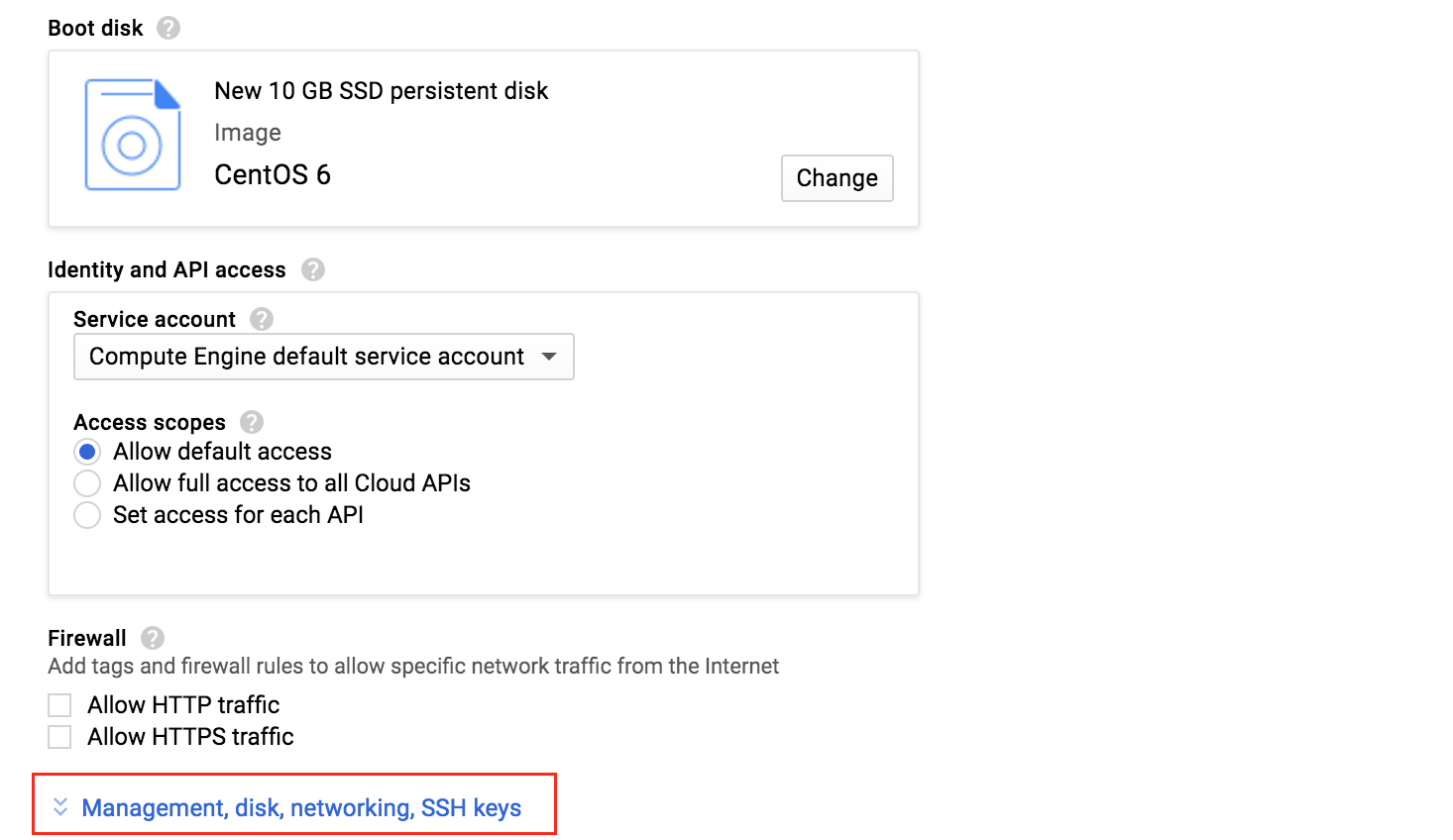
Select the “Disks” tab, and click “+ Add item” to add a 2nd disk to this instance:
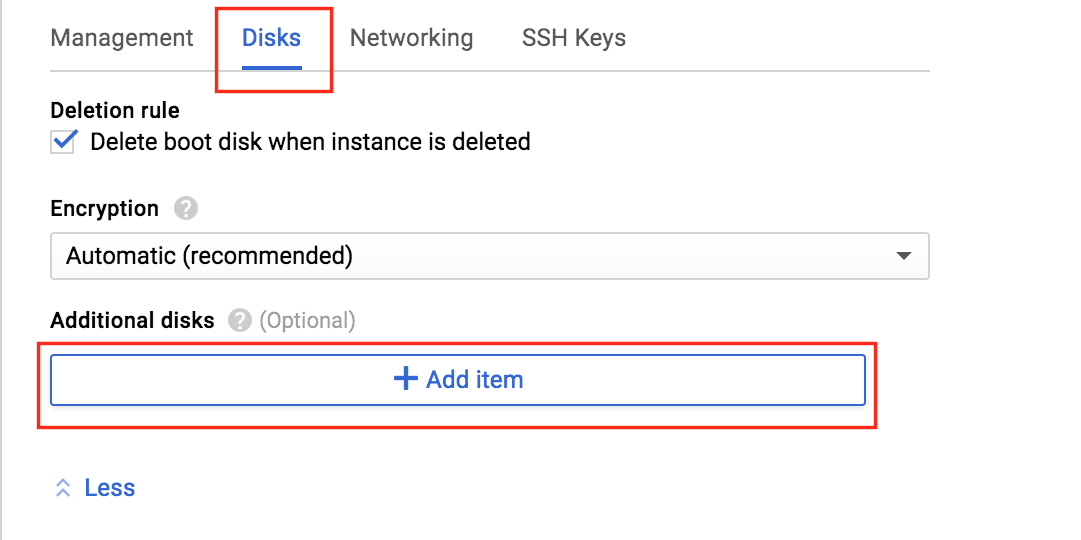
Click “Create disk”:
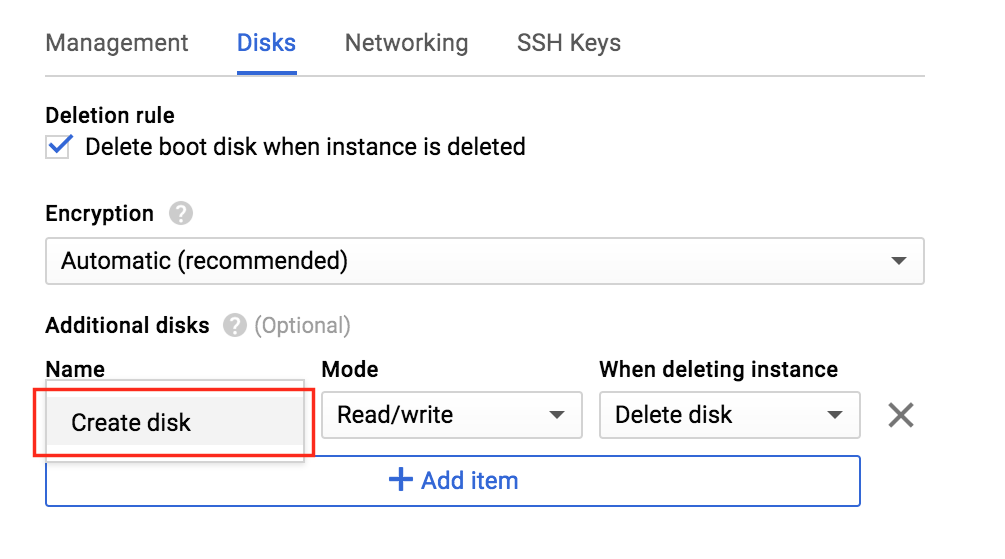
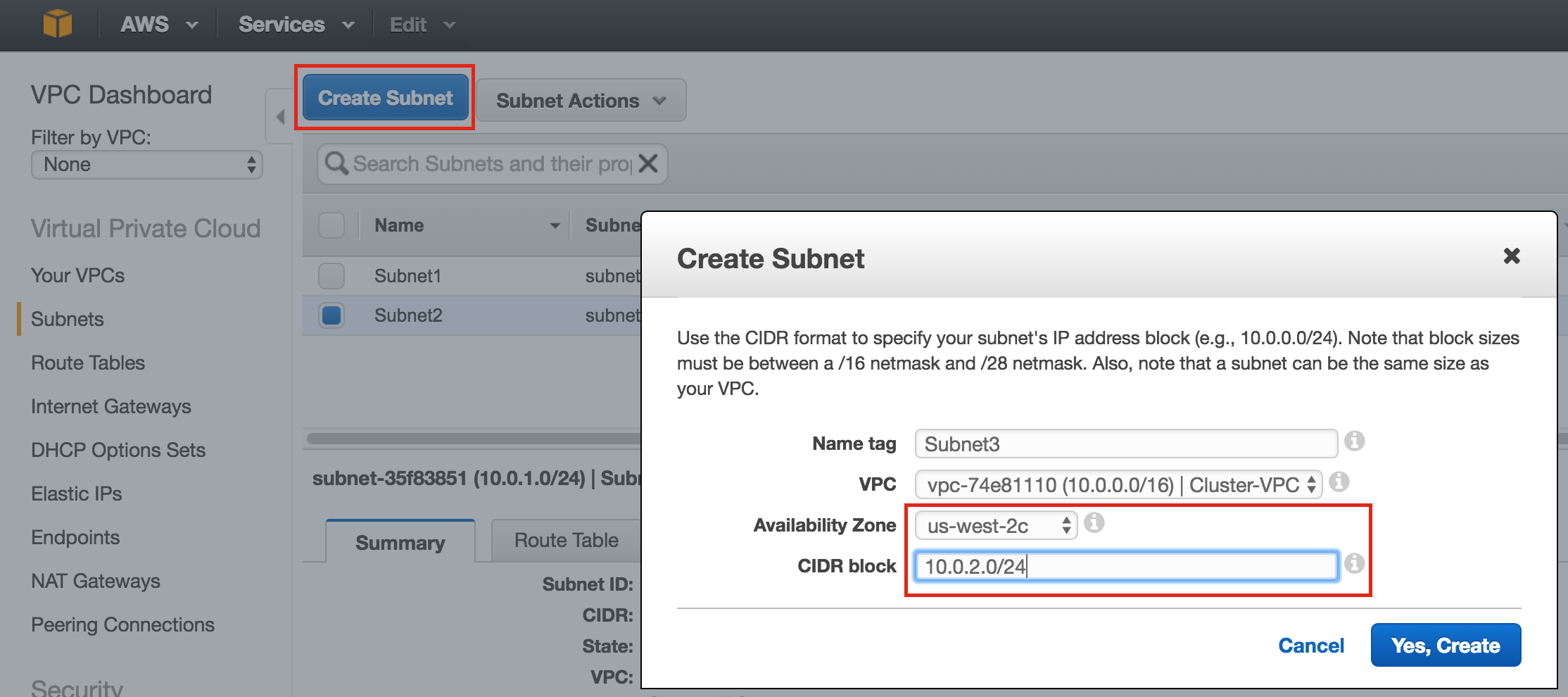
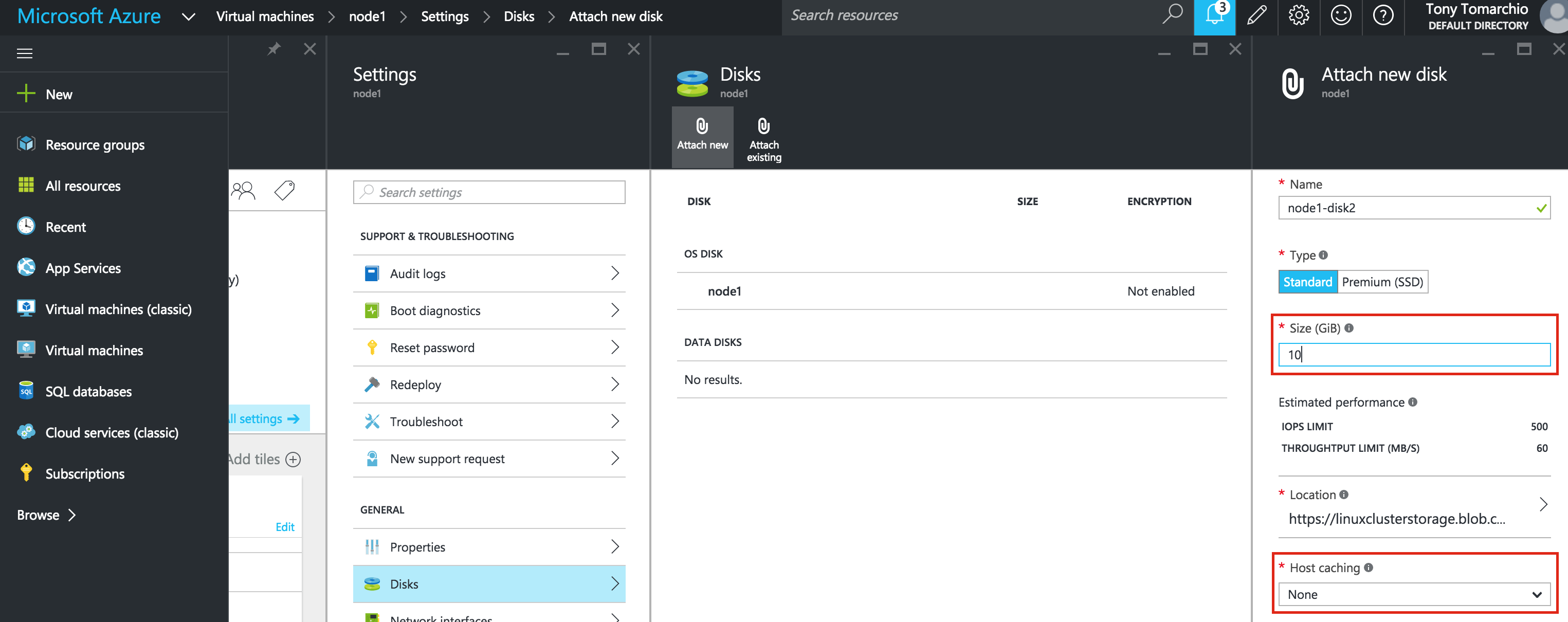
Give the new disk a name, select desired type, and start with a blank disk. 10 GB should be more than sufficient for our needs here in this example configuration. NOTE: Remember the value you set here. Both cluster nodes (node1 and node2) needs to be the SAME SIZE:
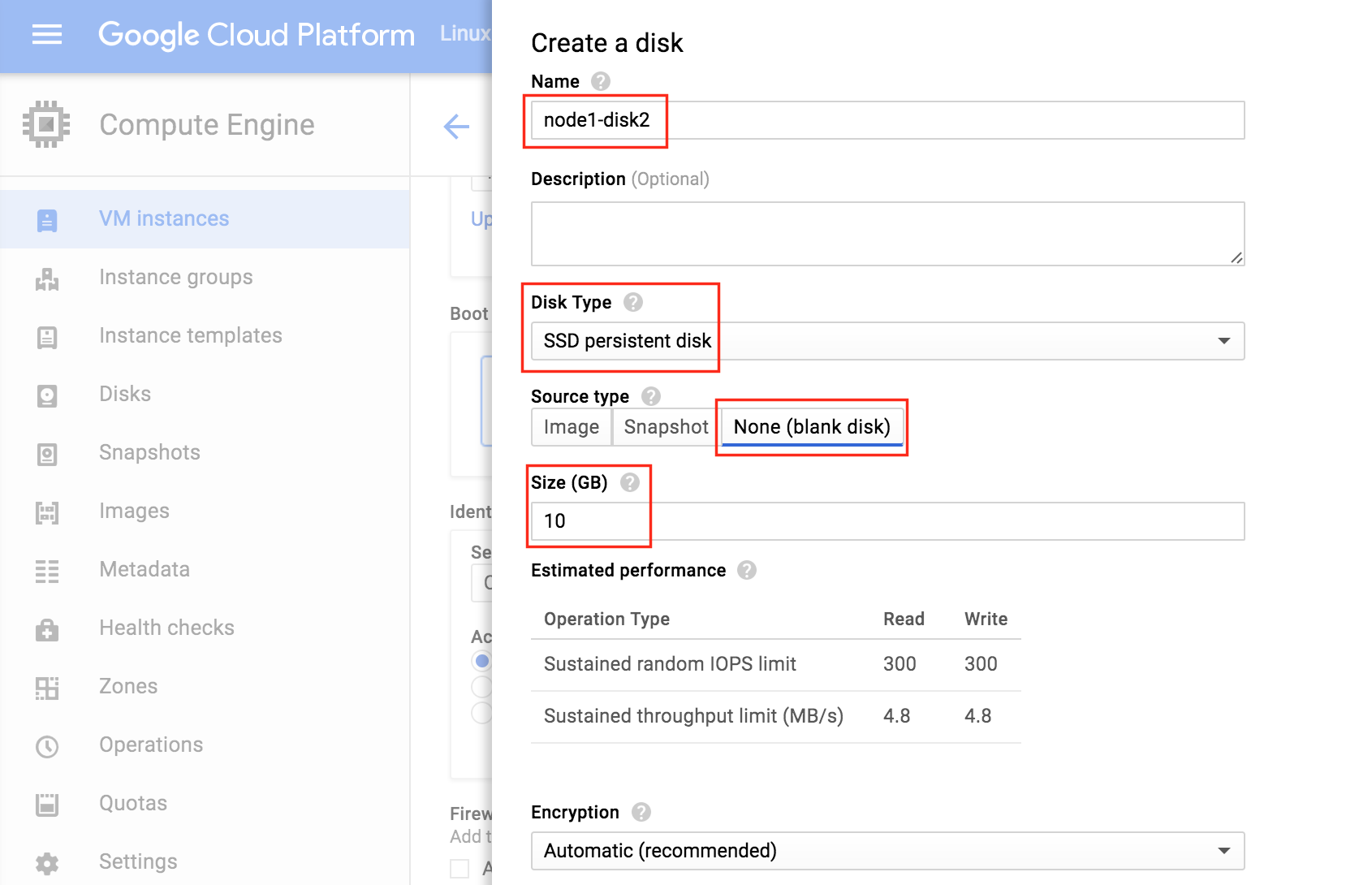
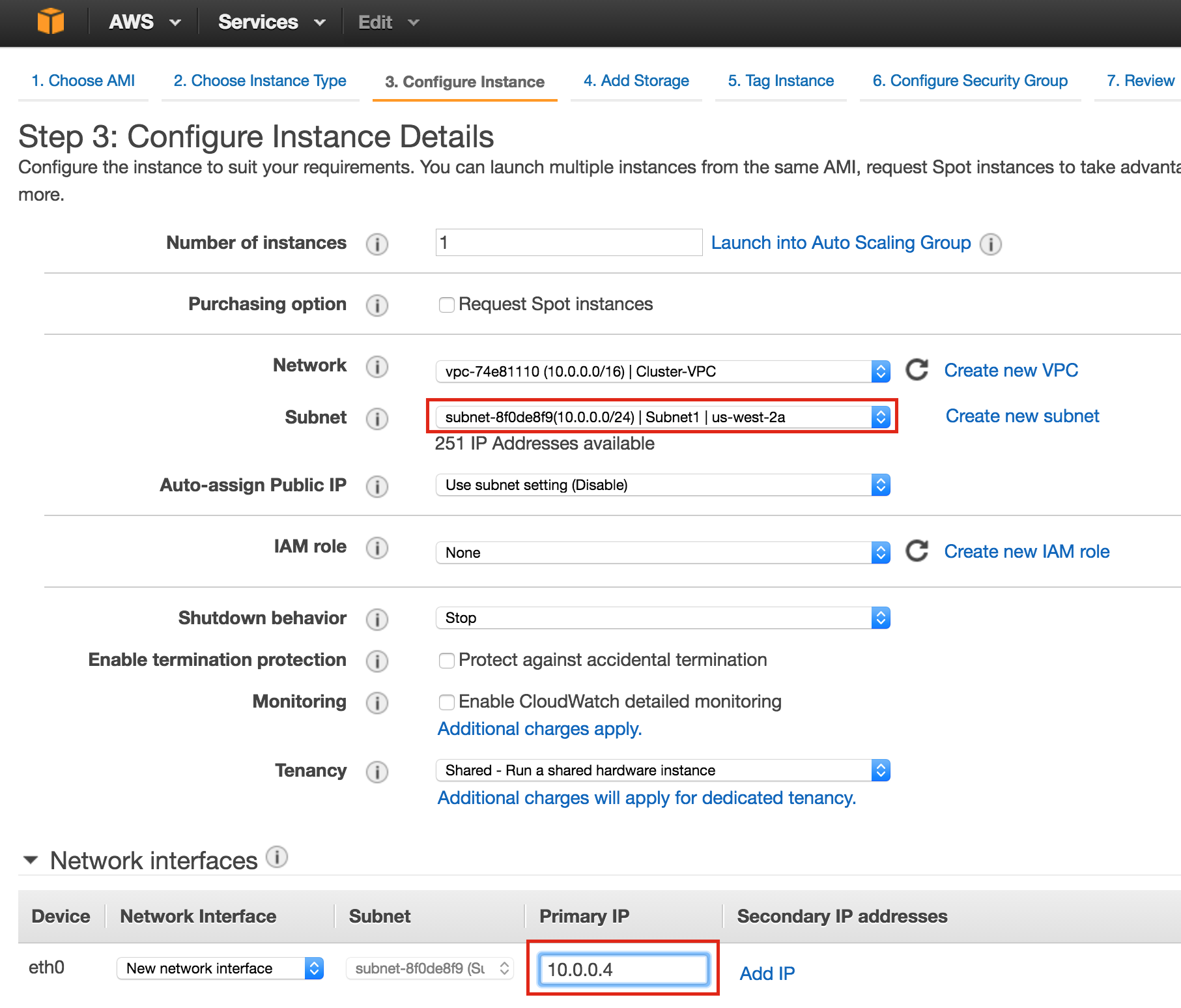
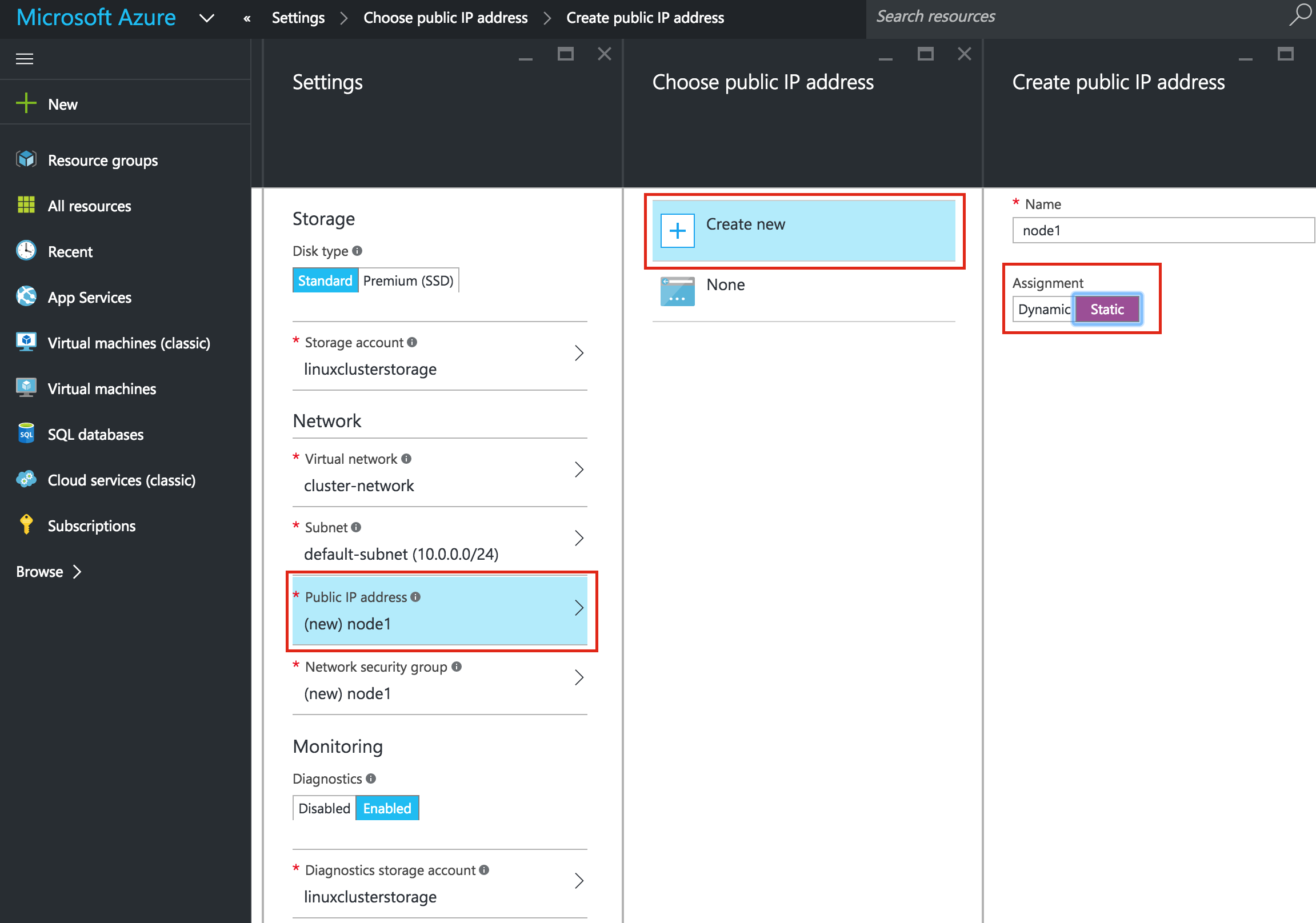
Finally, click the “Networking” tab, and give node1 a customer Internal IP.
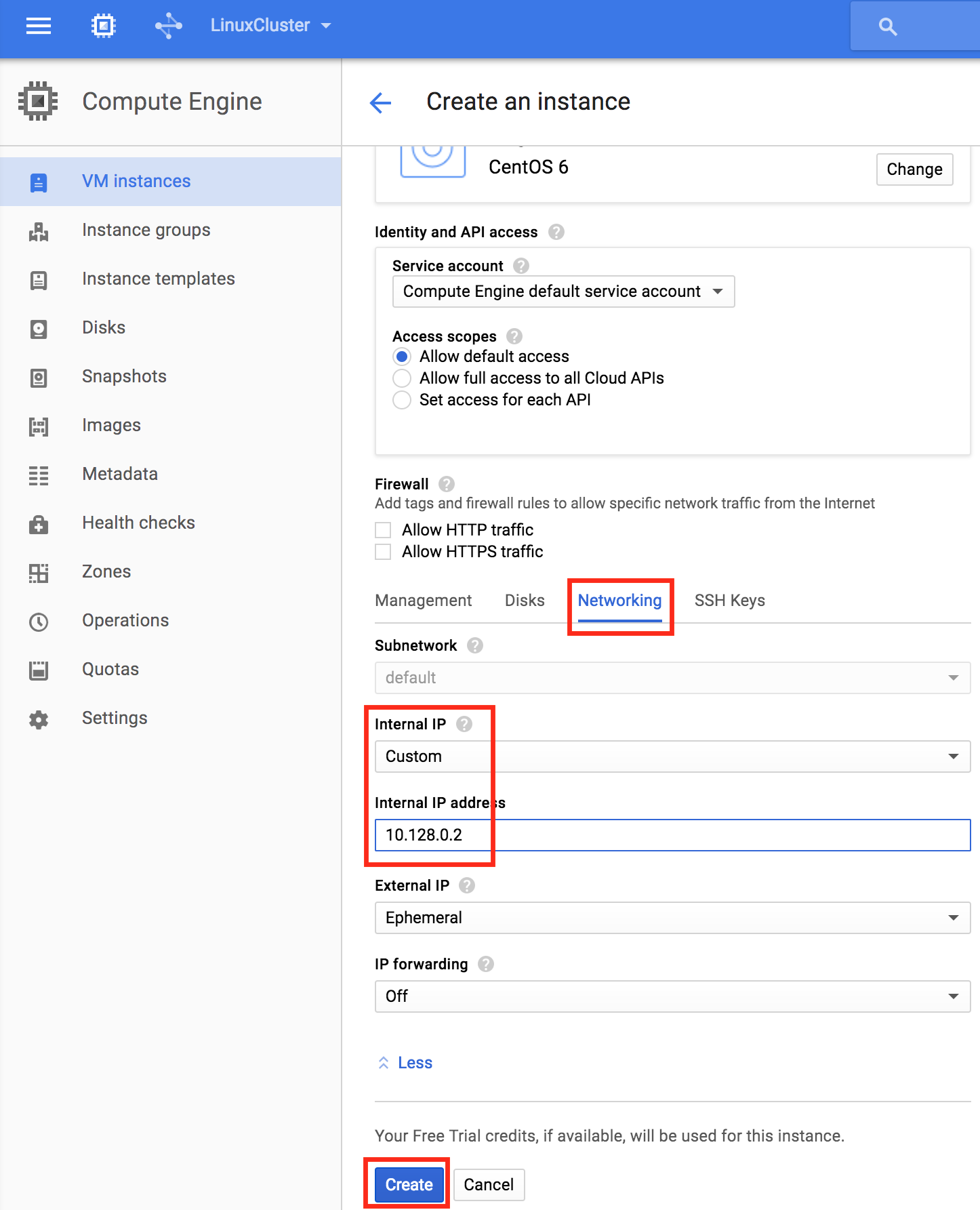
Click “Create” to launch your new instance:

Create “node2”
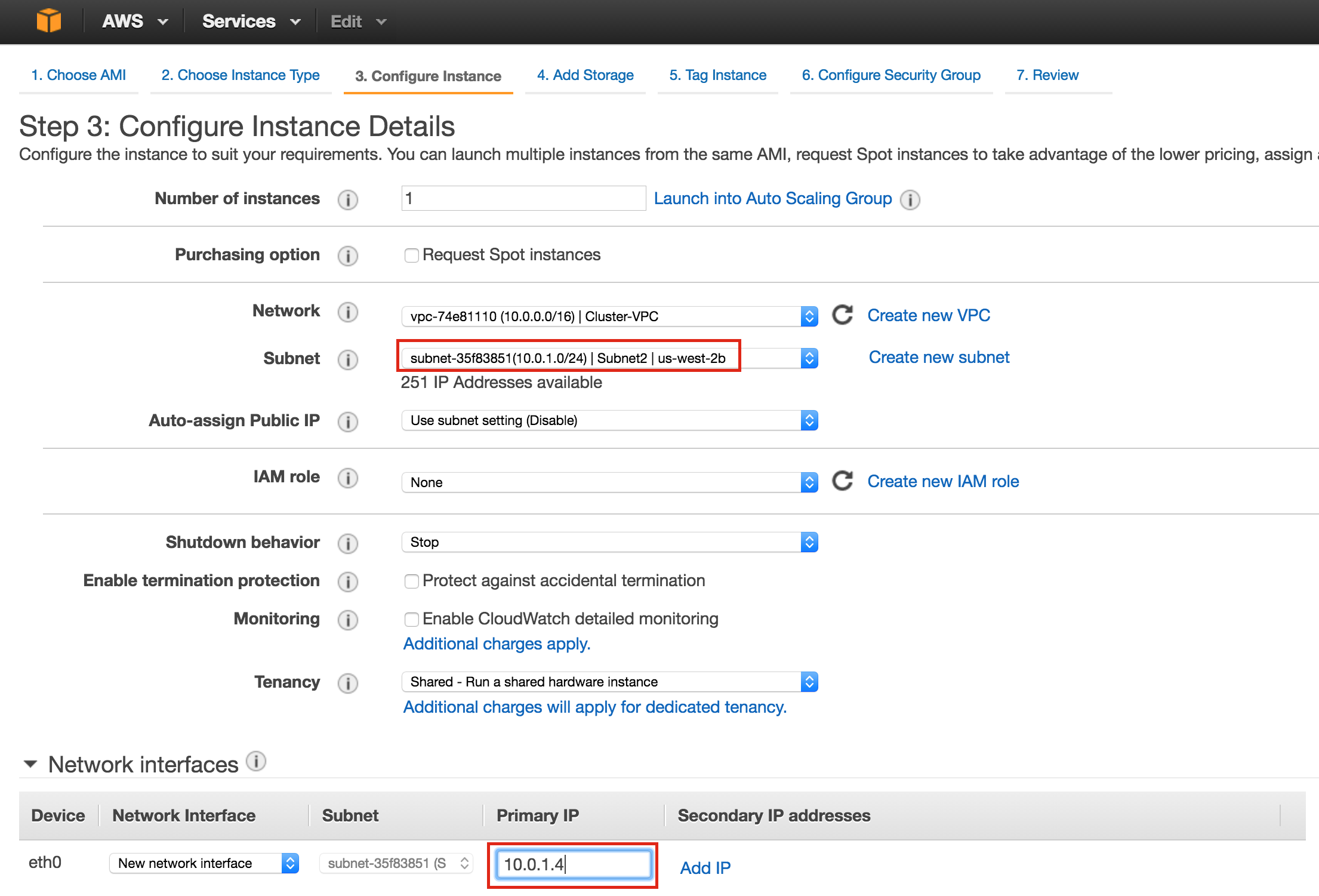
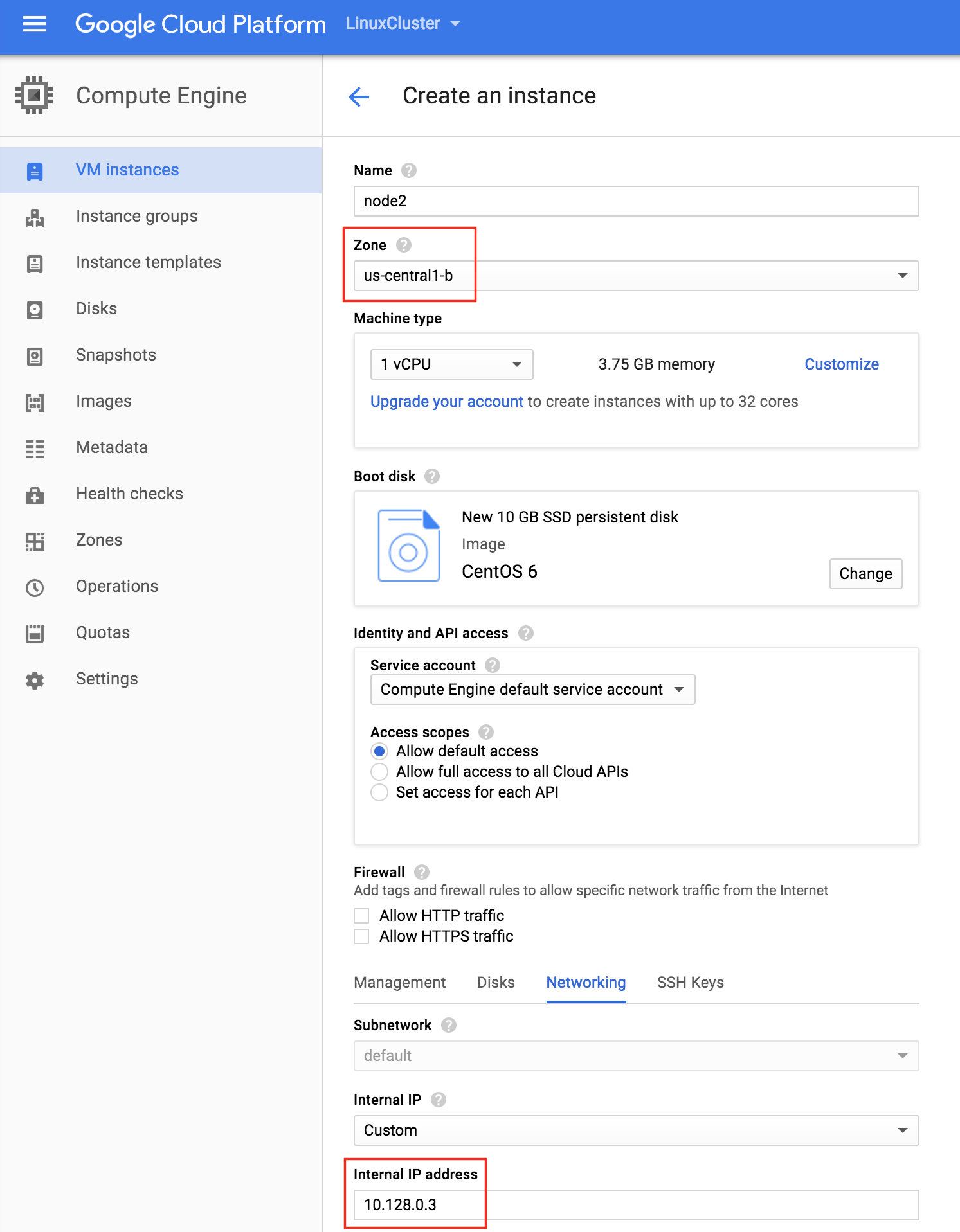
Repeat the steps above twice to create your second cluster node (“node2”). Create this instance just like you did node1, including the addition of the 2nd disk.
IMPORTANT: make sure it’s in a different zone (us-central1-b) and give it a unique IP (10.128.0.3)
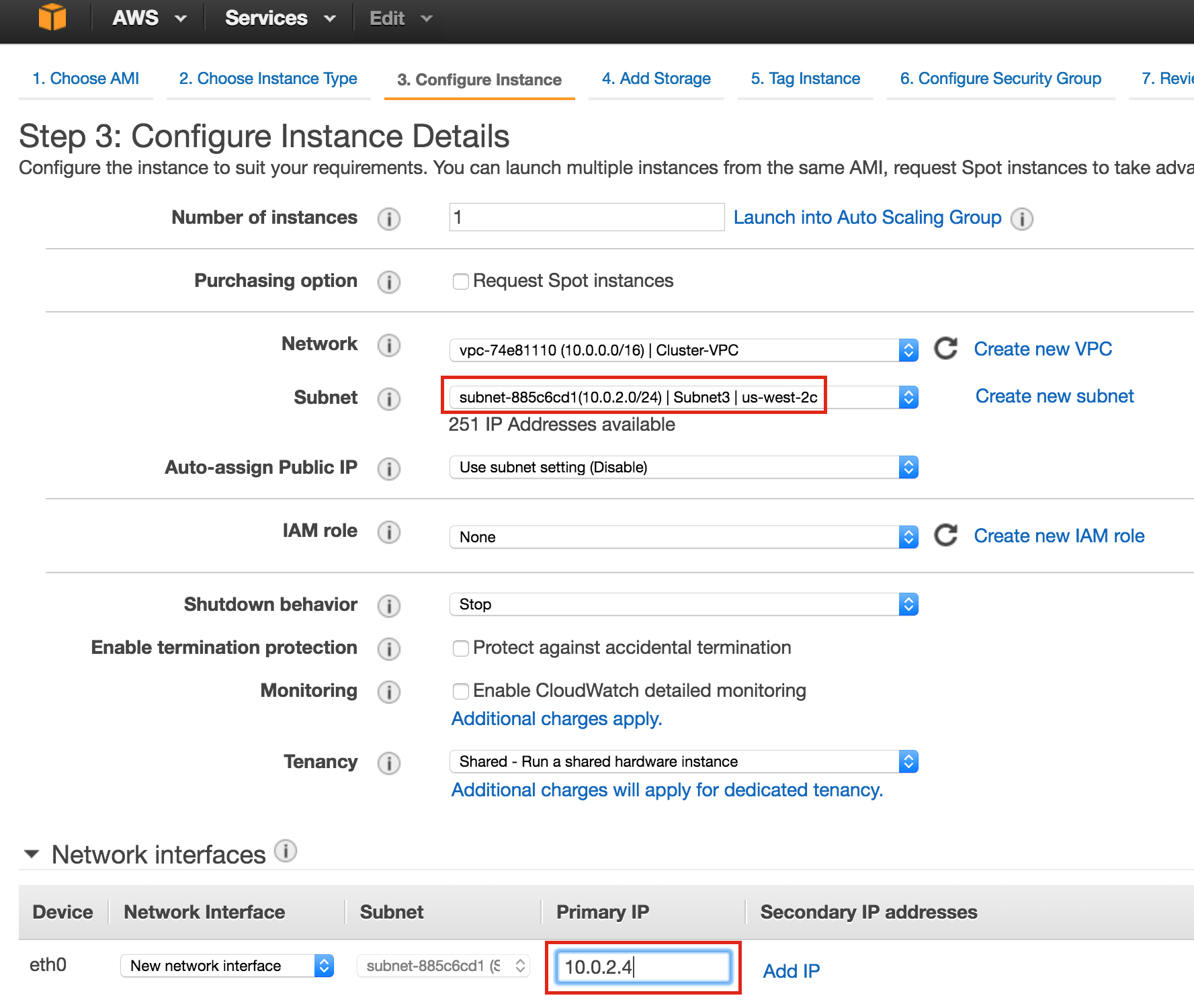
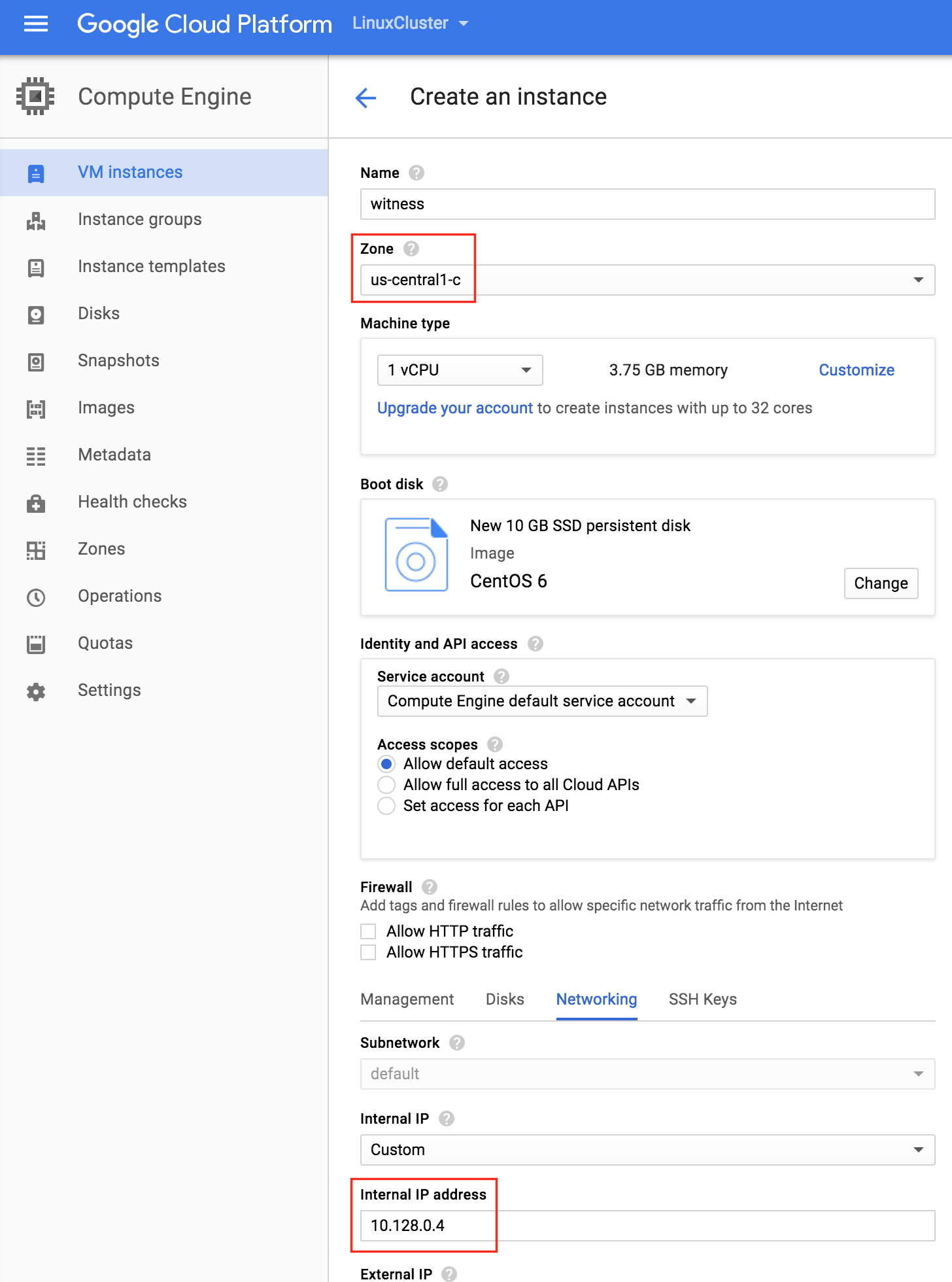
Create the “witness” VM
Create your third VM (“witness”) and make sure it’s in a different zone (us-central1-c) from the first two instances.
NOTE: This instance DOESN’T need the extra disk added.
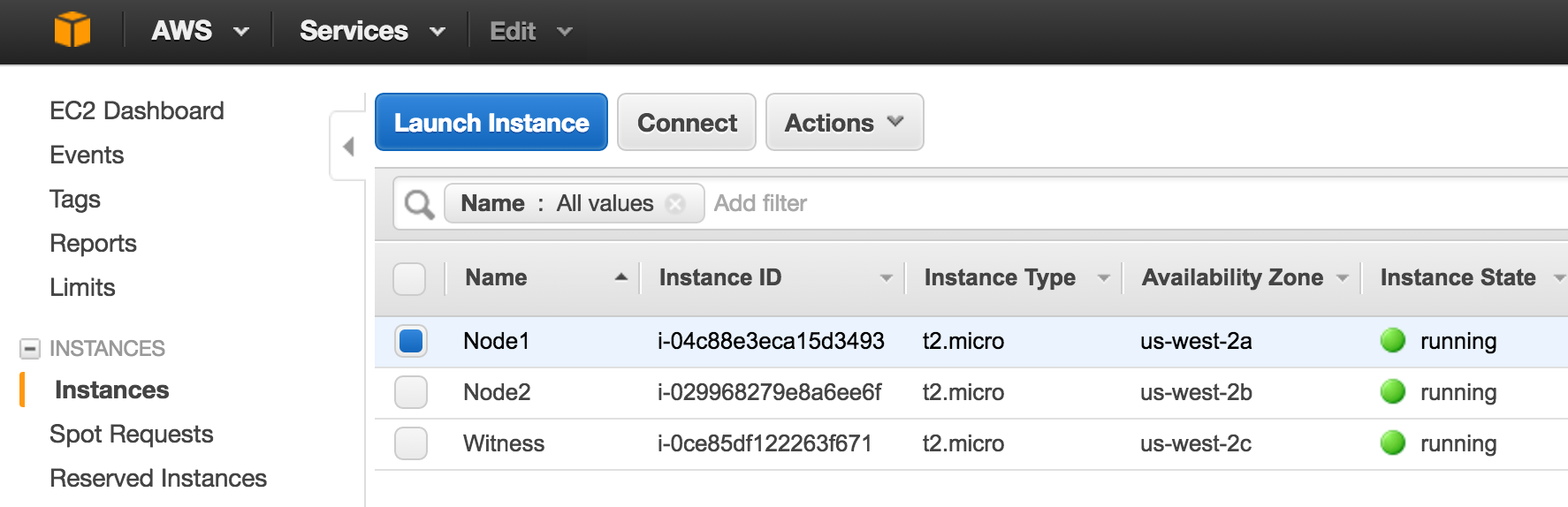
It may take a little while for your 3 VM instances to provision. Once complete, you’ll see your VMs listed on the VM Instances screen within your Google Cloud Console. Verify that you properly launched each VM into a different zone:
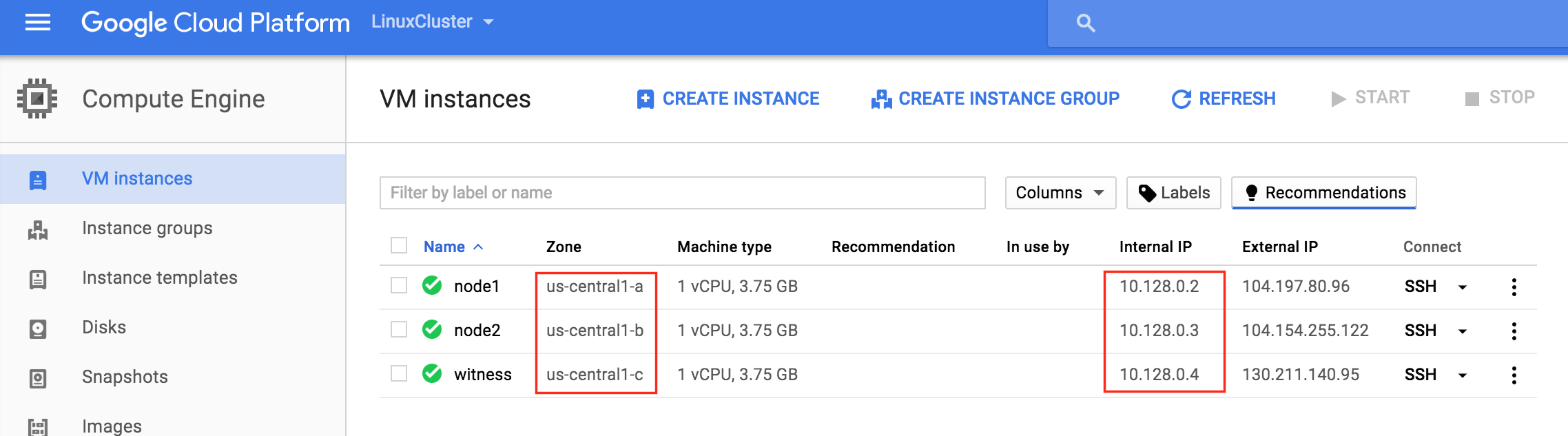
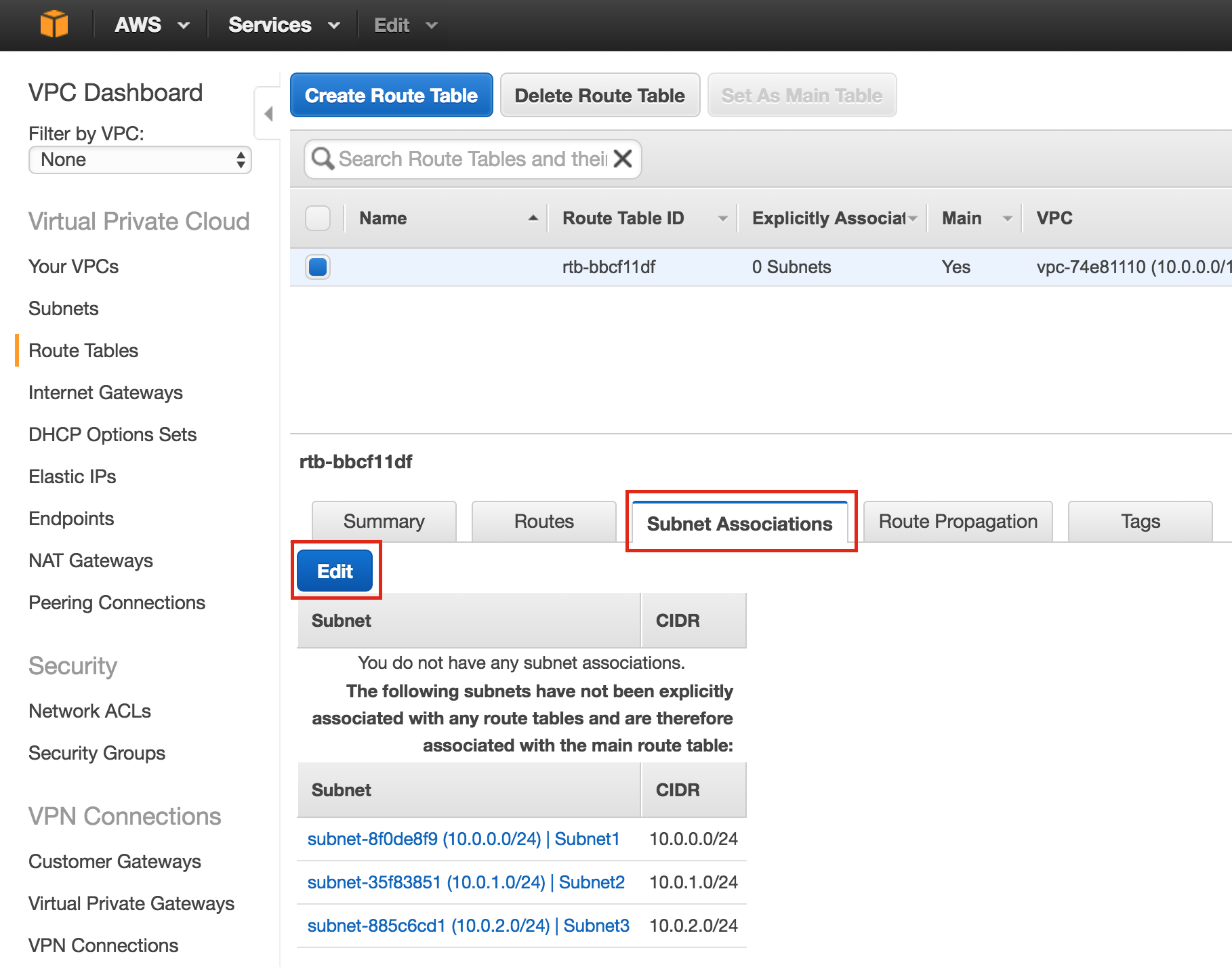
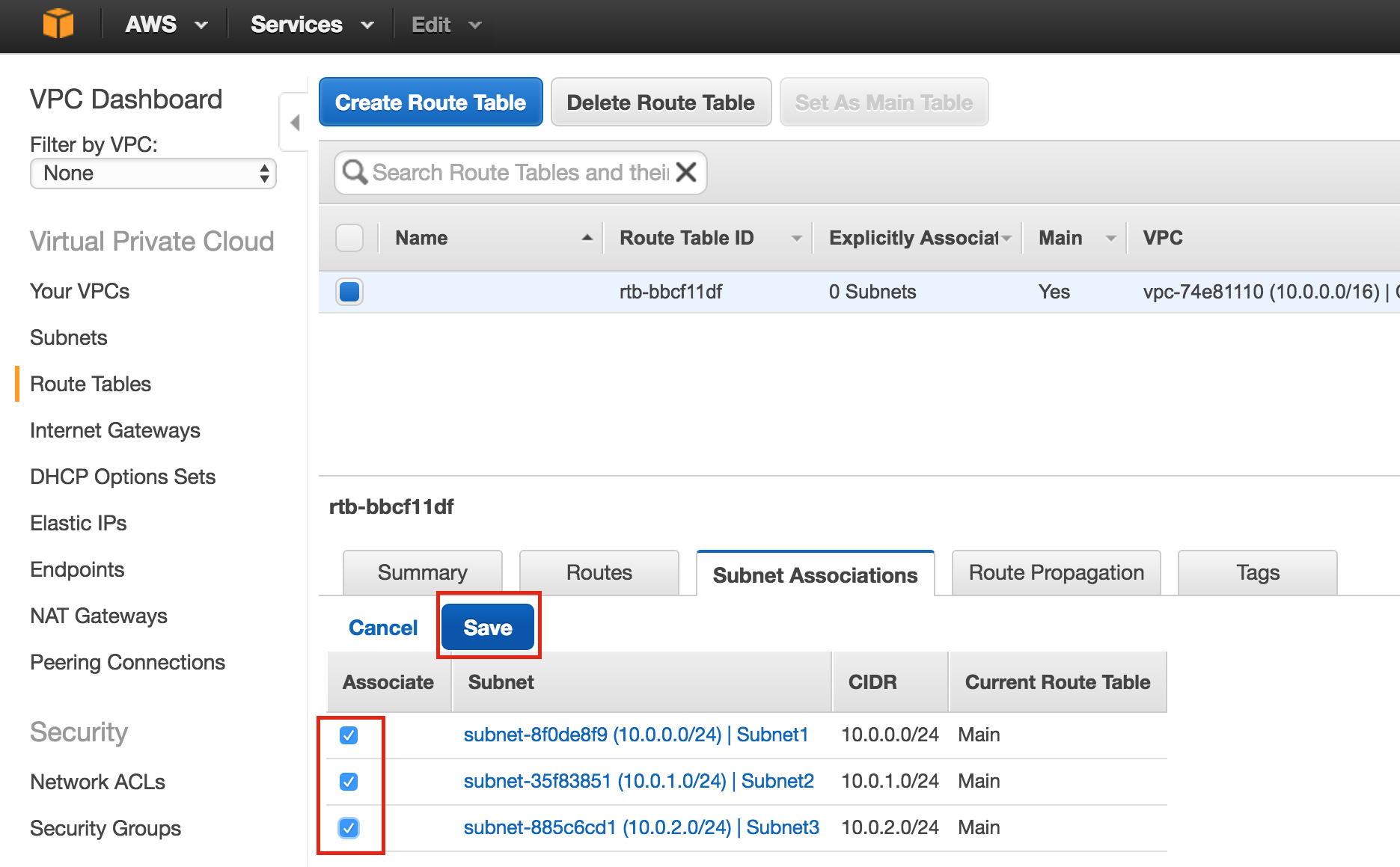
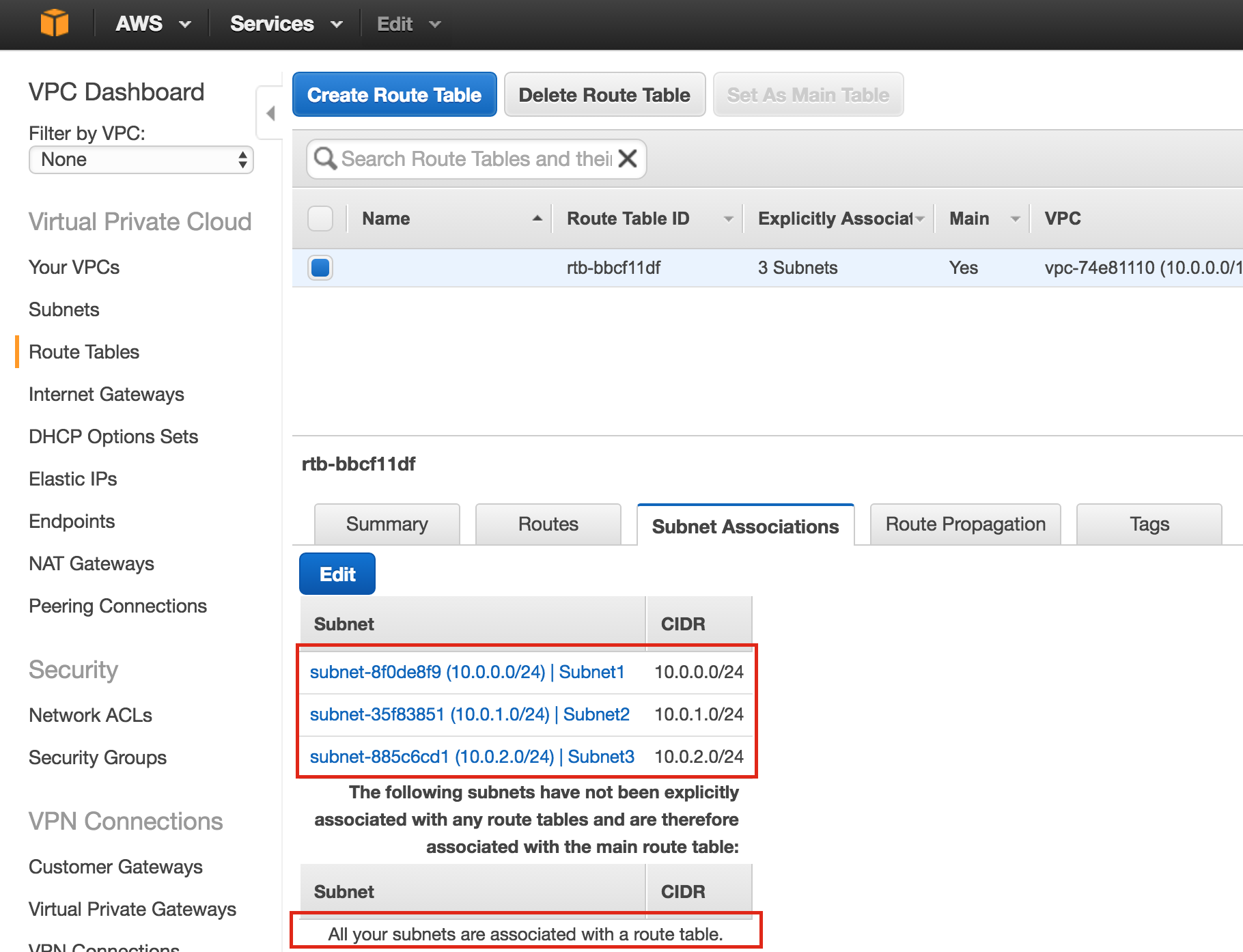
Create Instance Groups
Later in this guide we will be creating an Internal Load Balancer to route traffic to the active cluster node. All of the possible load balancer configurations available on Google Cloud Platform require instance groups to serve the traffic sent from the load balancer.
Two instance groups will be created, and each one will contain one cluster node.
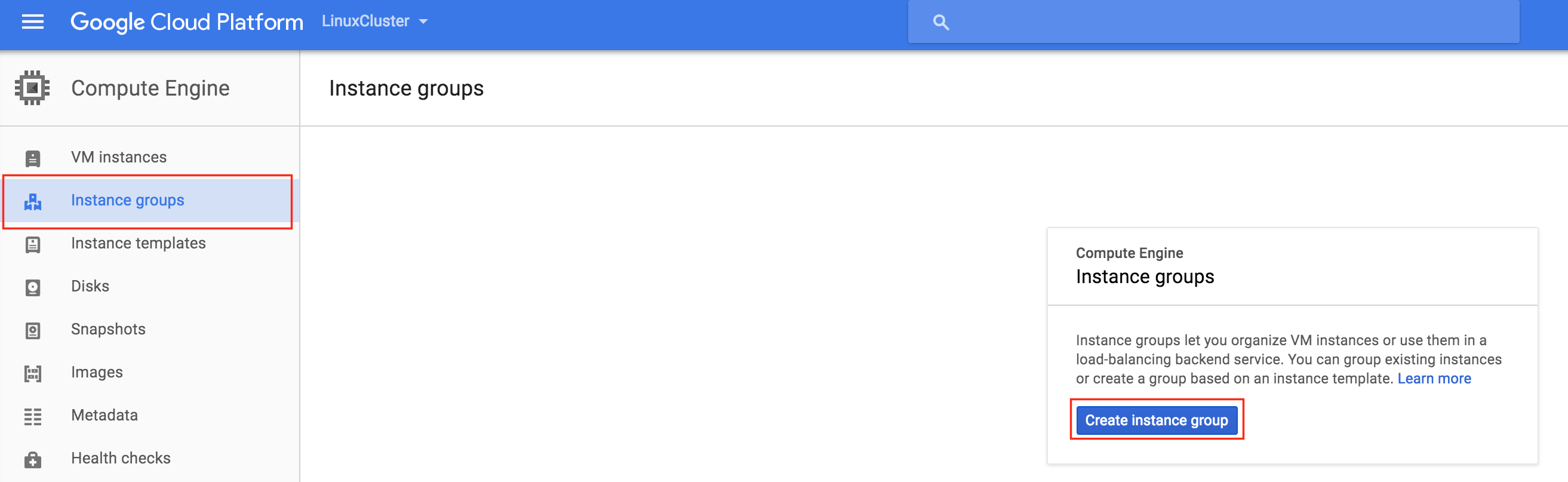
Create Instance Group 1
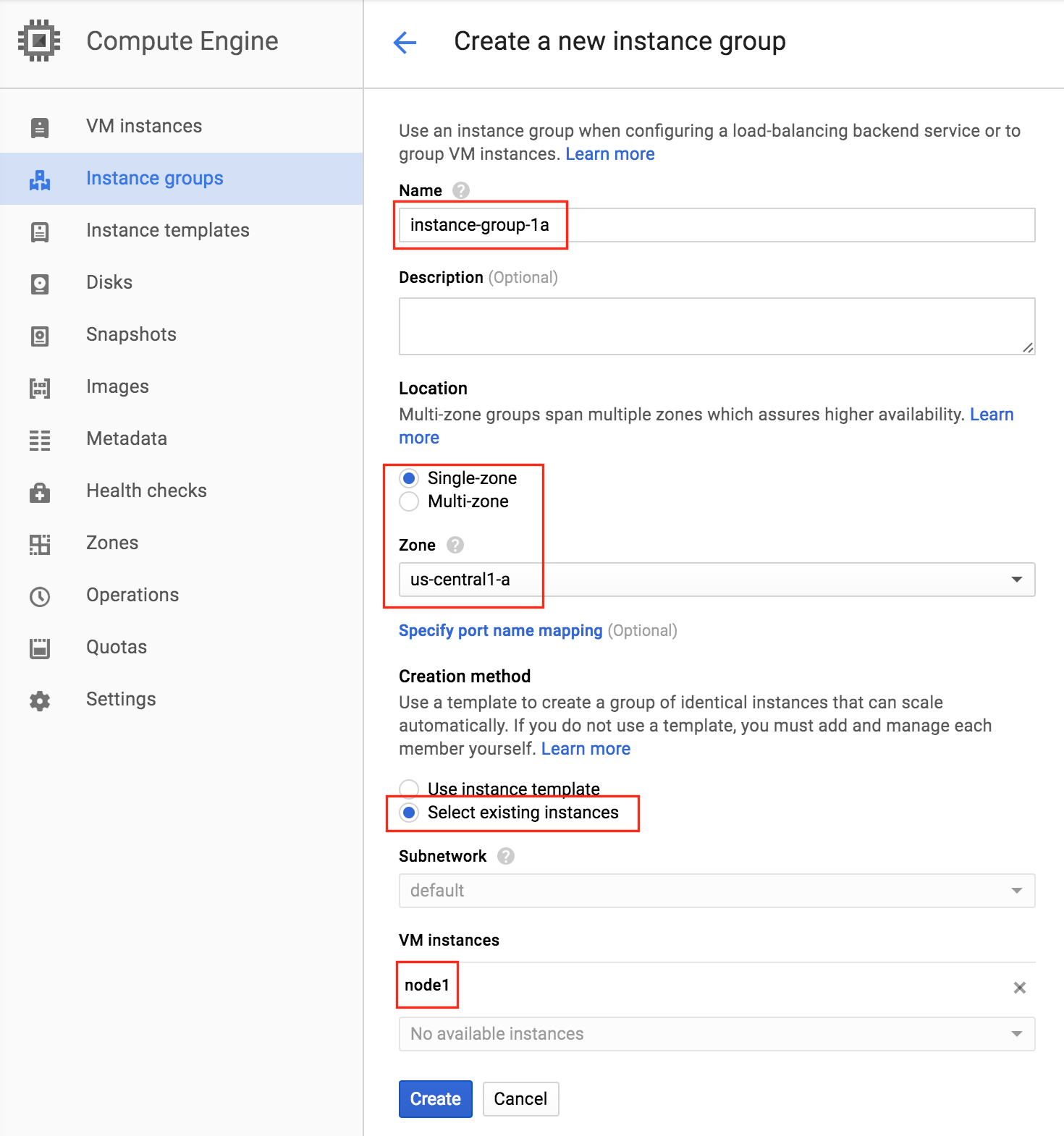
Give your first instance group a name (“instance-group-1a”), select “Single-zone” and make sure to properly select the Zone where your first VM instance resides. Here, we select us-central-1a, because that is where “node1” was deployed. Below, choose “Select existing instances” and pick “node1” from the VM instances drop down:
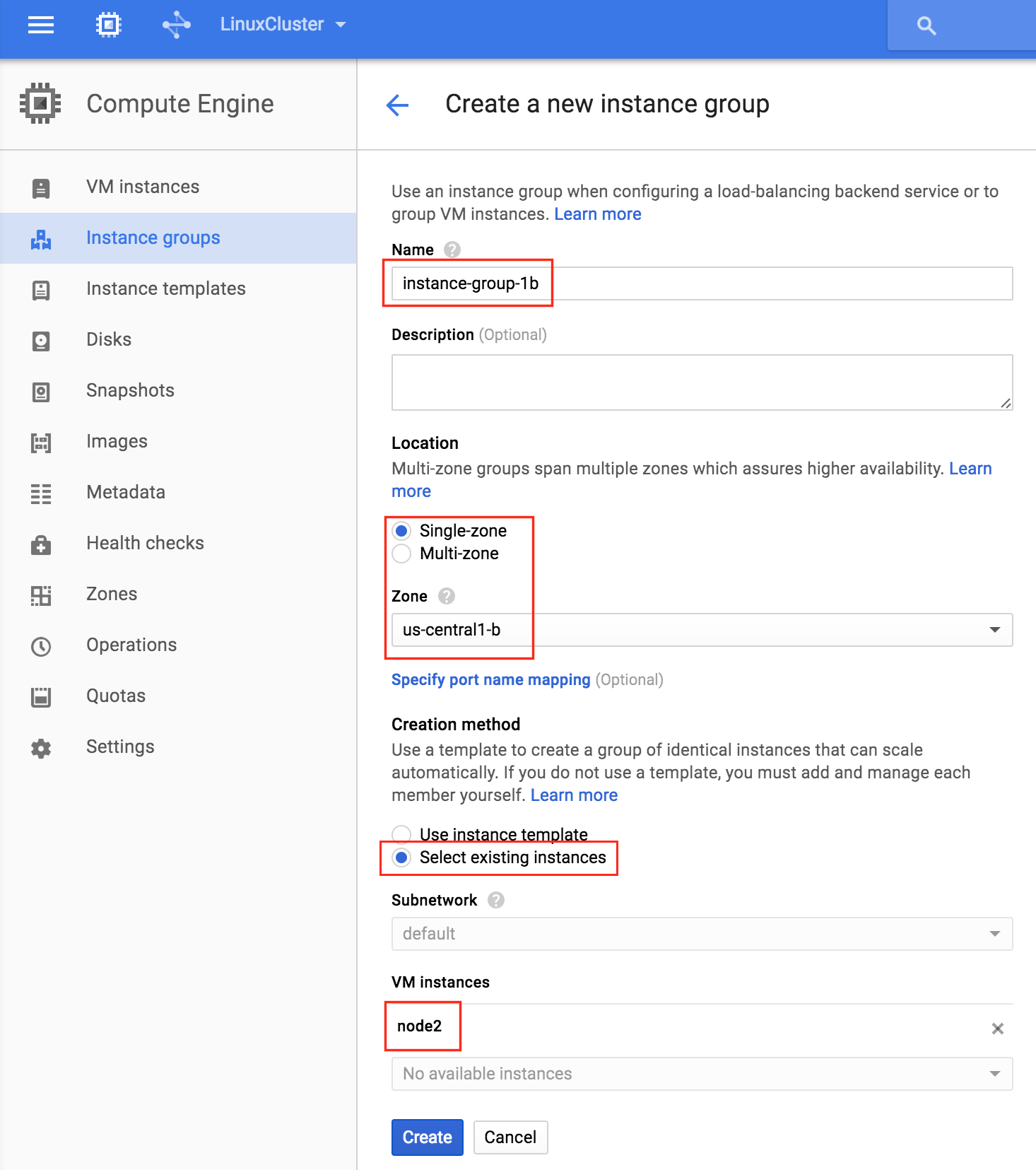
Create Instance Group 2
Repeat the previous step once more, this time selecting the zone your second node resides in. us-central-1b and node2:
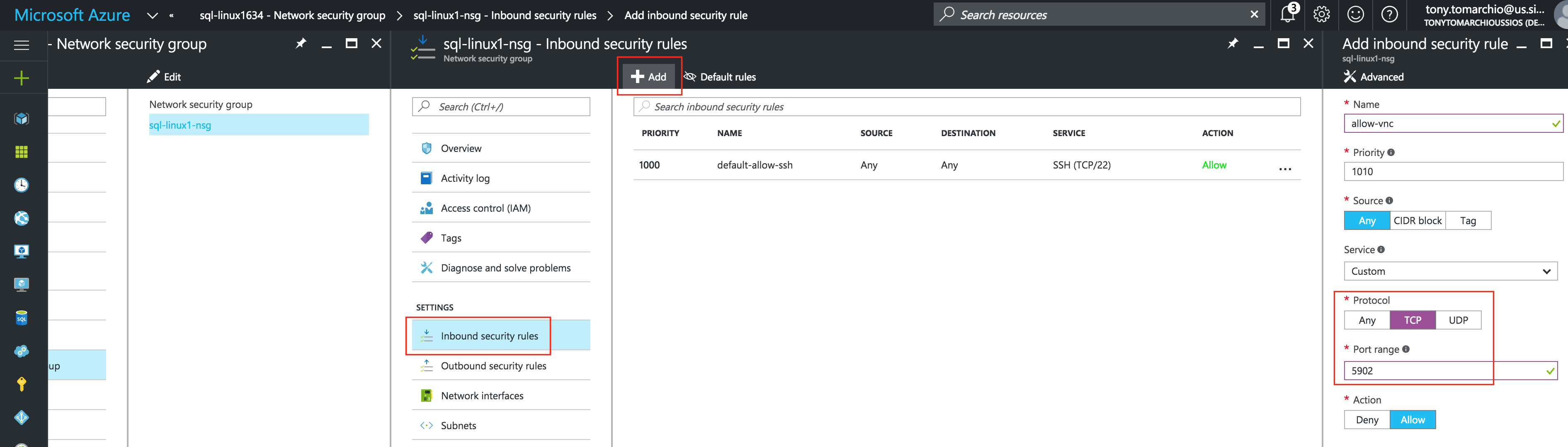
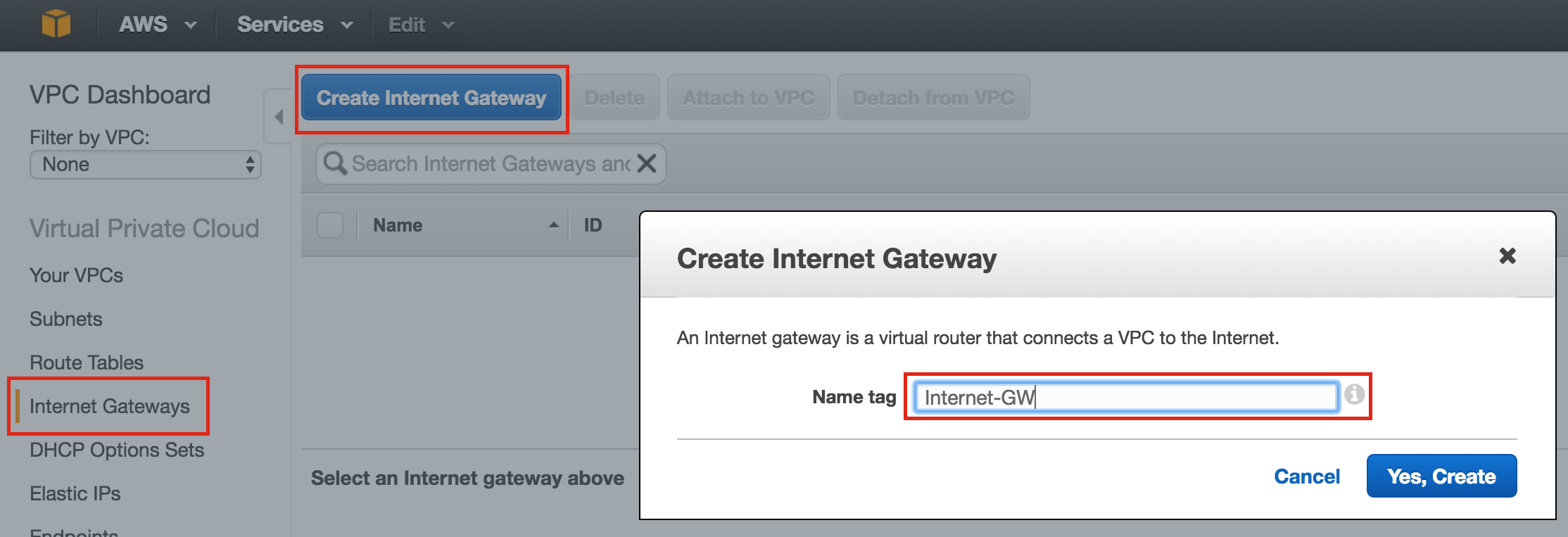
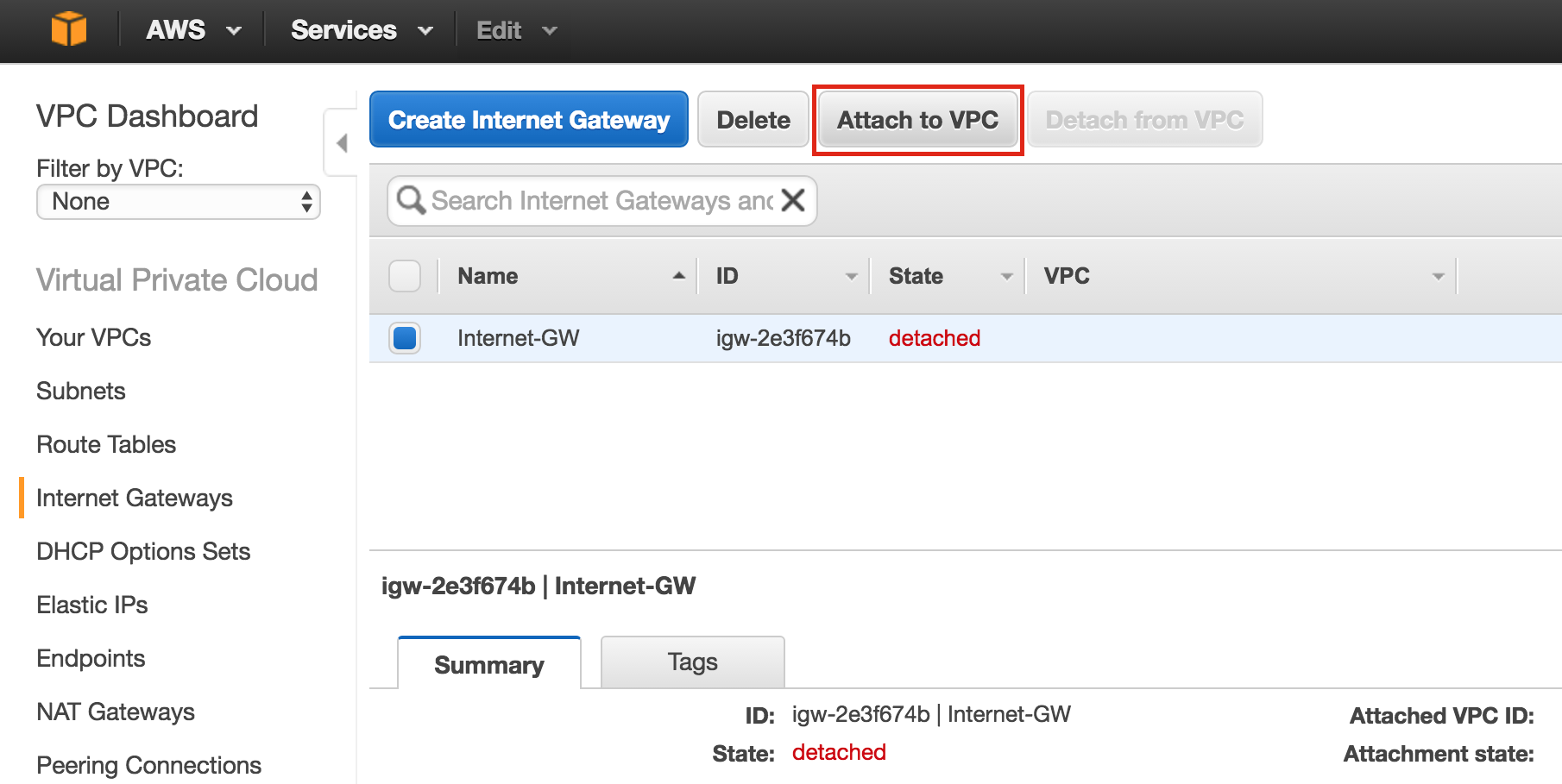
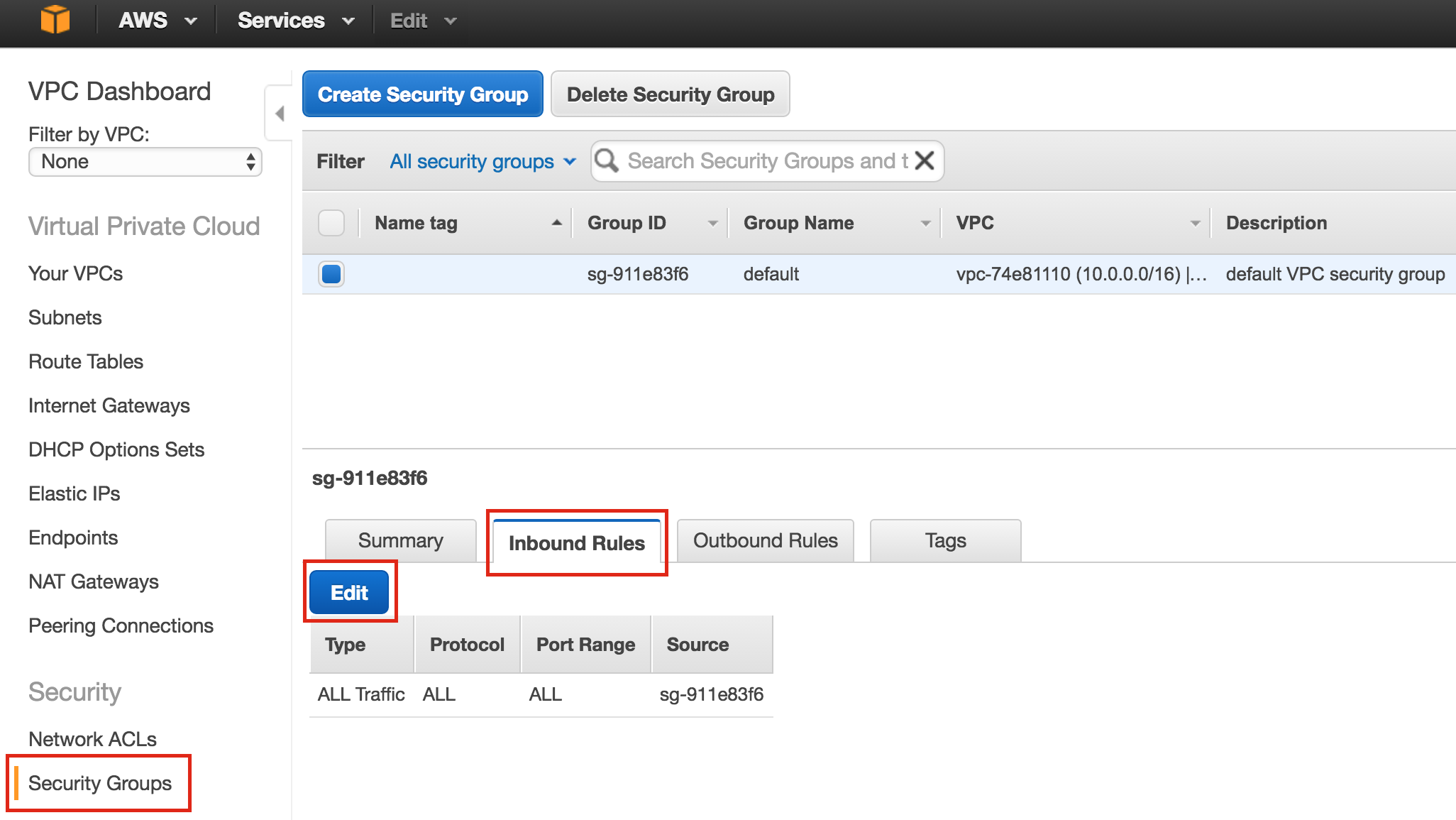
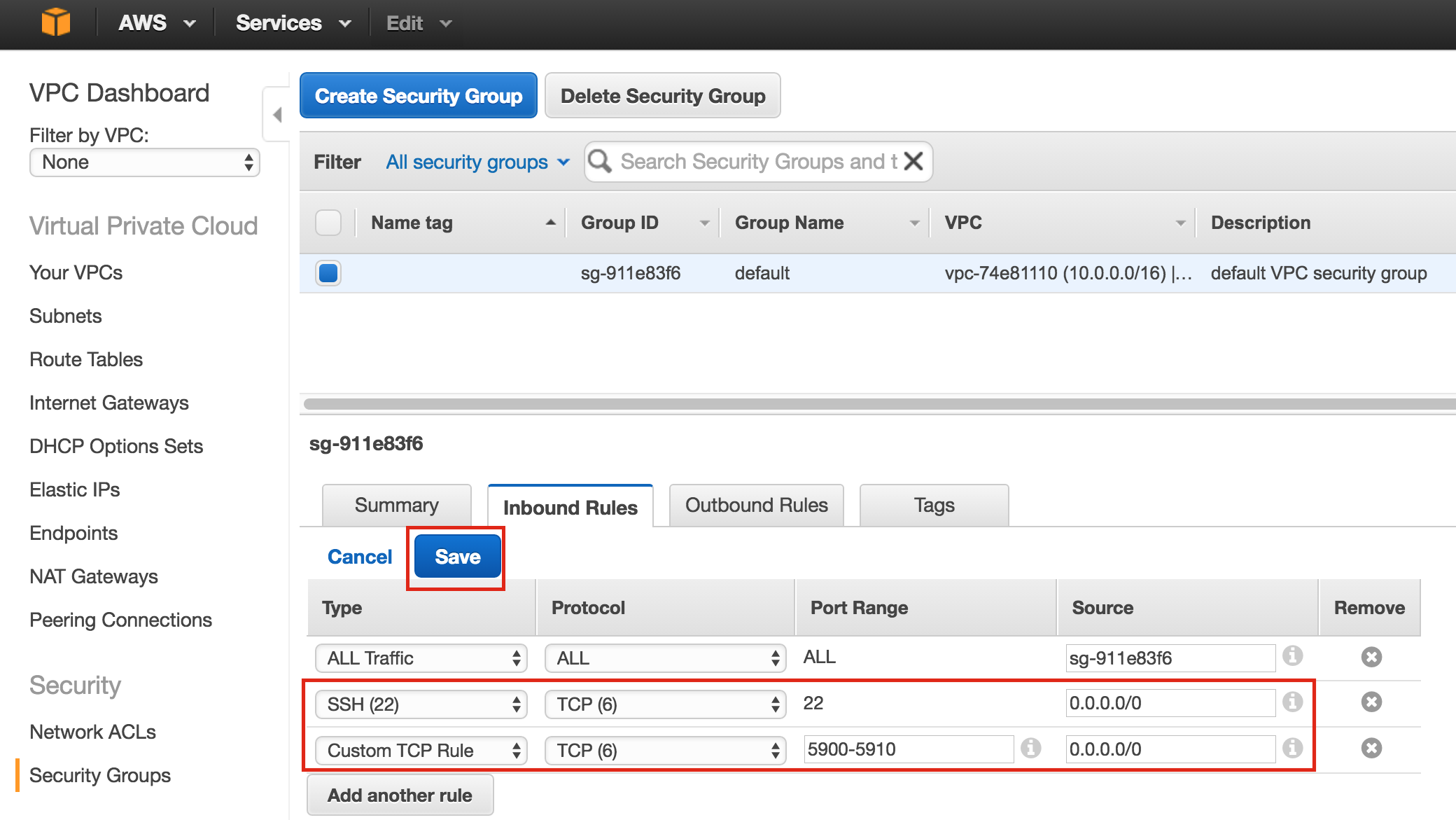
Create Firewall Rule to allow VNC access
You can see all of your existing firewall rules by navigating to:
Networking -> Firewall Rules
By default, the only ports open in the “Google firewall” from the outside world into your VMs are are ping, SSH (port 22) and RDP (port 3389).
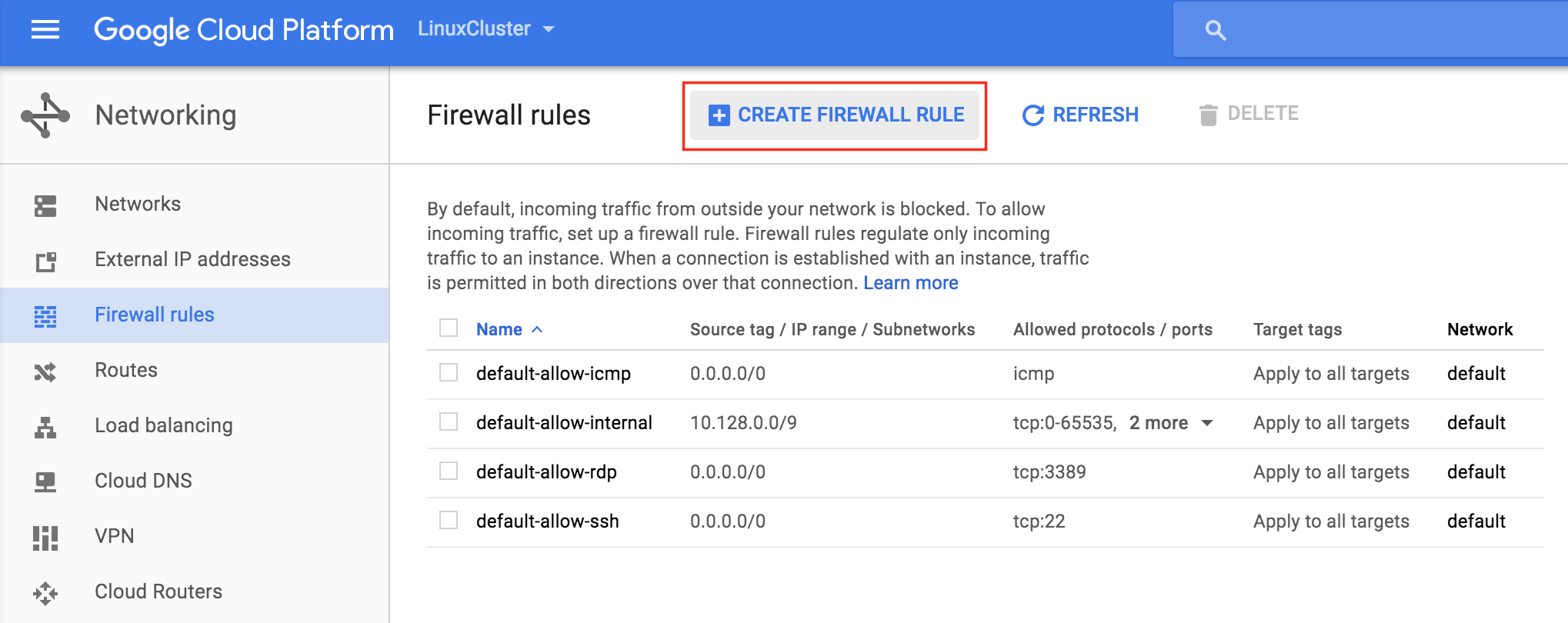
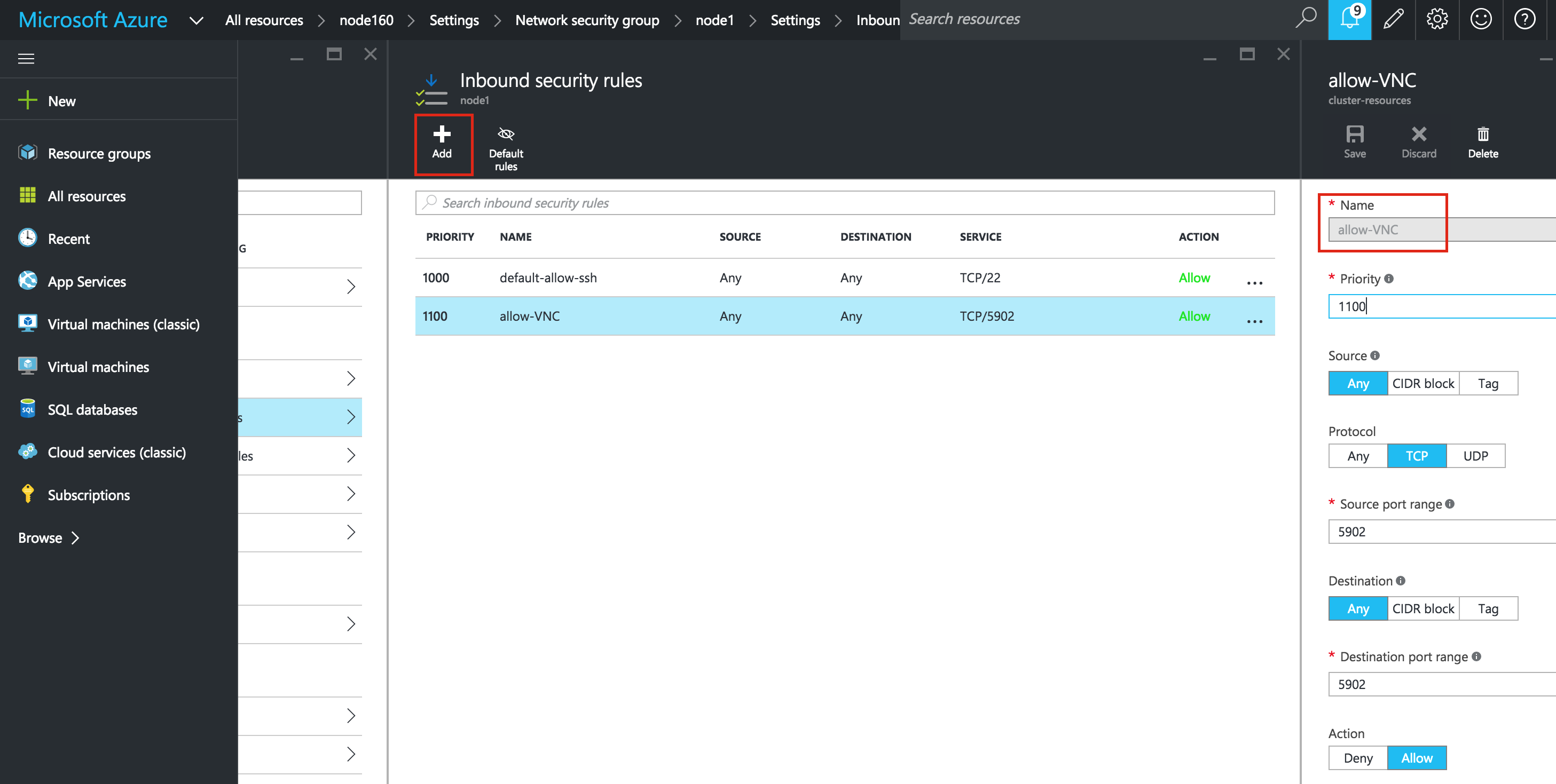
Later in the guide, we’ll be using VNC to access the desktop of “node1” and configure the cluster using a GUI. Create an Firewall Rule to allow VNC access. In this guide port 5902 is used. Adjust this according based on your VNC configuration.
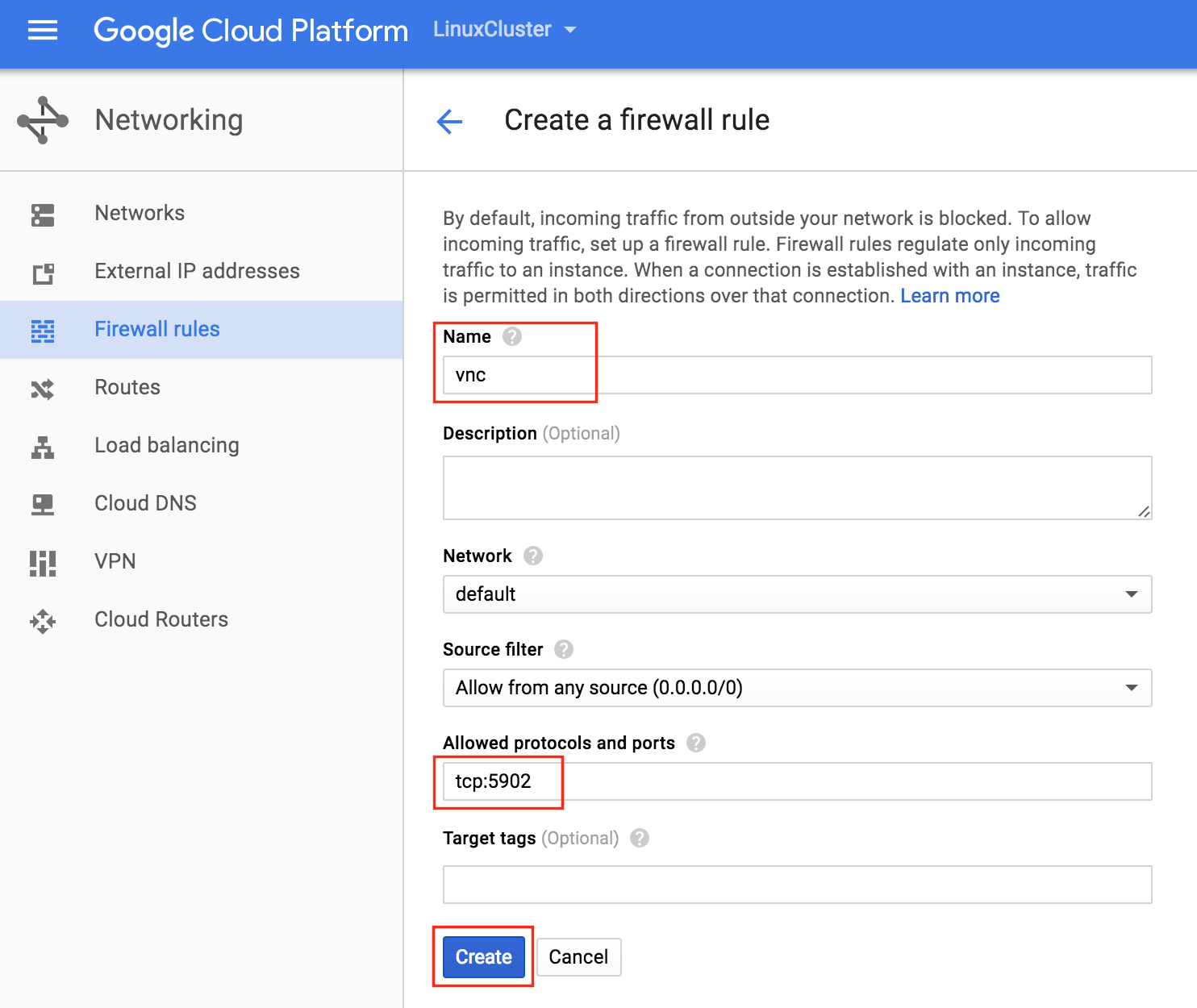
Linux OS Configuration
Next, we will need to configure the Linux OS of our instances and get our hands dirty on the command line, which as a Linux administrator you should be used to by now.
There are a number of ways to connect to the console of your linux VMs. You can initiate an SSH connection directly from the GCE web interface, or you can install the Google Cloud SDK locally on your laptop/workstation.
To SSH using your browser, simple go to Compute -> VM Instances and to the right of the VM you wish to connect to, under “Connect” select “Open in browser window”.
If you would prefer to have the Google Cloud command line tools installed natively on your laptop/workstation, please see the documentation here:
https://cloud.google.com/sdk/docs/quickstarts
Once connected use the “sudo” command to gain root privileges:
$sudo su -
Edit /etc/hosts
Unless you have already have a DNS server setup, you’ll want to create host file entries on all 3 servers so that they can properly resolve each other by name
Add the following lines to the end of your /etc/hosts file:
10.128.0.2 node1 10.128.0.3 node2 10.128.0.4 witness 10.128.0.99 mysql-vip
Disable SELinux
Edit /etc/sysconfig/linux and set “SELINUX=disabled”:
# vi /etc/sysconfig/selinux # This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of these two values: # targeted - Targeted processes are protected, # mls - Multi Level Security protection. SELINUXTYPE=targeted
Install various RPM packages
Next, install a handful of rpm packages that will be needed later as pre-requisites for our clustering software:
# yum install redhat-lsb patch
Install and Configure VNC (and related packages)
In order to access the GUI of our linux servers, to later configure our cluster, install VNC server on your cluster node. In my setup I only did this on “node1”
# yum install tigervnc-server xterm
# vncpasswd
# vi /etc/sysconfig/vncservers
VNCSERVERS="2:root"
VNCSERVERARGS[2]="-geometry 1024x768"
# service vncserver start
# chkconfig vncserver on
Test connectivity by opening a VNC client on your laptop/desktop, and connecting to the Public IP of your cluster node
Reboot Cluster Nodes
Reboot so that SELinux is disabled. All 3 systems (node1, node2, witness) need to be rebooted.
Partition and Format the “data” disk
During VM instance creation, an extra disk was added to each cluster node to store the application data we will be protecting. In this case it happens to be MySQL databases.
The disk configuration of our VMs is as follows:
- /dev/sda – OS disk
- /dev/sdb – data disk
The 2nd disk added during instance creation /dev/sdb. You can run the “fdisk -l” command to verify. You’ll see that /dev/sda (OS) already has a disk partition and is being used.
# fdisk -l Disk /dev/sda: 10.7 GB, 10737418240 bytes 255 heads, 63 sectors/track, 1305 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disk identifier: 0x00035e98 Device Boot Start End Blocks Id System /dev/sda1 * 1 1306 10484736 83 Linux Disk /dev/sdb: 10.7 GB, 10737418240 bytes 64 heads, 32 sectors/track, 10240 cylinders Units = cylinders of 2048 * 512 = 1048576 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disk identifier: 0x762b810b
Here we will create a partition (/dev/sdb1), format it, and mount it at the default location for MySQL, which is /var/lib/mysql. Perform the following steps on BOTH “node1” and “node2”:
# fdisk /dev/sdb
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-1305, default 1): <enter>
Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-1305, default 1305): <enter>
Using default value 1305
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
[root@node1 ~]#
# mkfs.ext4 /dev/sdb1
# mkdir /var/lib/mysql
On node1, mount the filesystem:
# mount /dev/sdb1 /var/lib/mysql
Install and Configure MySQL
Next, install install the MySQL packages, initialize a sample database, and set “root” password for MySQL.
On “node1”:
# yum -y install mysql mysql-server
# /usr/bin/mysql_install_db --datadir="/var/lib/mysql/" --user=mysql
# mysqld_safe --user=root --socket=/var/lib/mysql/mysql.sock --port=3306 --datadir=/var/lib/mysql --log &
#
# # NOTE: This next command allows remote connections from ANY host. NOT a good idea for production!
# echo "update user set Host='%' where Host='node1'; flush privileges" | mysql mysql
#
# #Set MySQL's root password to 'SIOS'
# echo "update user set Password=PASSWORD('SIOS') where User='root'; flush privileges" | mysql mysql
Create a MySQL configuration file. We will place this on the data disk (that will later be replicated – /var/lib/mysql/my.cnf). Example:
# vi /var/lib/mysql/my.cnf [mysqld] datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock pid-file=/var/lib/mysql/mysqld.pid user=root port=3306 # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 [mysqld_safe] log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid [client] user=root password=SIOS
Delete the original MySQL configuration file, located in /etc, if it exists:
# rm /etc/my.cnf
On “node2”:
On “node2”, you ONLY need to install the MySQL packages. The other steps aren’t required:
[root@node2 ~]# yum -y install mysql mysql-server
Install and Configure the Cluster
At this point, we are ready to install and configure our cluster. SIOS Protection Suite for Linux (aka SPS-Linux) will be used in this guide as the clustering technology. It provides both high availability failover clustering features (LifeKeeper) as well as real-time, block level data replication (DataKeeper) in a single, integrated solution. SPS-Linux enables you to deploy a “SANLess” cluster, aka a “shared nothing” cluster meaning that cluster nodes don’t have any shared storage, as is the case with Azure VMs.
Install SIOS Protection Suite for Linux
Perform the following steps on ALL 3 VMs (node1, node2, witness):
Download the SPS-Linux installation image file (sps.img) and and obtain either a trial license or purchase permanent licenses. Contact SIOS for more information.
You will loopback mount it and run the “setup” script inside, as root (or first “sudo su -” to obtain a root shell)
For example:
# mkdir /tmp/install # mount -o loop sps.img /tmp/install # cd /tmp/install # ./setup
During the installation script, you’ll be prompted to answer a number of questions. You will hit Enter on almost every screen to accept the default values. Note the following exceptions:
- On the screen titled “High Availability NFS” you may select “n” as we will not be creating a highly available NFS server
- Towards the end of the setup script, you can choose to install a trial license key now, or later. We will install the license key later, so you can safely select “n” at this point
- In the final screen of the “setup” select the ARKs (Application Recovery Kits, i.e. “cluster agents”) you wish to install from the list displayed on the screen.
- The ARKs are ONLY required on “node1” and “node2”. You do not need to install on “witness”
- Navigate the list with the up/down arrows, and press SPACEBAR to select the following:
- lkDR – DataKeeper for Linux
- lkSQL – LifeKeeper MySQL RDBMS Recovery Kit
- This will result in the following additional RPMs installed on “node1” and “node2”:
- steeleye-lkDR-9.0.2-6513.noarch.rpm
- steeleye-lkSQL-9.0.2-6513.noarch.rpm
Install Witness/Quorum package
The Quorum/Witness Server Support Package for LifeKeeper (steeleye-lkQWK) combined with the existing failover process of the LifeKeeper core allows system failover to occur with a greater degree of confidence in situations where total network failure could be common. This effectively means that failovers can be done while greatly reducing the risk of “split-brain” situations.
Install the Witness/Quorum rpm on all 3 nodes (node1, node2, witness):
# cd /tmp/install/quorum # rpm -Uvh steeleye-lkQWK-9.0.2-6513.noarch.rpm
On ALL 3 nodes (node1, node2, witness), edit /etc/default/LifeKeeper, set
NOBCASTPING=1
On ONLY the Witness server (“witness”), edit /etc/default/LifeKeeper, set
WITNESS_MODE=off/none
Install a License key
On all 3 nodes, use the “lkkeyins” command to install the license file that you obtained from SIOS:
# /opt/LifeKeeper/bin/lkkeyins <path_to_file>/<filename>.lic
Start LifeKeeper
On all 3 nodes, use the “lkstart” command to start the cluster software:
# /opt/LifeKeeper/bin/lkstart
Set User Permissions for LifeKeeper GUI
On all 3 nodes, edit /etc/group and add the “tony” user (or whatever username you are logged in as) to the “lkadmin” group to grant access to the LifeKeeper GUI. By default only “root” is a member of the group, and we don’t have the root password in :
# vi /etc/group lkadmin:x:502:root,tony
Open the LifeKeeper GUI
Make a VNC connection to the Public IP address of node1. Based on the VNC and Firewall Rule configuration from above, you would connect to <Public_IP>:2 using the VNC password you specified earlier. Once logged in, open a terminal window and run the LifeKeeper GUI using the following command:
# /opt/LifeKeeper/bin/lkGUIapp &
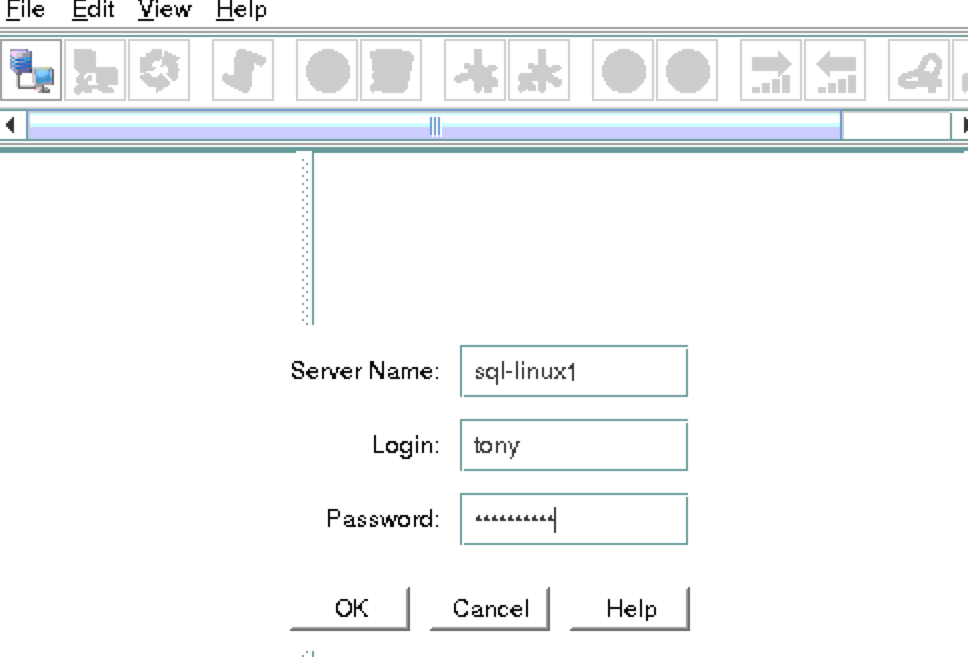
You will be prompted to connect to your first cluster node (“node1”). Enter the linux userid and password specified during VM creation:
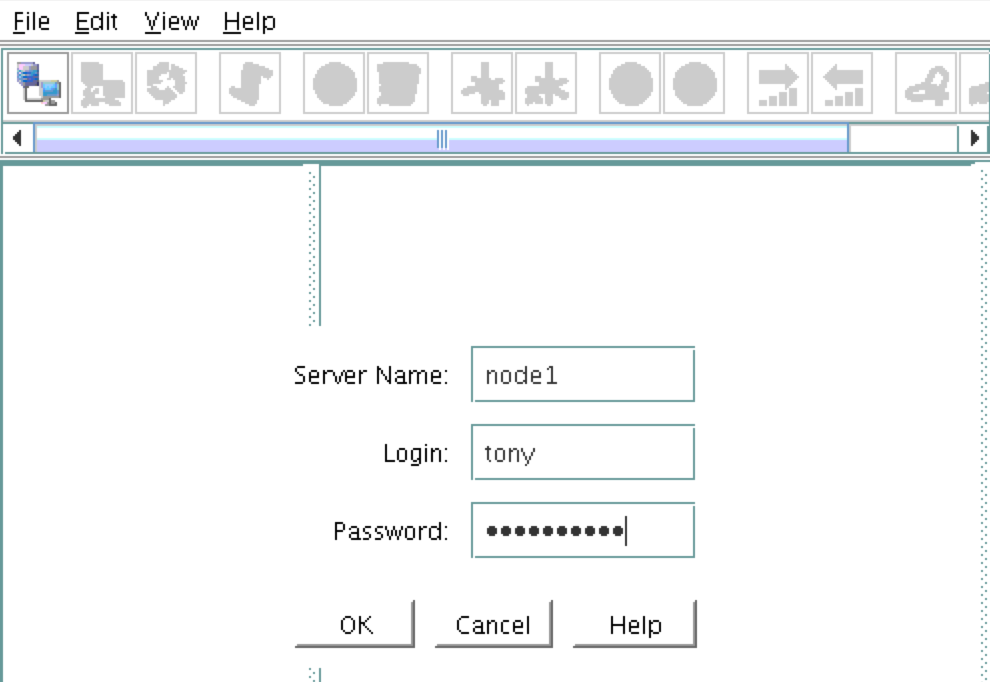
Next, connect to both “node2” and “witness” by clicking the “Connect to Server” button highlighted in the following screenshot:
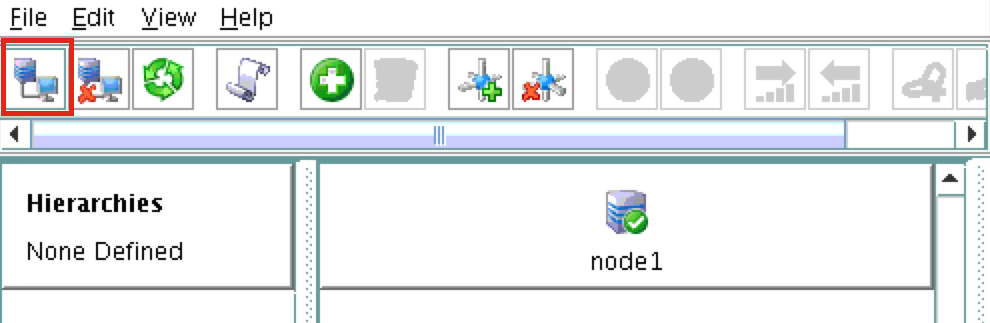
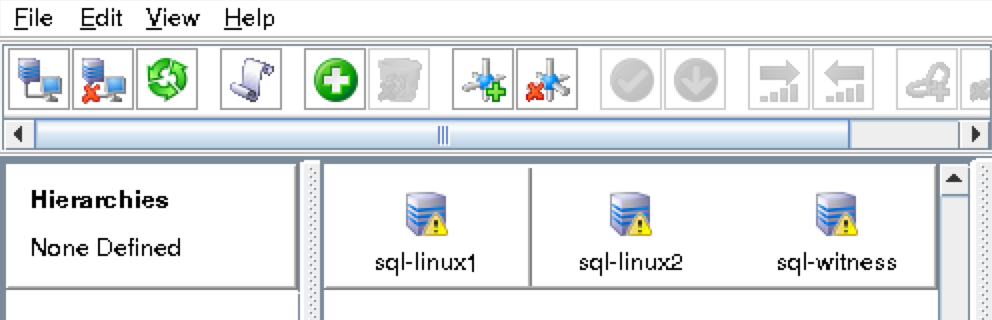
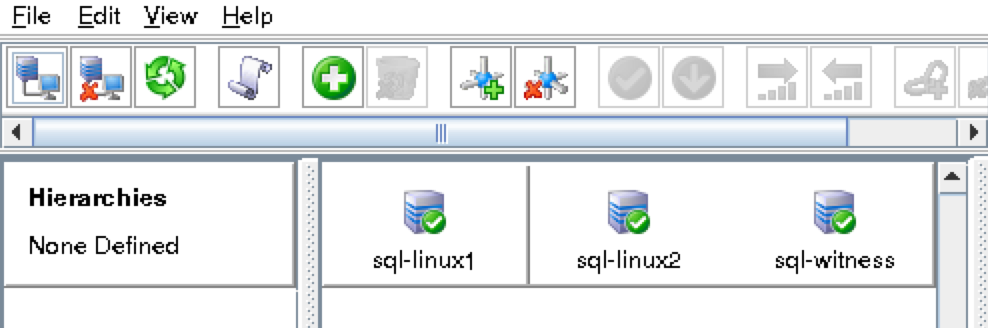
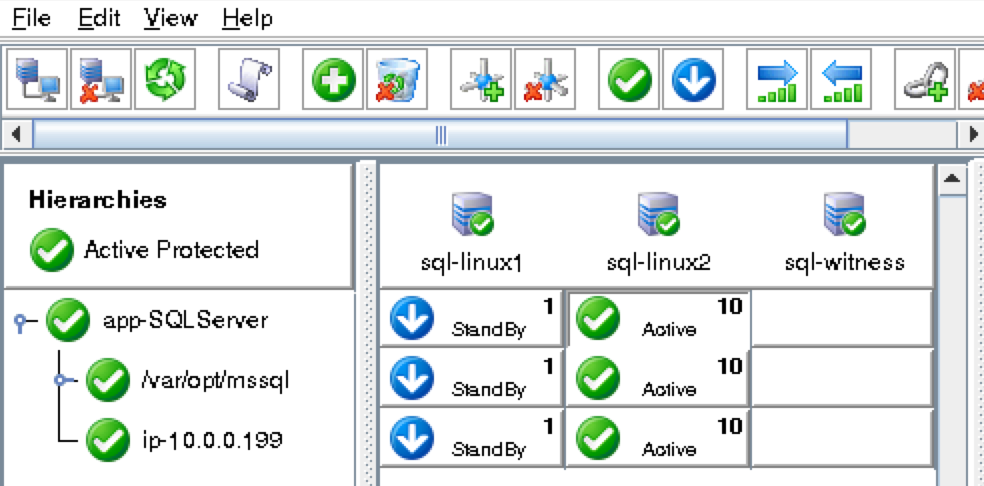
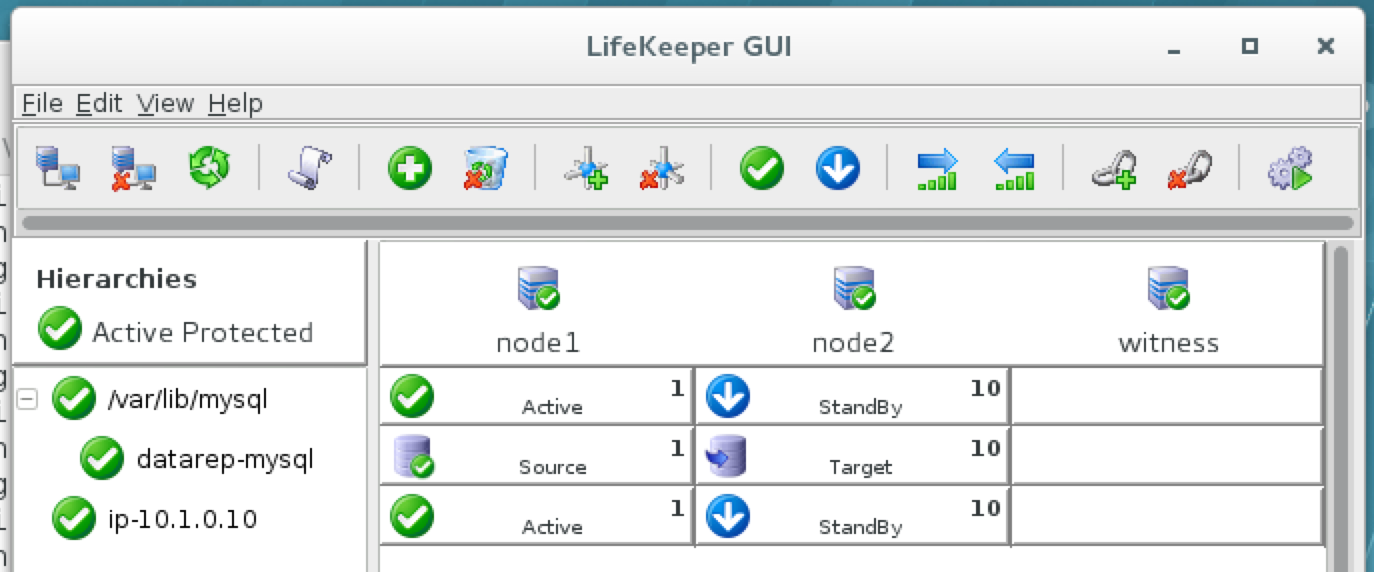
You should now see all 3 servers in the GUI, with a green checkmark icon indicating they are online and healthy:
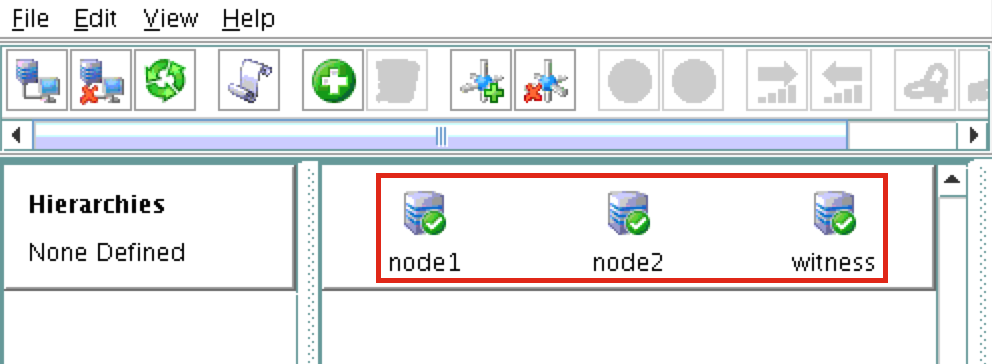
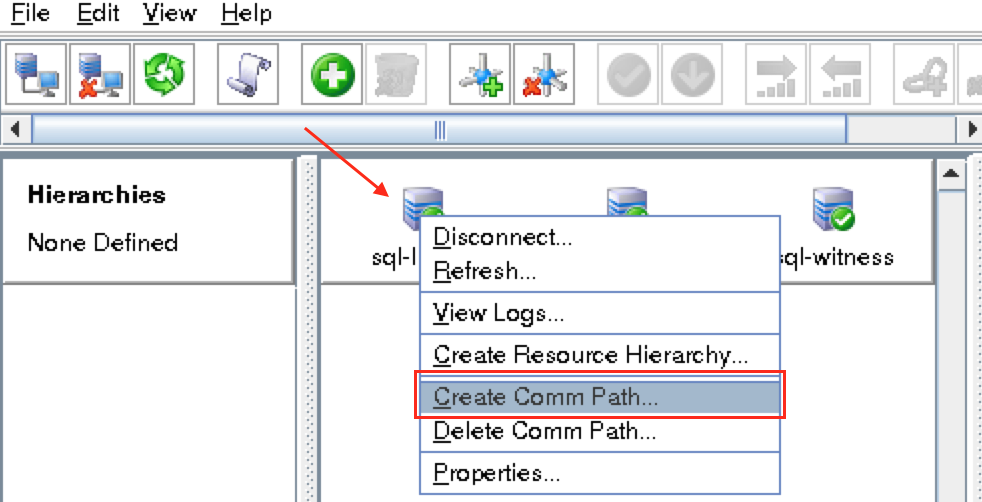
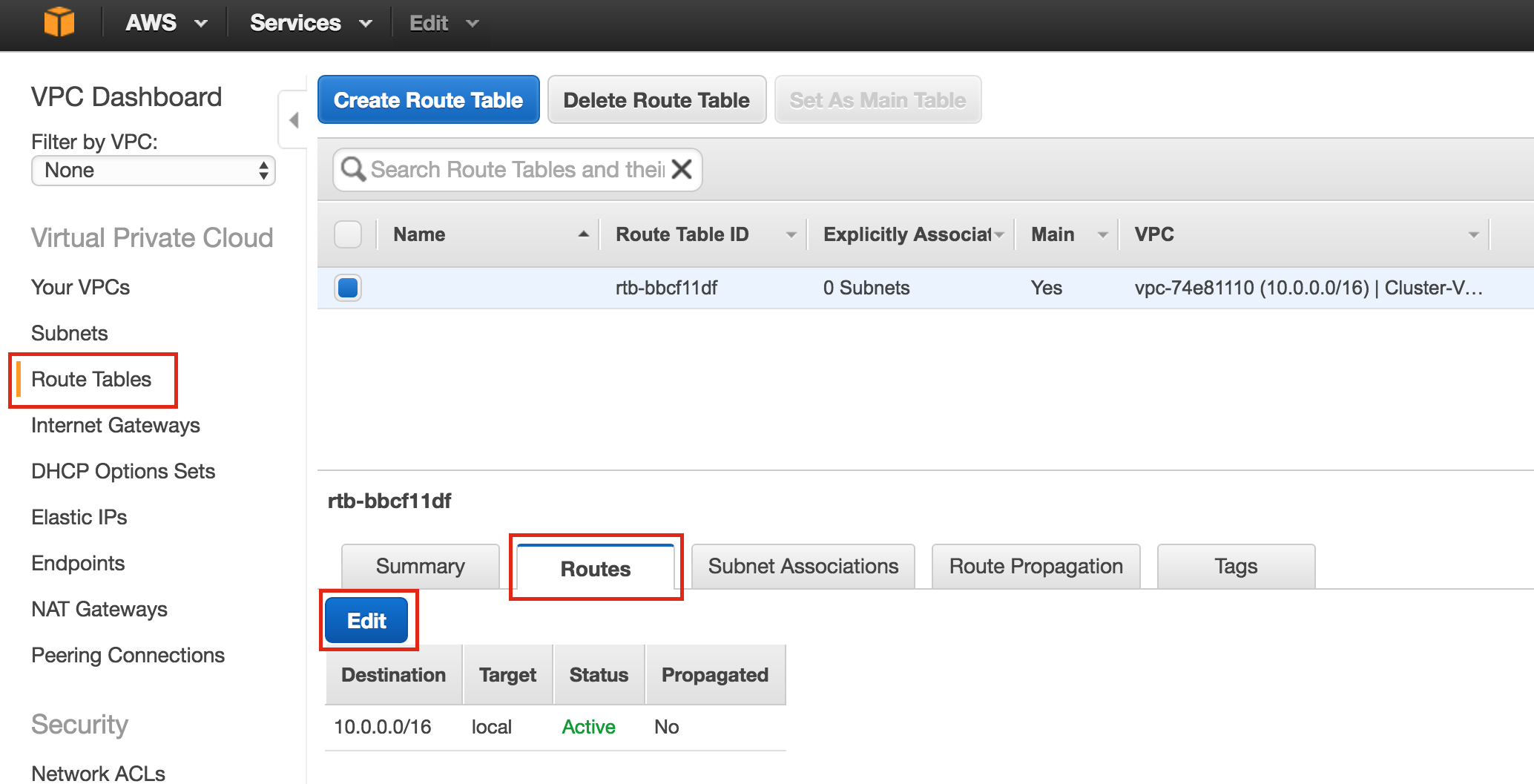
Create Communication Paths
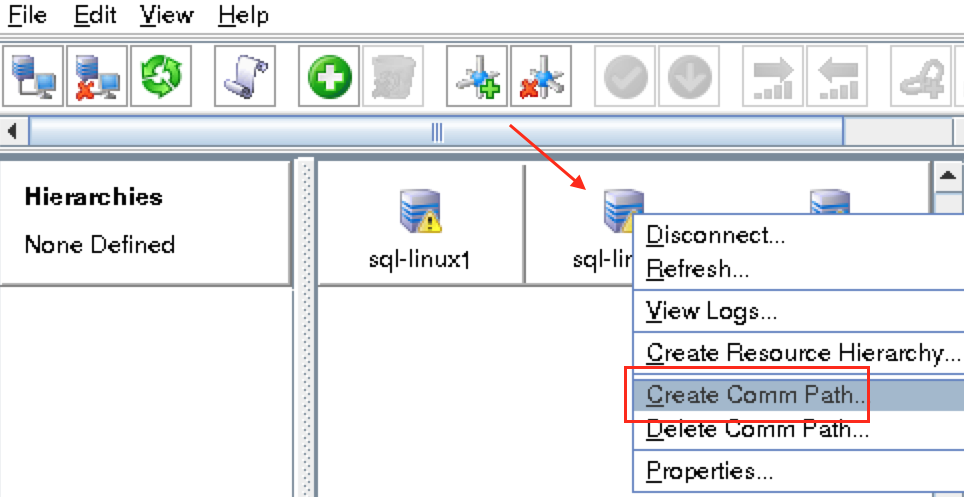
Right-click on “node1” and select Create Comm Path
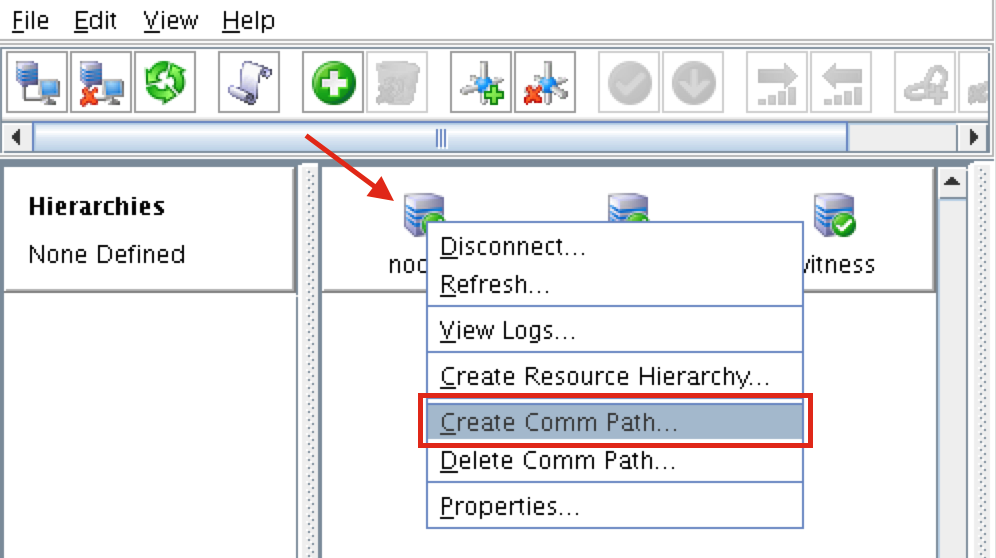
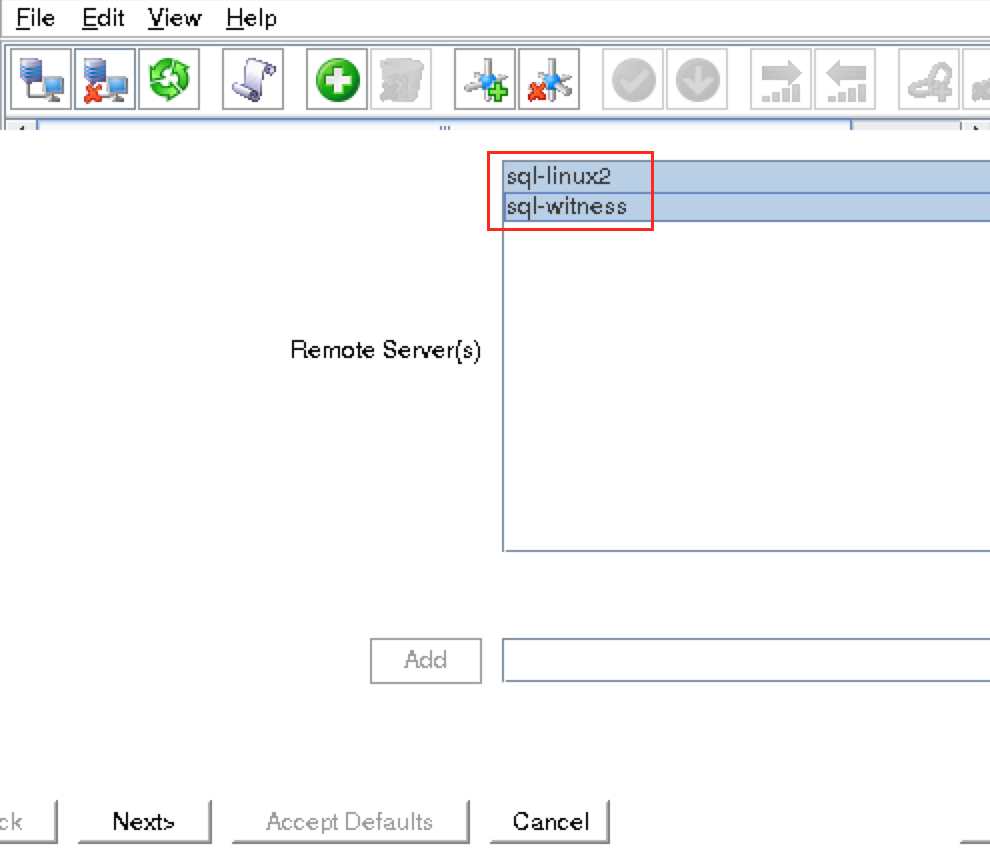
Select BOTH “node2” and “witness” and then follow the wizard. This will create comm paths between:
- node1 & node2
- node1 & witness
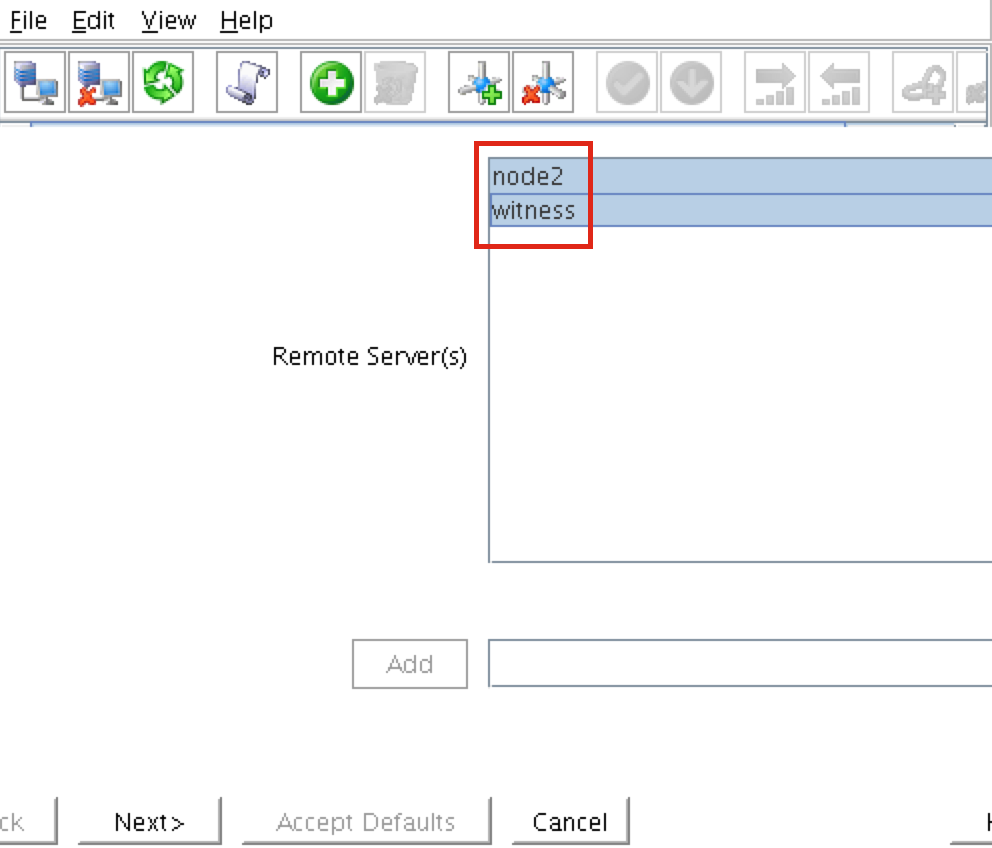
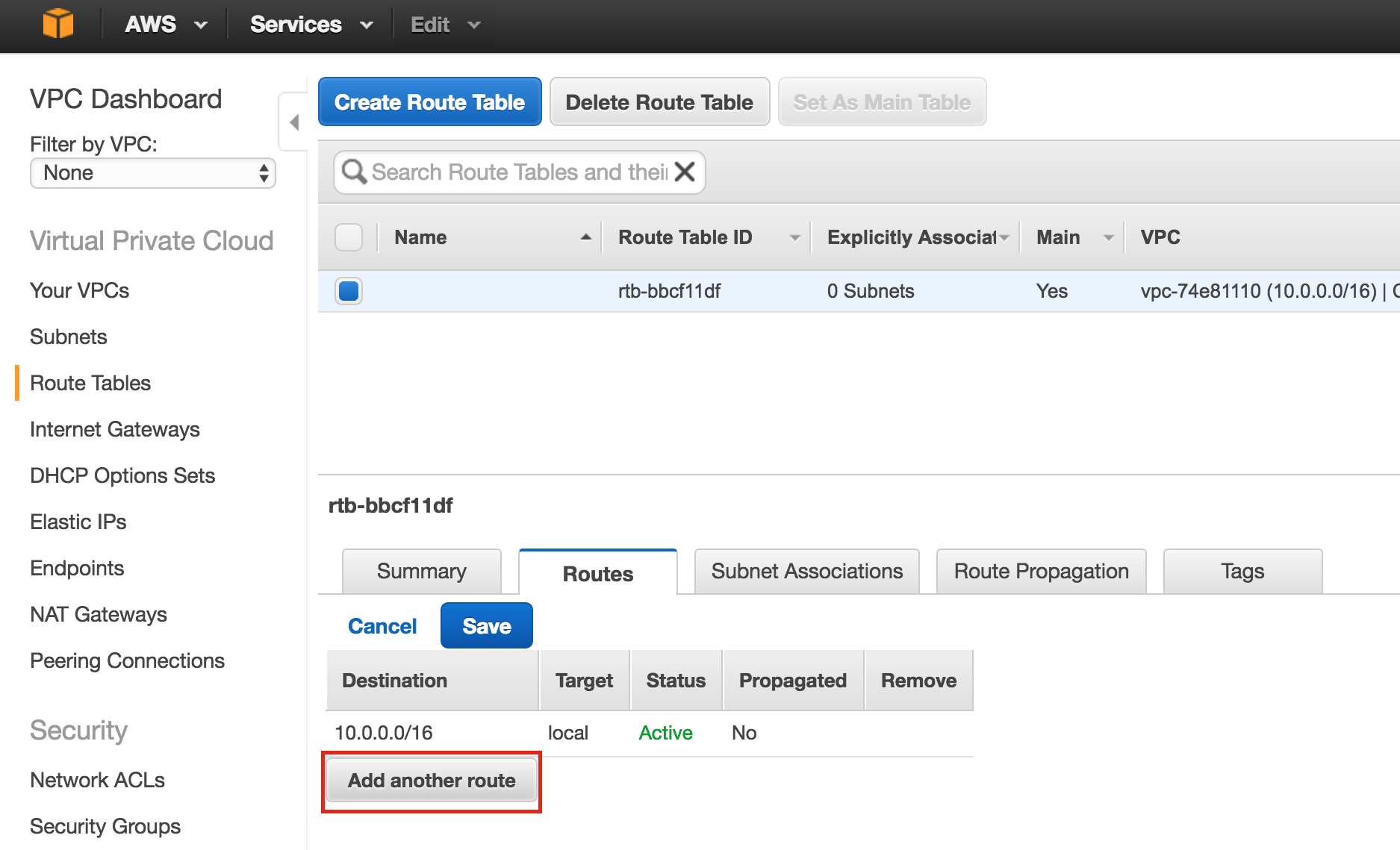
A comm path still needs to be created between node2 & witness. Right click on “node2” and select Create Comm Path. Follow the wizard and select “witness” as the remote server:
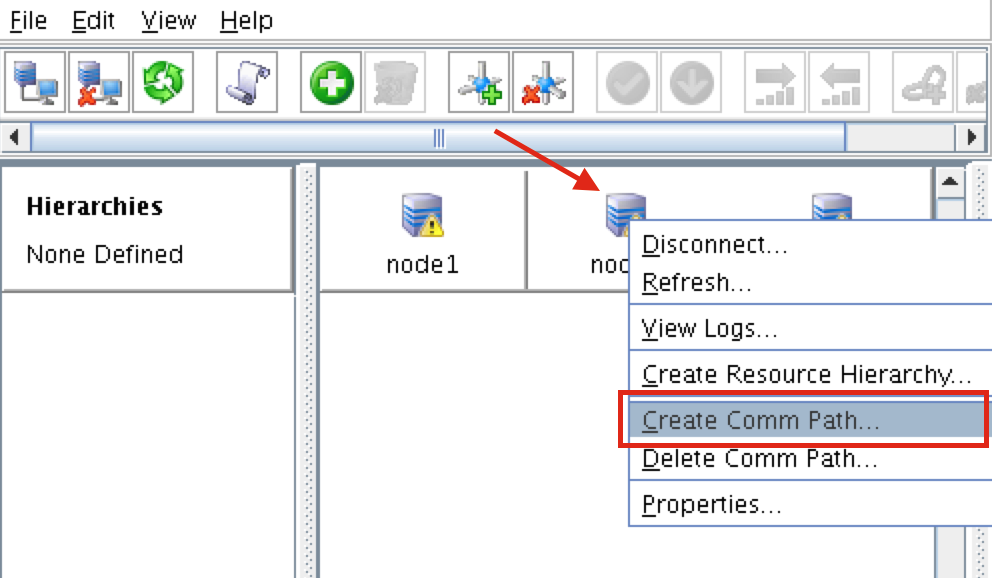
At this point the following comm paths have been created:
- node1 <—> node2
- node1 <—> witness
- node2 <—> witness
The icons in front of the servers have changed from a green “checkmark” to a yellow “hazard sign”. This is because we only have a single communication path between nodes.
If the VMs had multiple NICs (information on creating Azure VMs with multiple NICs can be found here, but won’t be covered in this article), you would create redundant comm paths between each server.
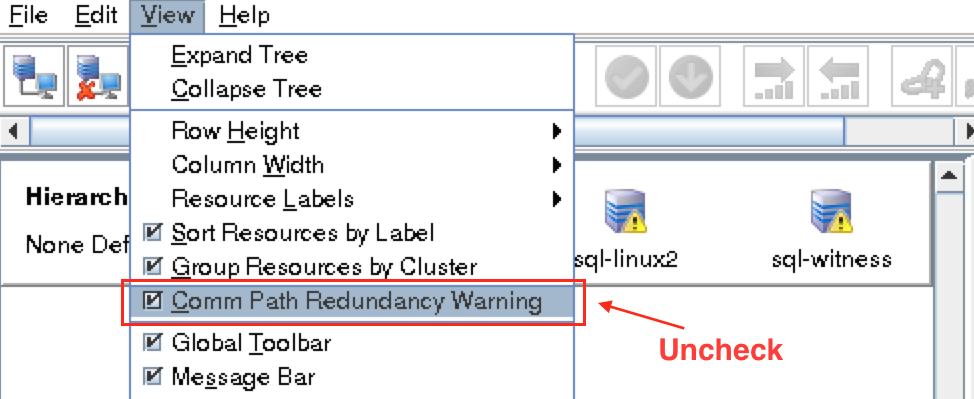
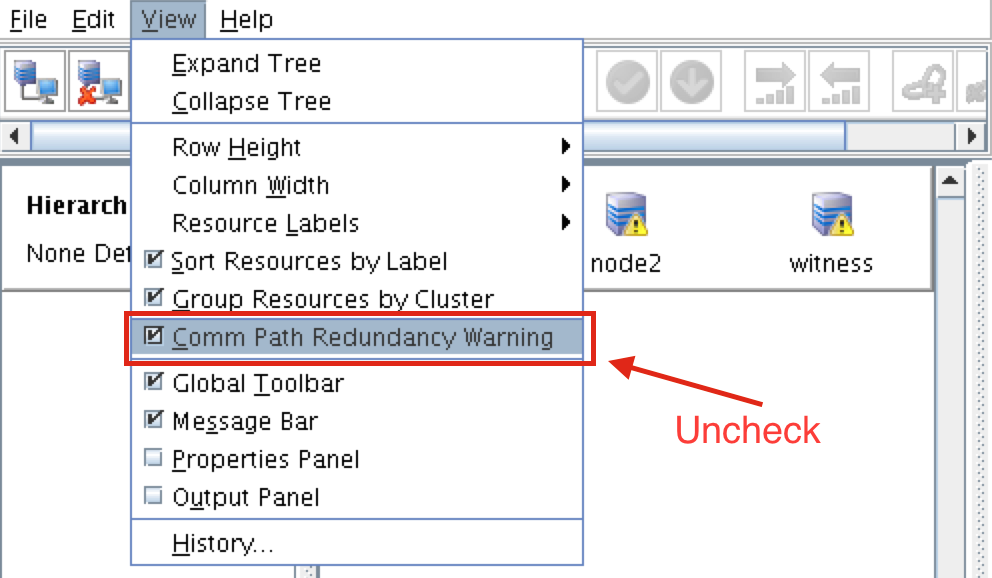
To remove the warning icons, go to the View menu and de-select “Comm Path Redundancy Warning”:
Result:
Verify Communication Paths
Use the “lcdstatus” command to view the state of cluster resources. Run the following commands to verify that you have correctly created comm paths on each node to the other two servers involved:
# /opt/LifeKeeper/bin/lcdstatus -q -d node1
MACHINE NETWORK ADDRESSES/DEVICE STATE PRIO
node2 TCP 10.128.0.2/10.128.0.3 ALIVE 1
witness TCP 10.128.0.2/10.128.0.4 ALIVE 1
#/opt/LifeKeeper/bin/lcdstatus -q -d node2
MACHINE NETWORK ADDRESSES/DEVICE STATE PRIO
node1 TCP 10.128.0.3/10.128.0.2 ALIVE 1
witness TCP 10.128.0.3/10.128.0.4 ALIVE 1
#/opt/LifeKeeper/bin/lcdstatus -q -d witness
MACHINE NETWORK ADDRESSES/DEVICE STATE PRIO
node1 TCP 10.128.0.4/10.128.0.2 ALIVE 1
node2 TCP 10.128.0.4/10.128.0.3 ALIVE 1
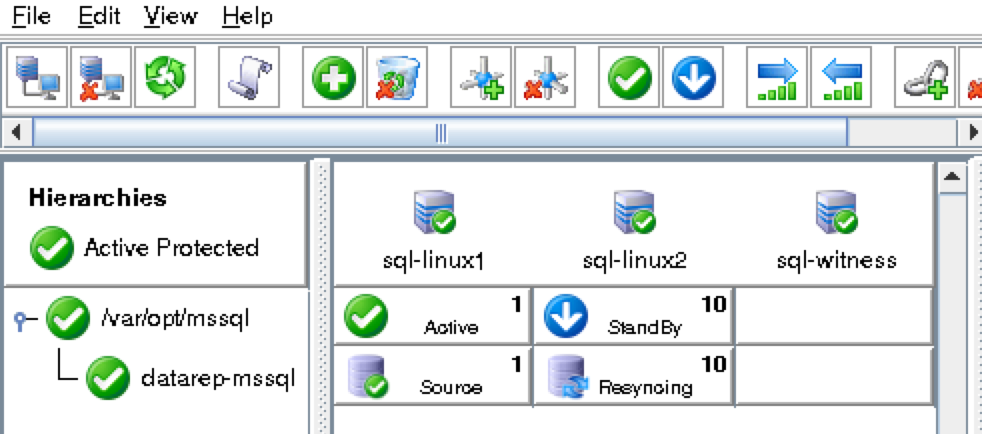
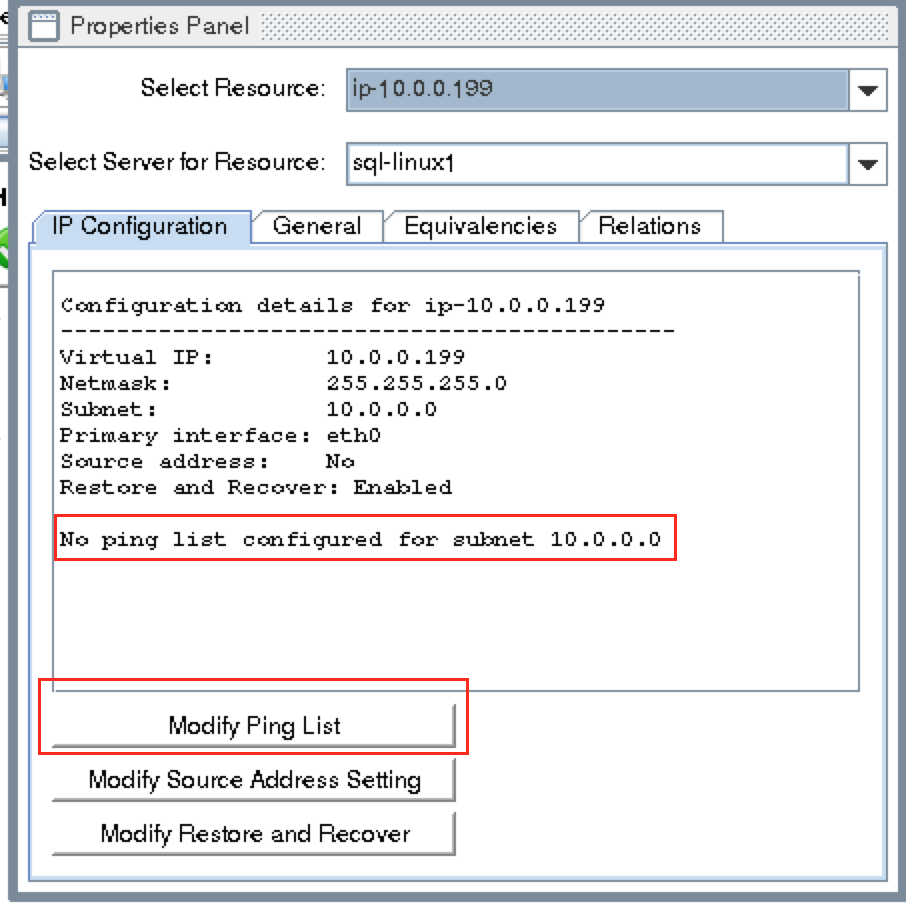
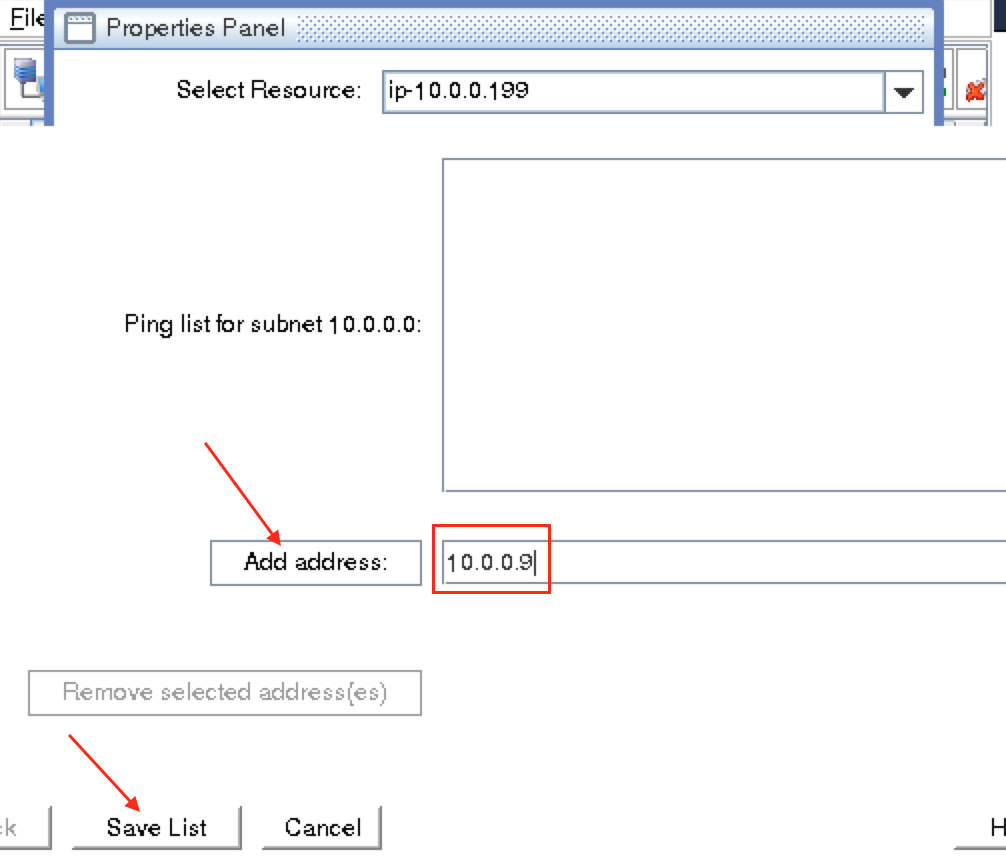
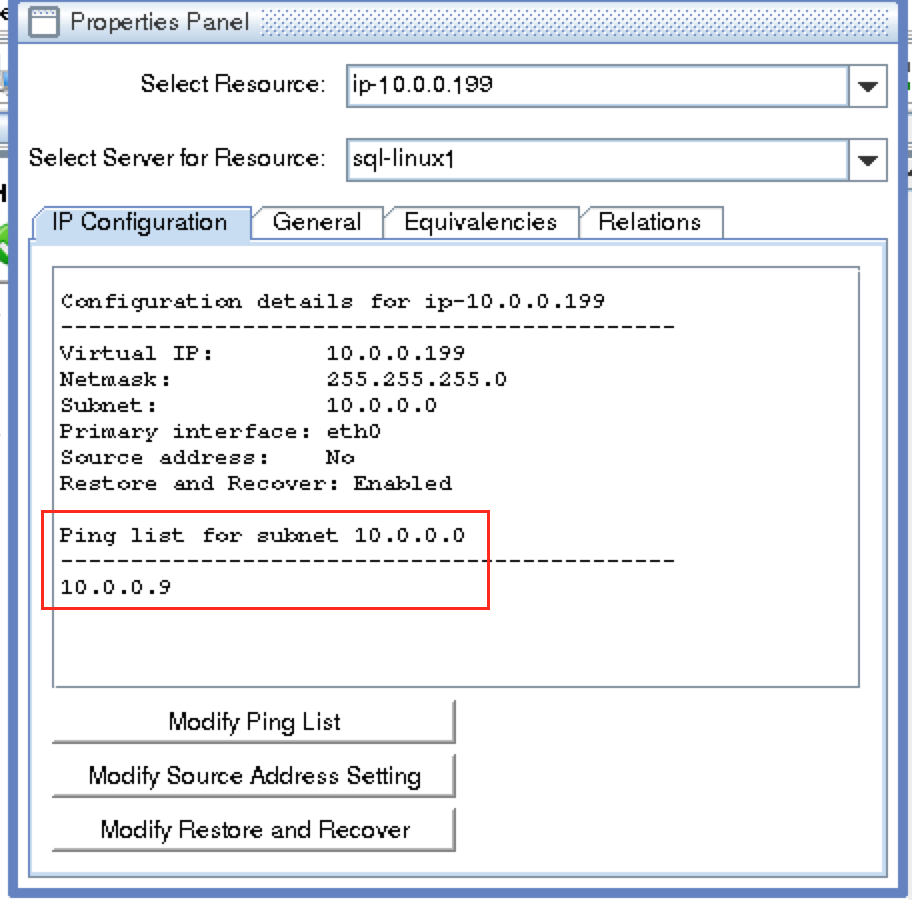
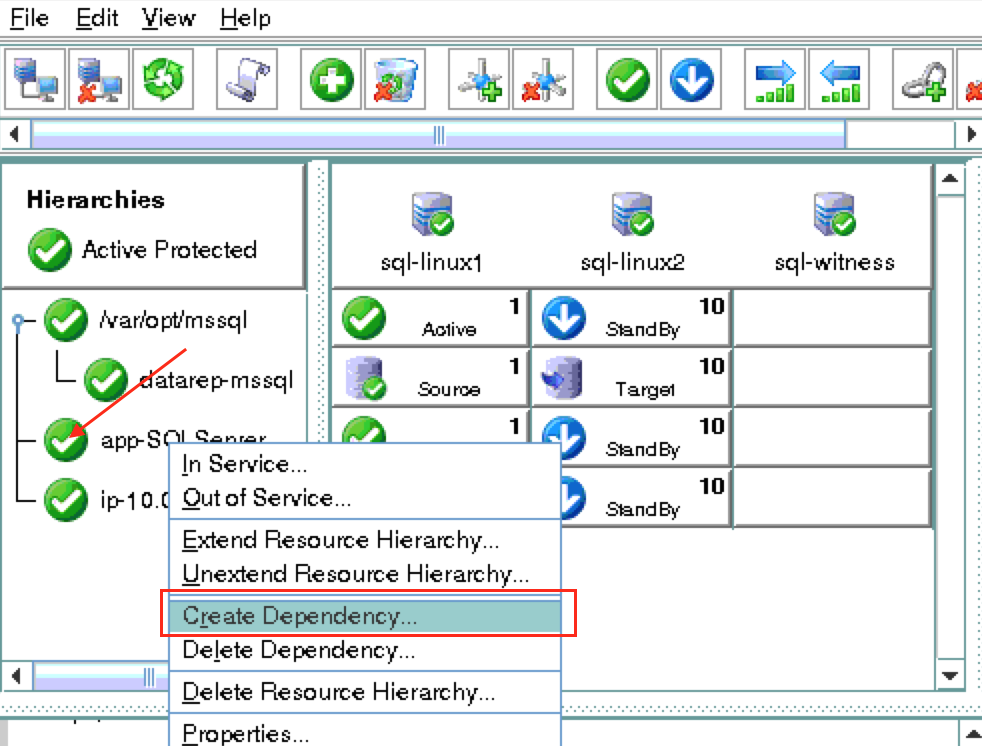
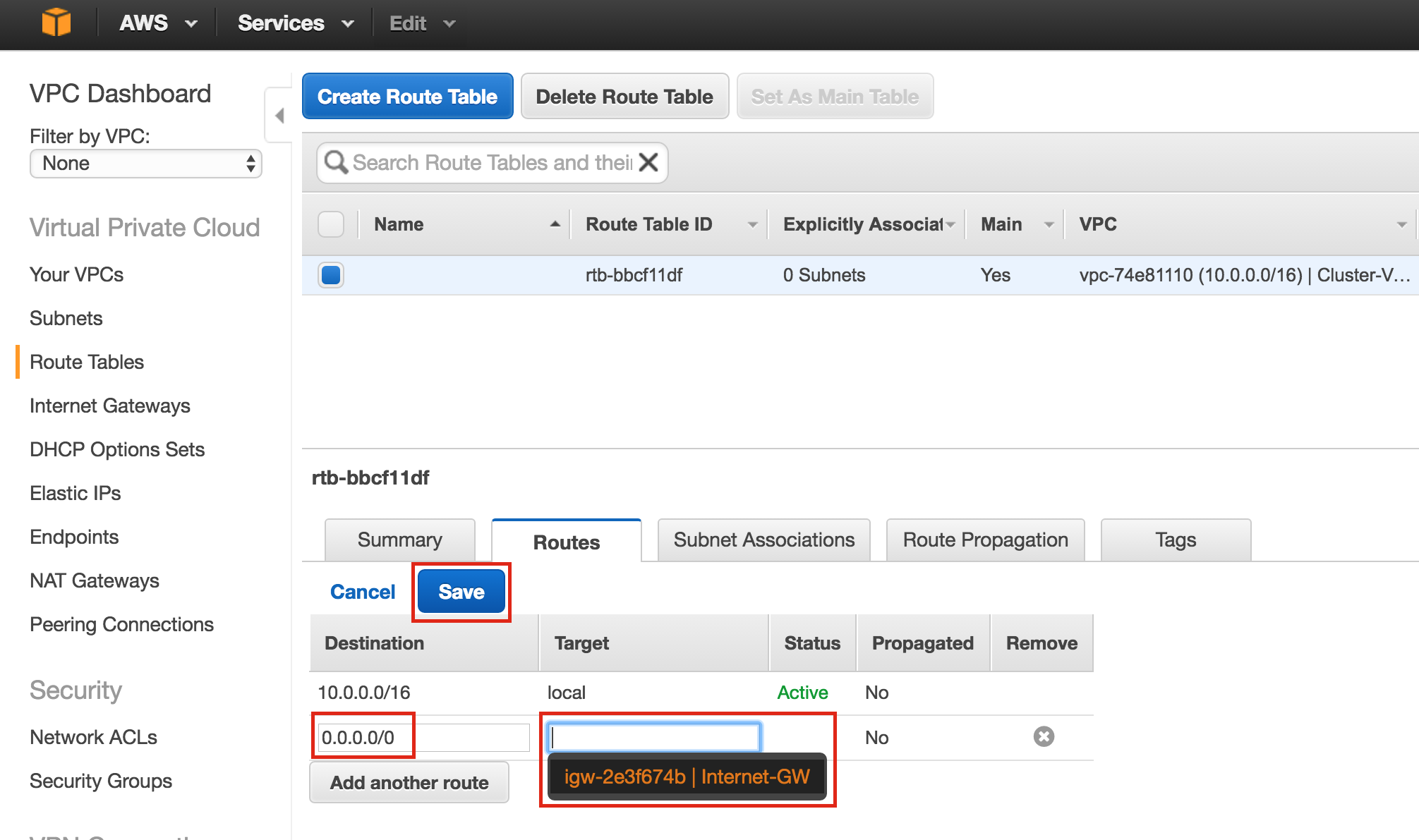
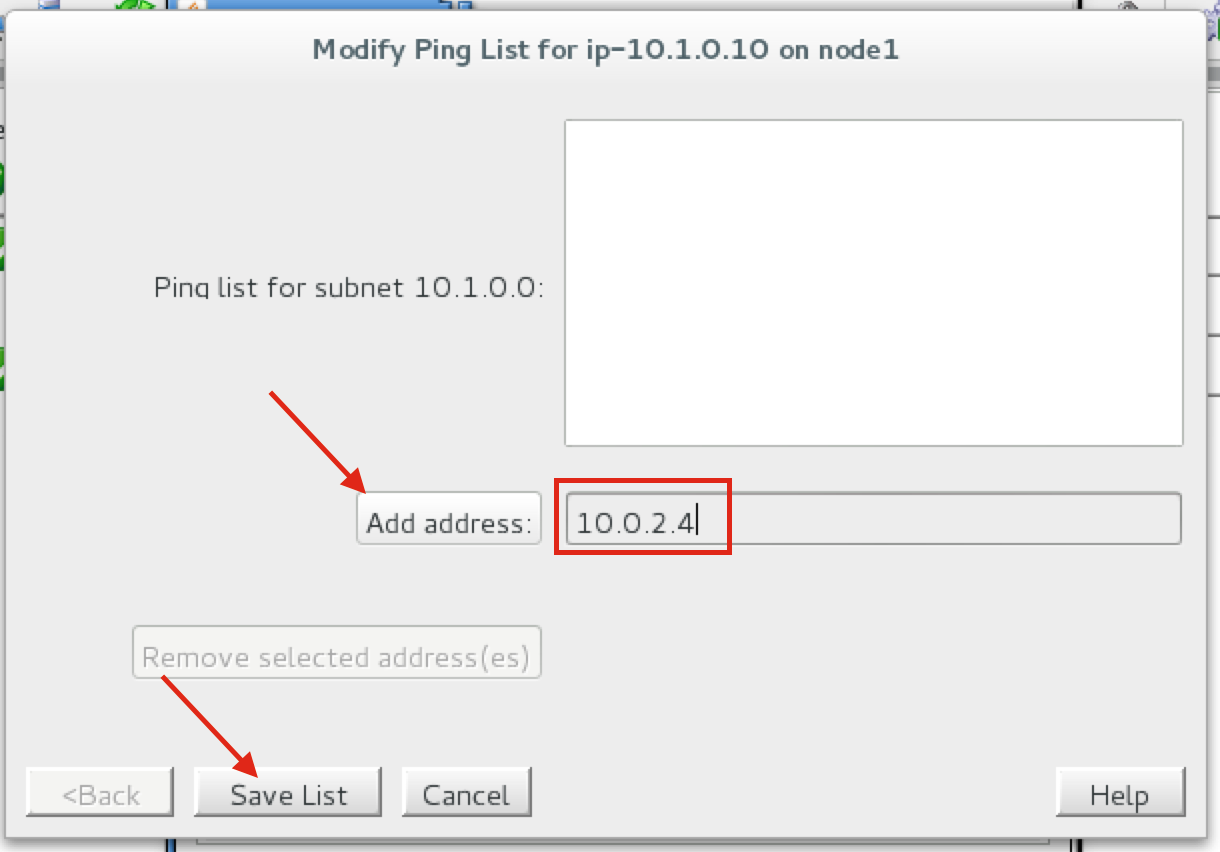
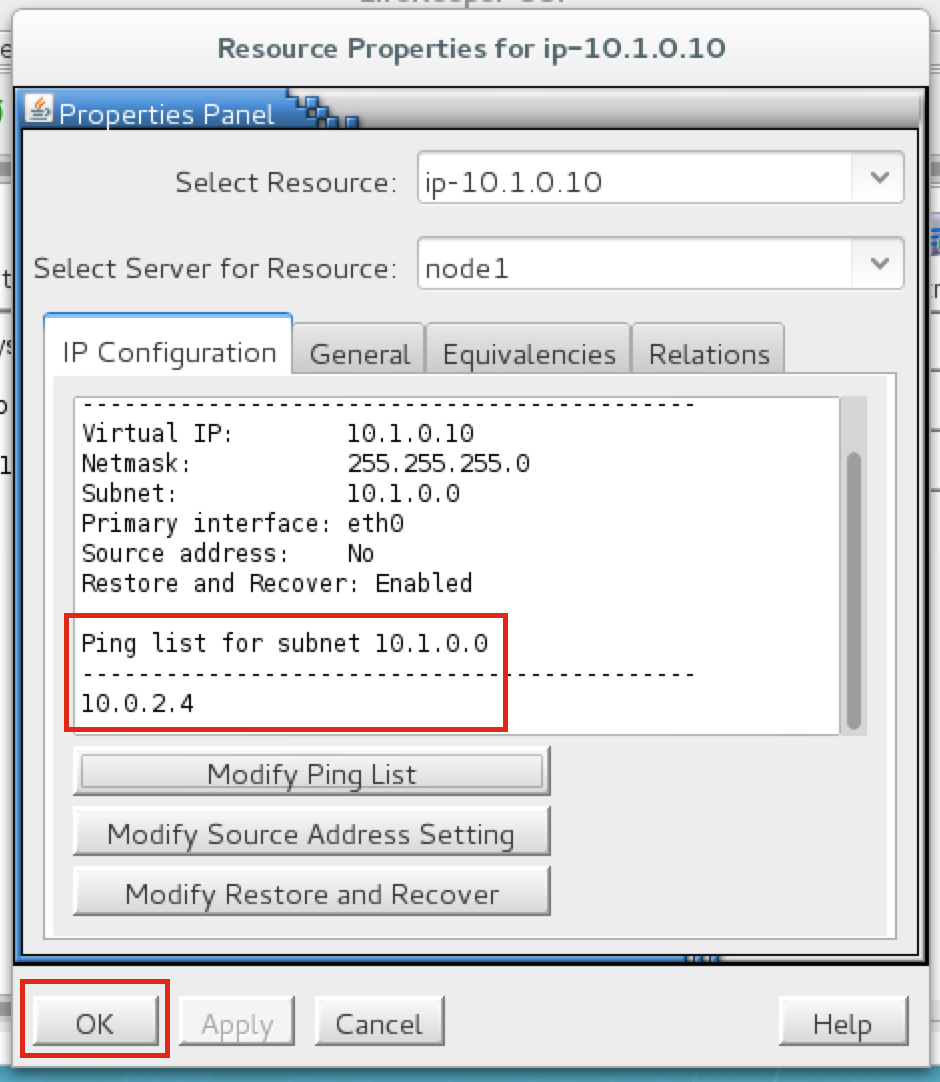
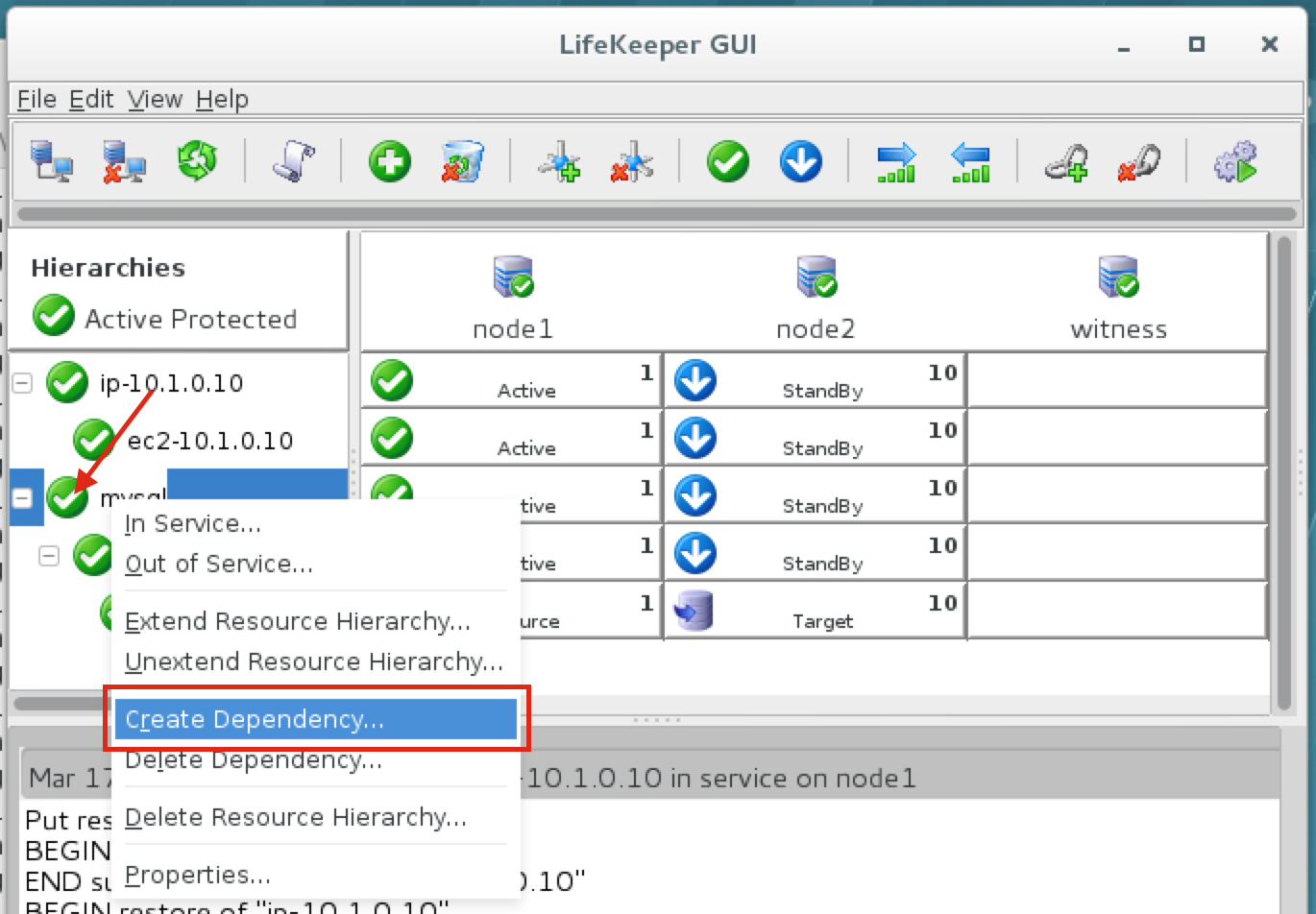
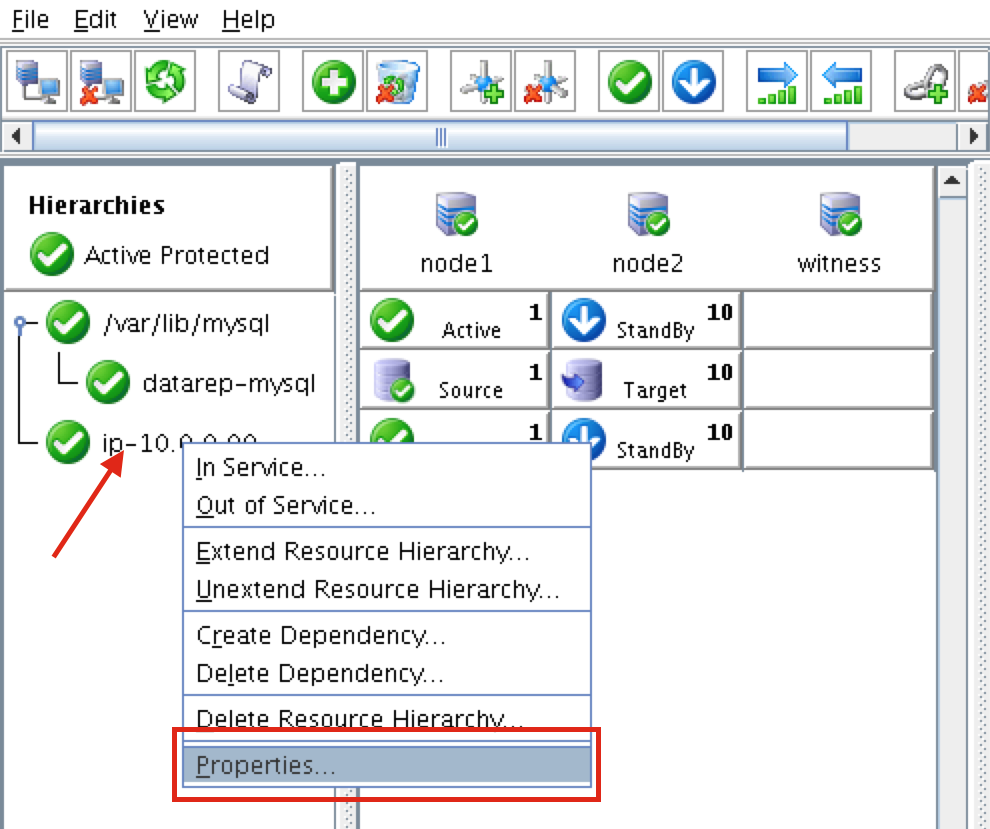
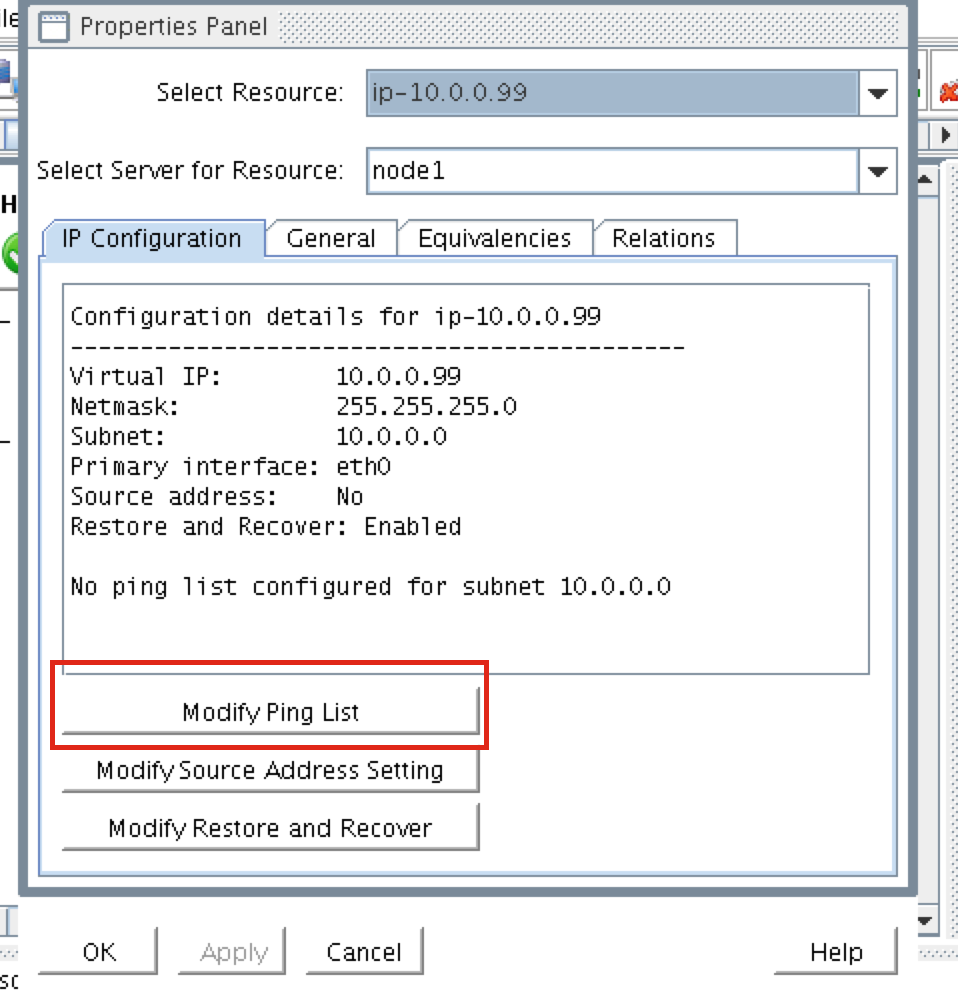
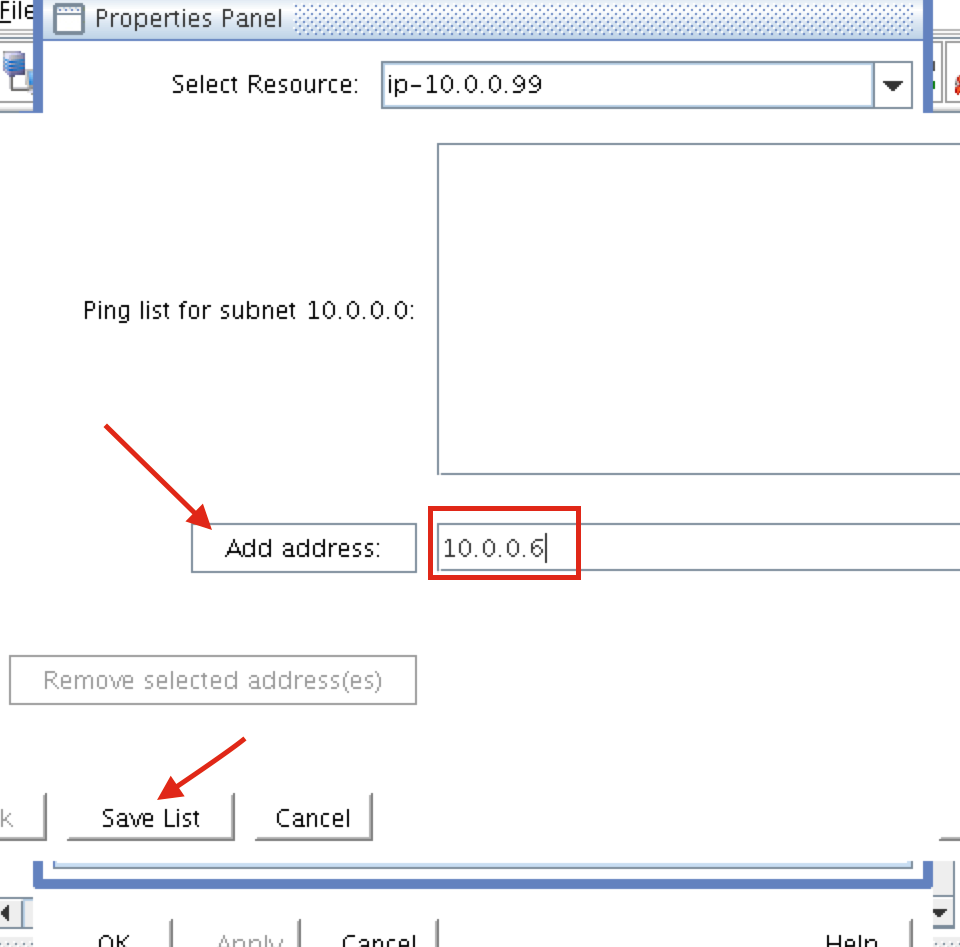
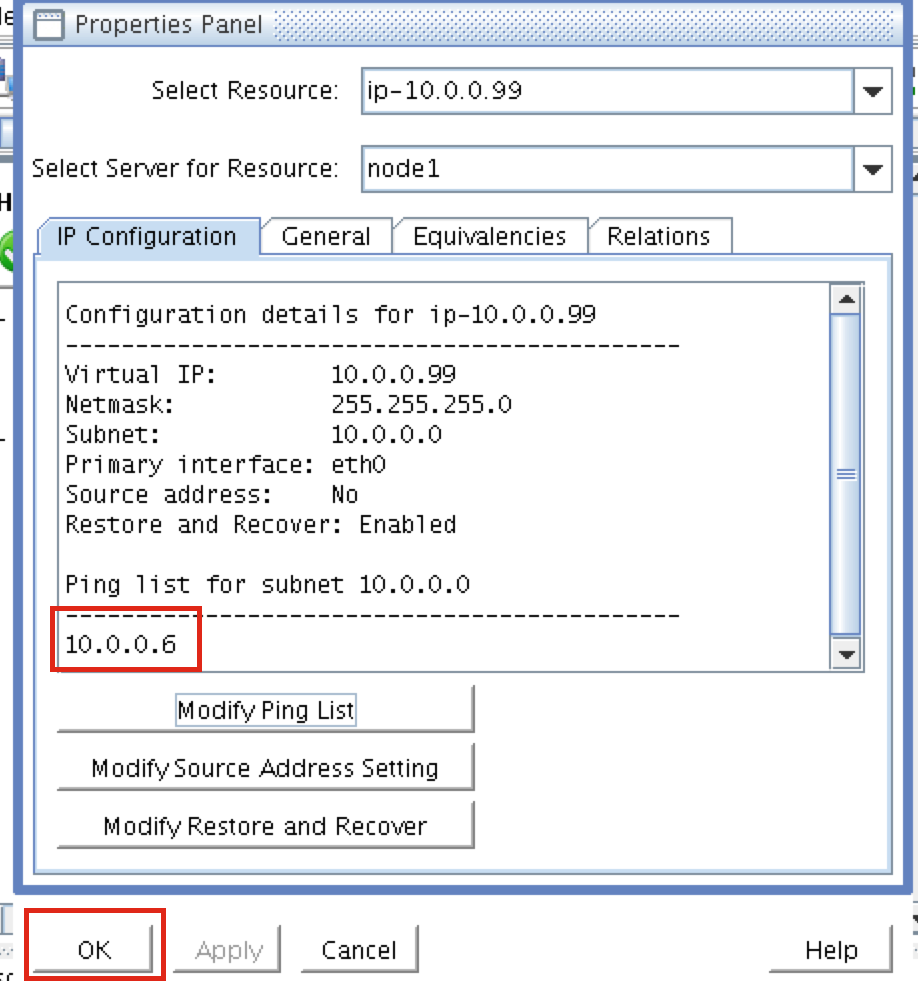
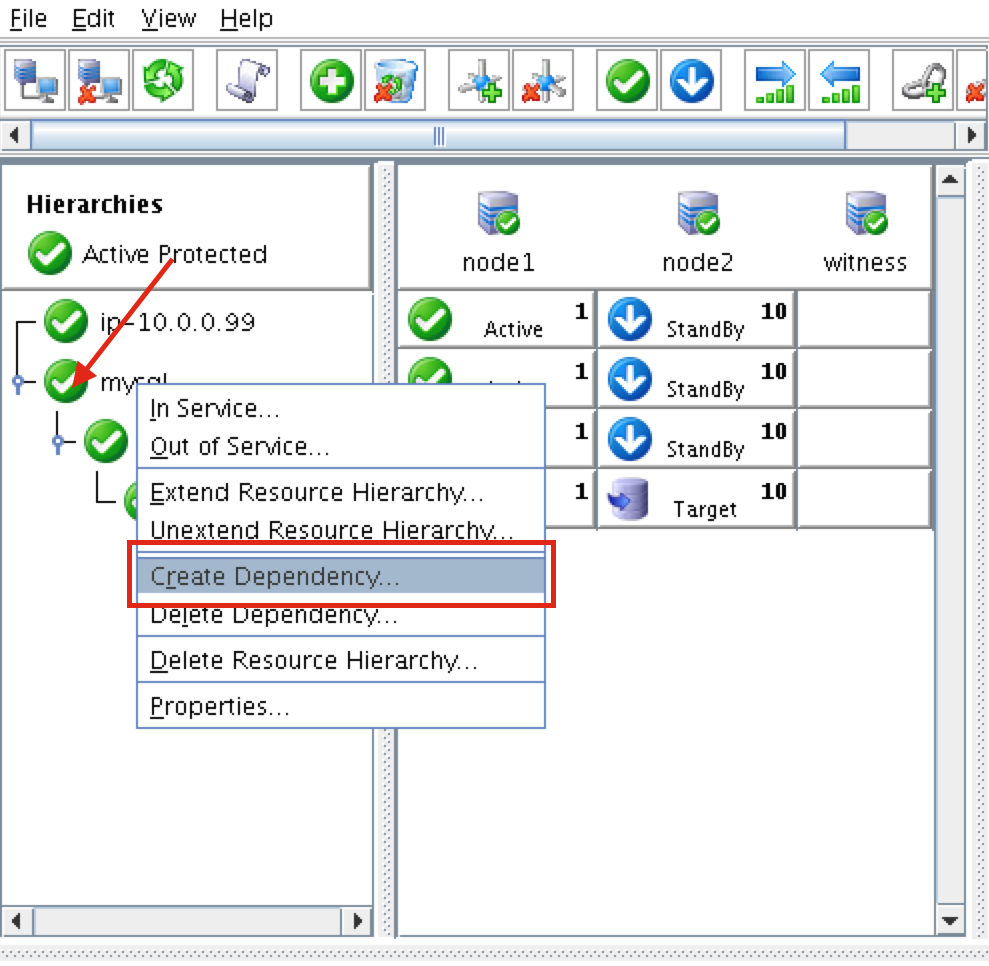
Create a Data Replication cluster resource (i.e. Mirror)
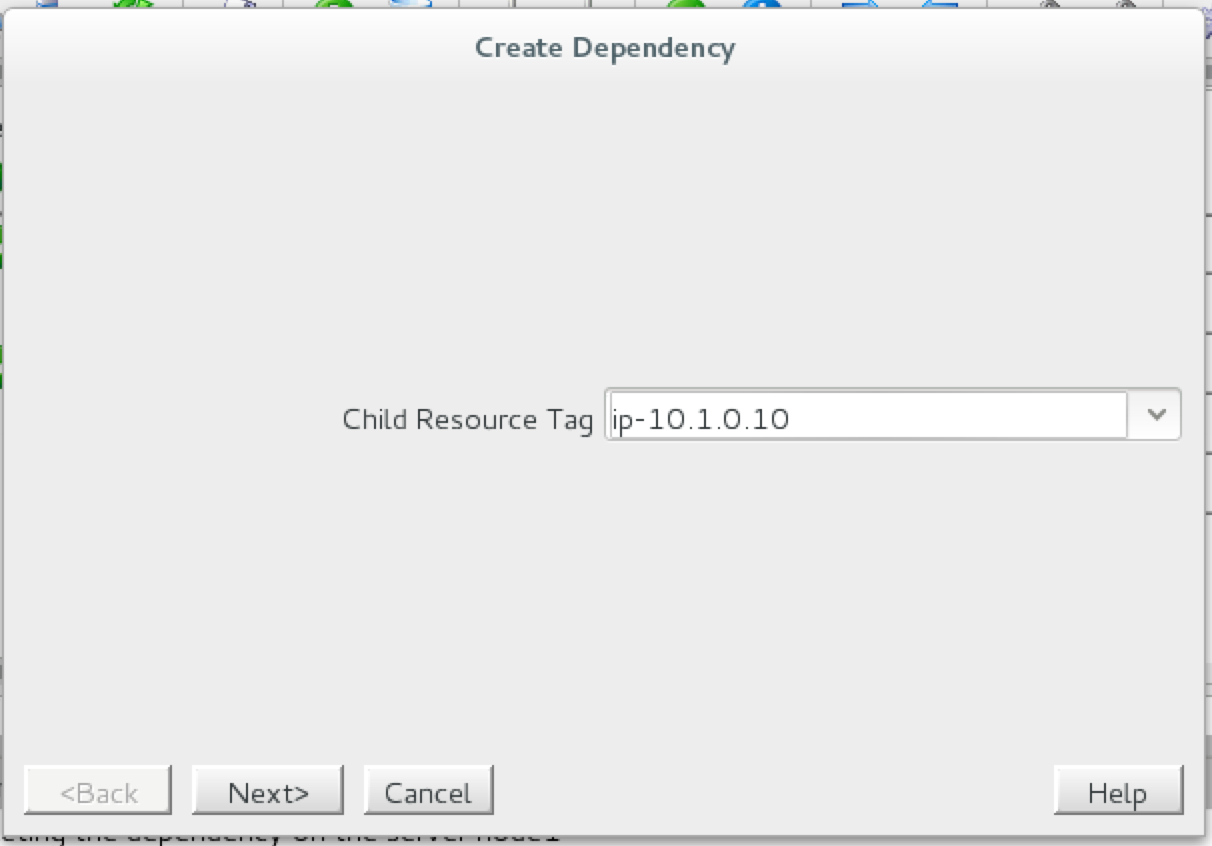
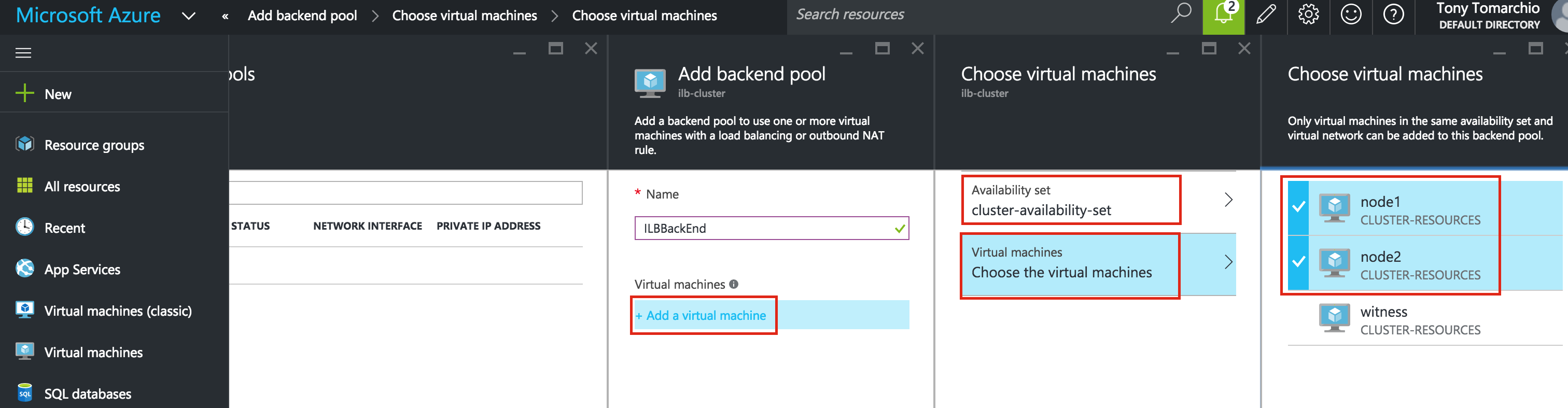
Next, create a Data Replication resource to replicate the /var/lib/mysql partition from node1 (source) to node2 (target). Click the “green plus” icon to create a new resource:
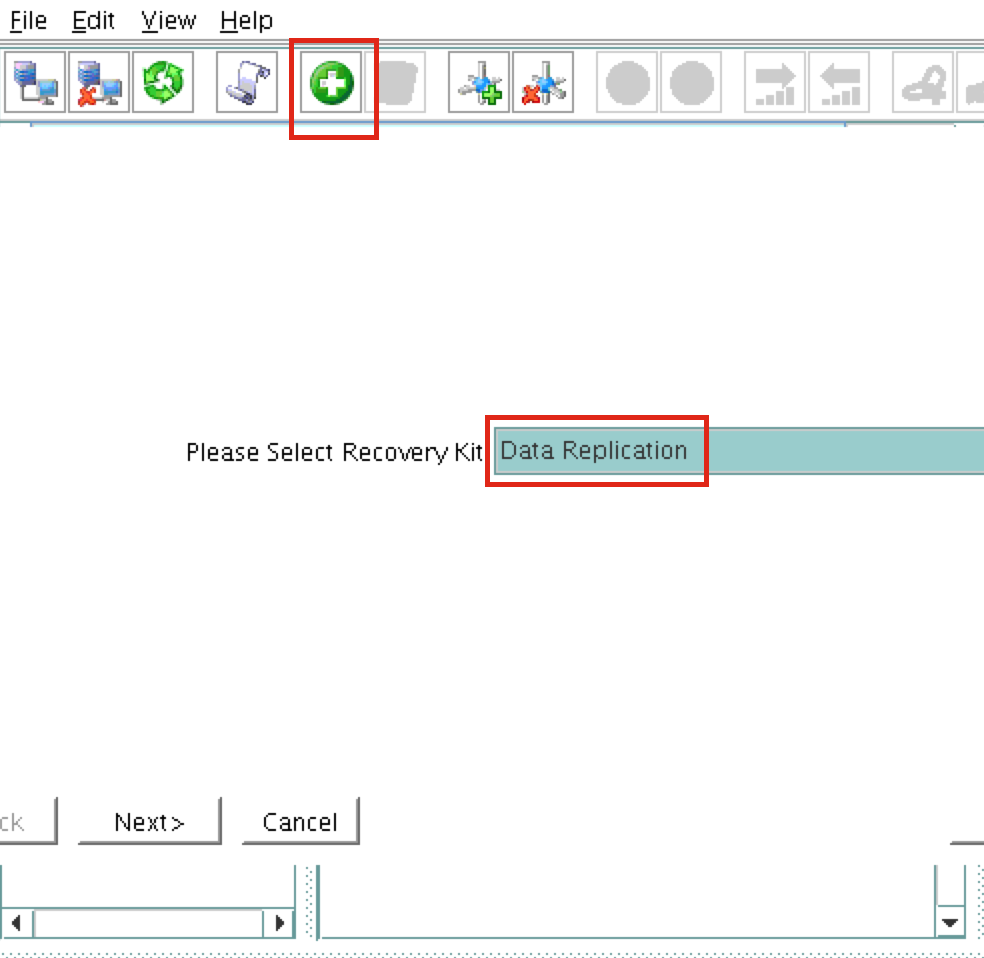
Follow the wizard with these selections:
Please Select Recovery Kit: Data Replication Switchback Type: intelligent Server: node1 Hierarchy Type: Replicate Exiting Filesystem Existing Mount Point: /var/lib/mysql Data Replication Resource Tag: datarep-mysql File System Resource Tab: /var/lib/mysql Bitmap File: (default value) Enable Asynchronous Replication: No
After the resource has been created, the “Extend” (i.e. define backup server) wizard will appear. Use the following selections:
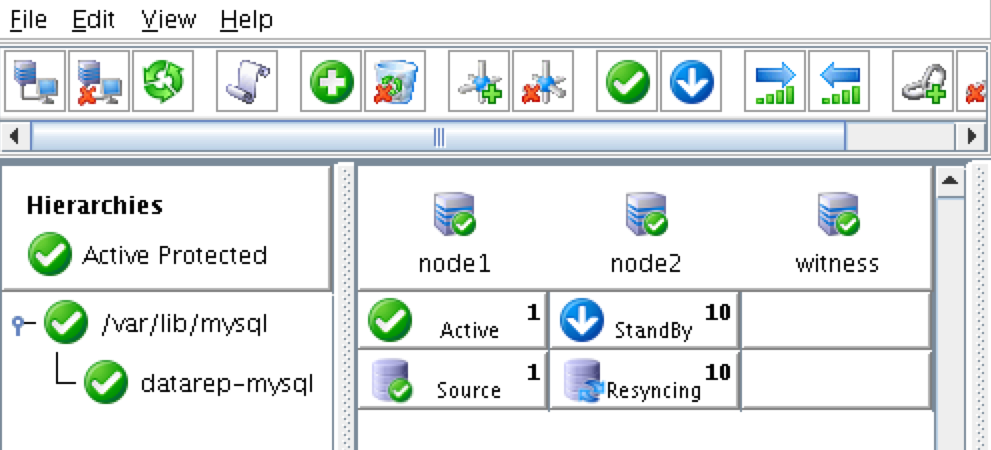
Target Server: node2 Switchback Type: Intelligent Template Priority: 1 Target Priority: 10 Target Disk: /dev/sdb1 Data Replication Resource Tag: datarep-mysql Bitmap File: (default value) Replication Path: 10.128.0.2/10.128.0.3 Mount Point: /var/lib/mysql Root Tag: /var/lib/mysql
The cluster will look like this:
Create the MySQL resource hierarchy
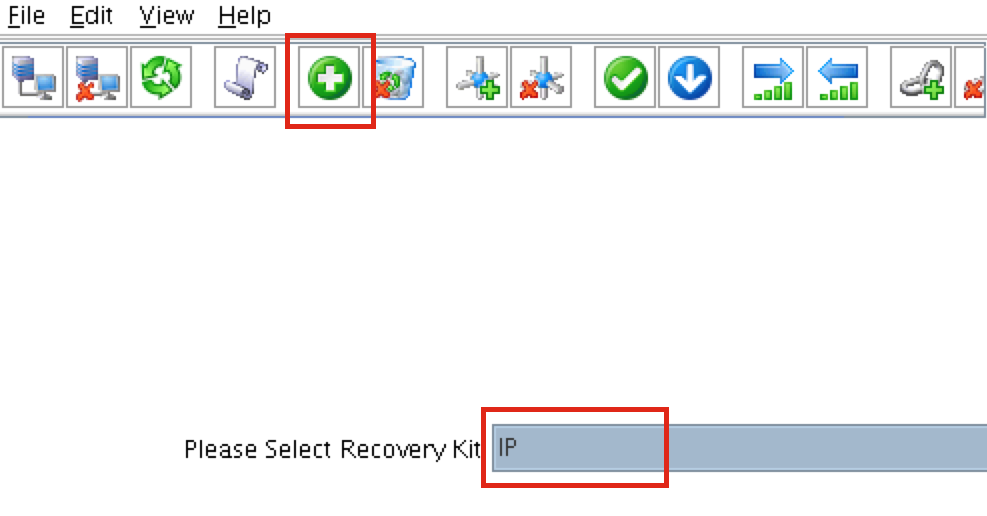
Next, create a MySQL cluster resource. The MySQL resource is responsible for stopping/starting/monitoring of your MySQL database. To create, click the “green plus” icon to create a new resource:
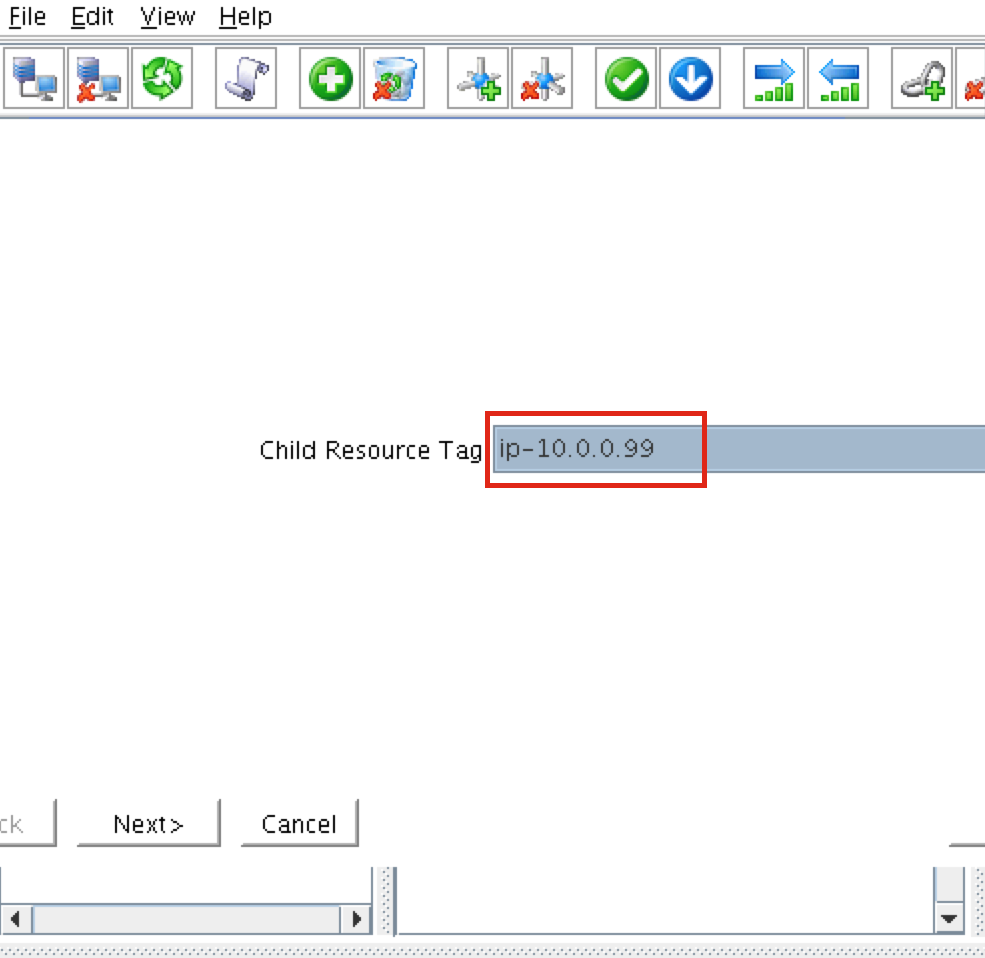
Follow the wizard with to create the IP resource with these selections:
Select Recovery Kit: MySQL Database Switchback Type: Intelligent Server: node1 Location of my.cnf: /var/lib/mysql Location of MySQL executables: /usr/bin Database Tag: mysql
Extend the IP resource with the following selections:
Target Server: node2 Switchback Type: intelligent Template Priority: 1 Target Priority: 10
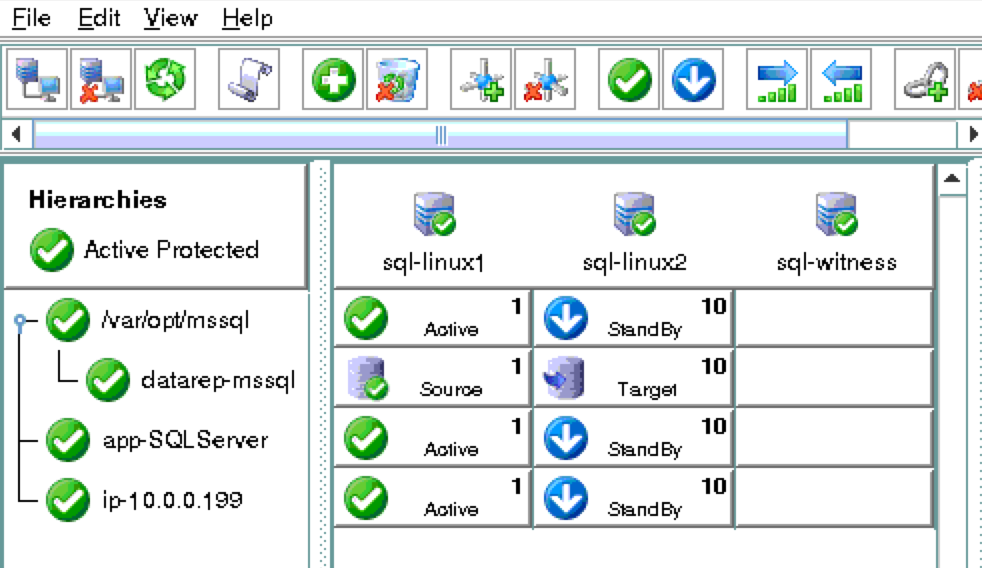
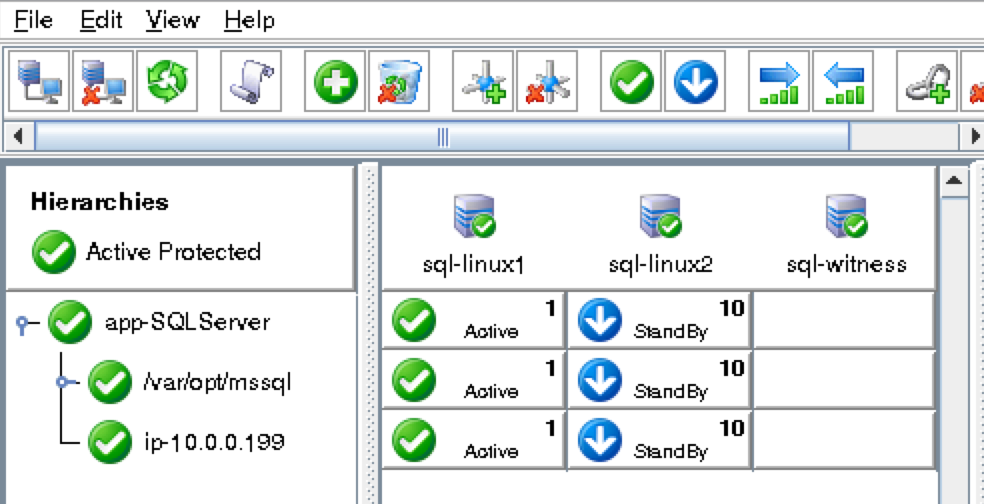
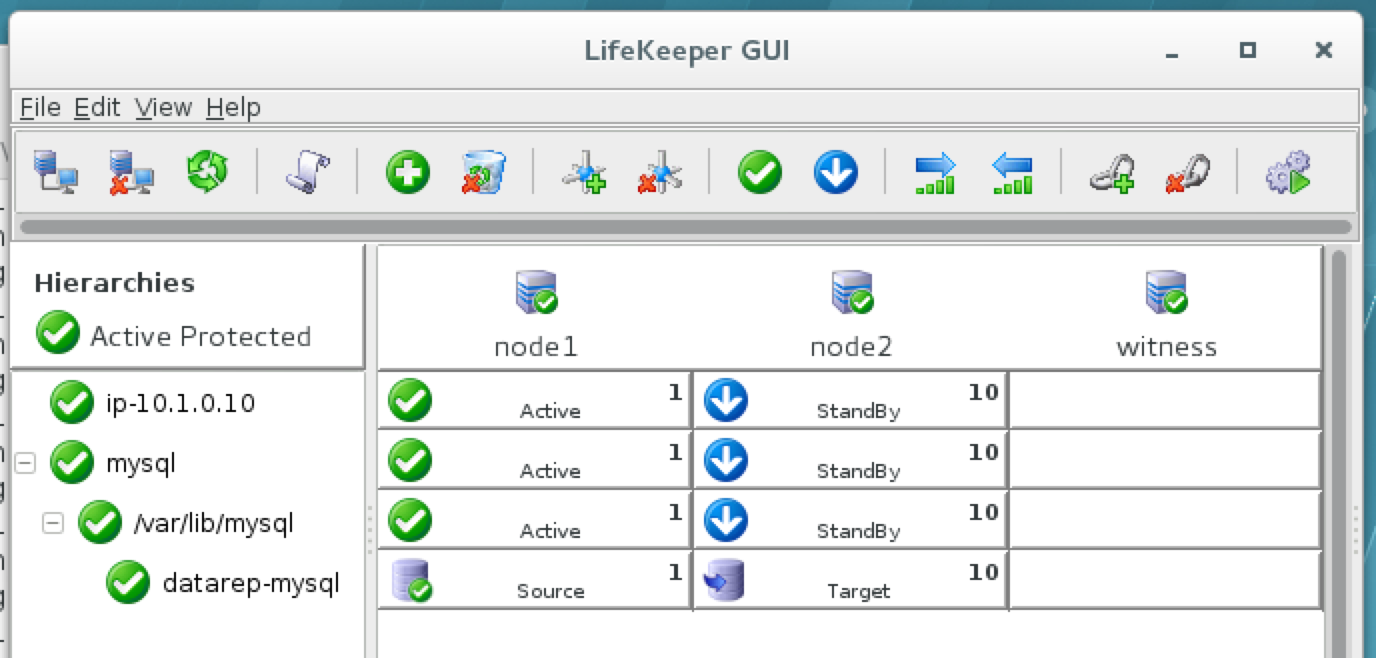
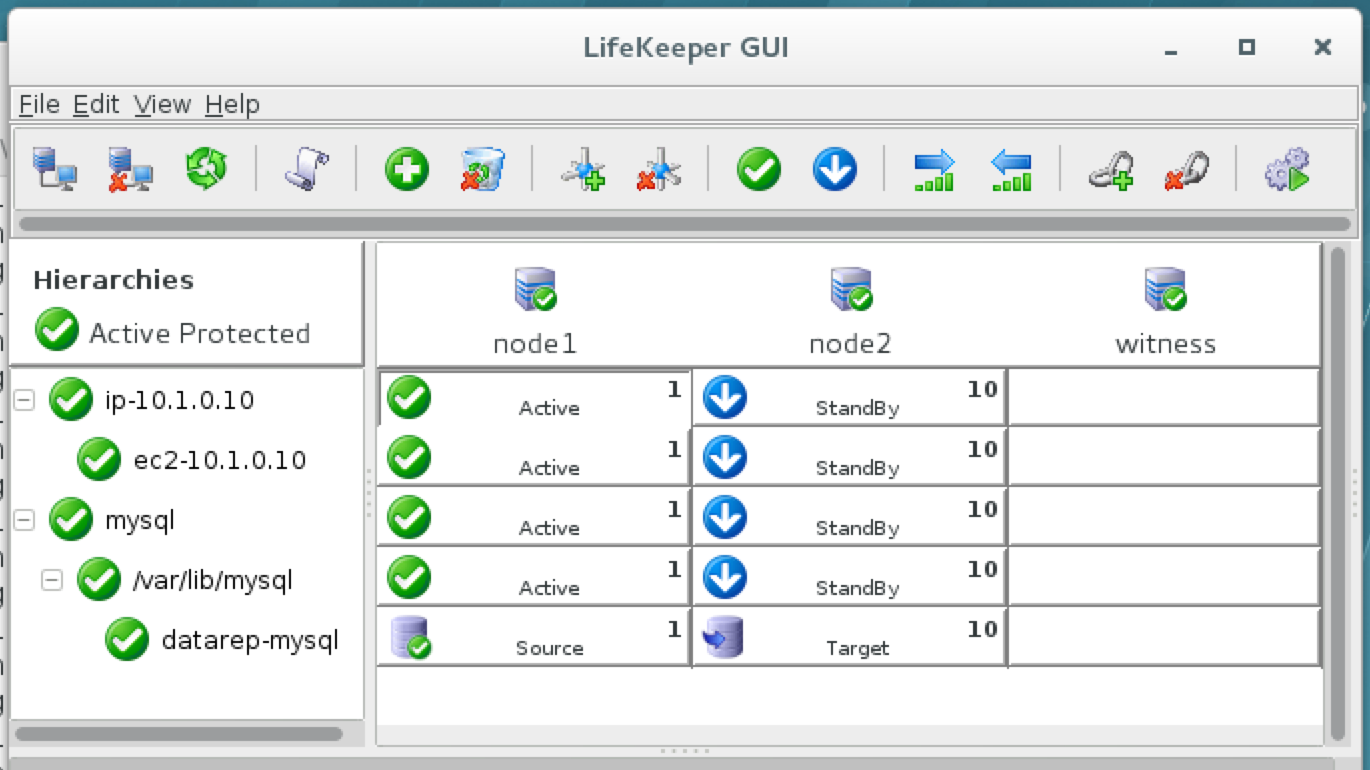
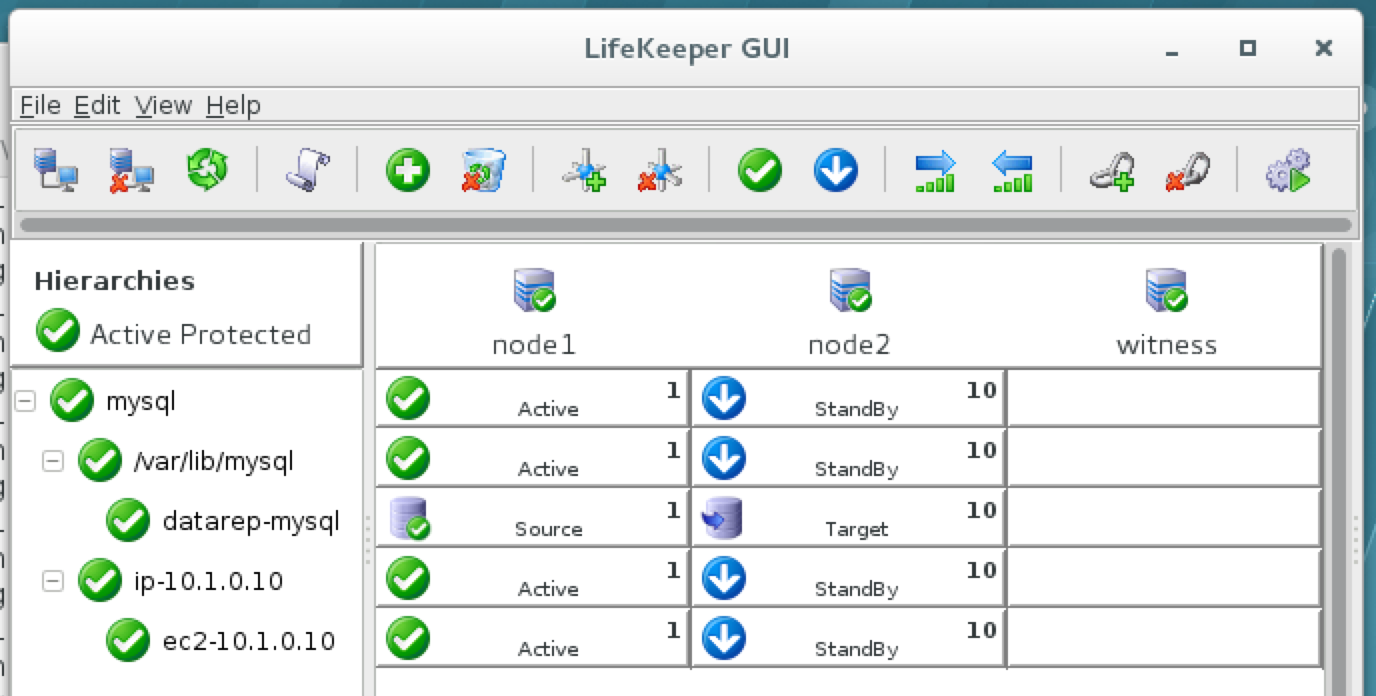
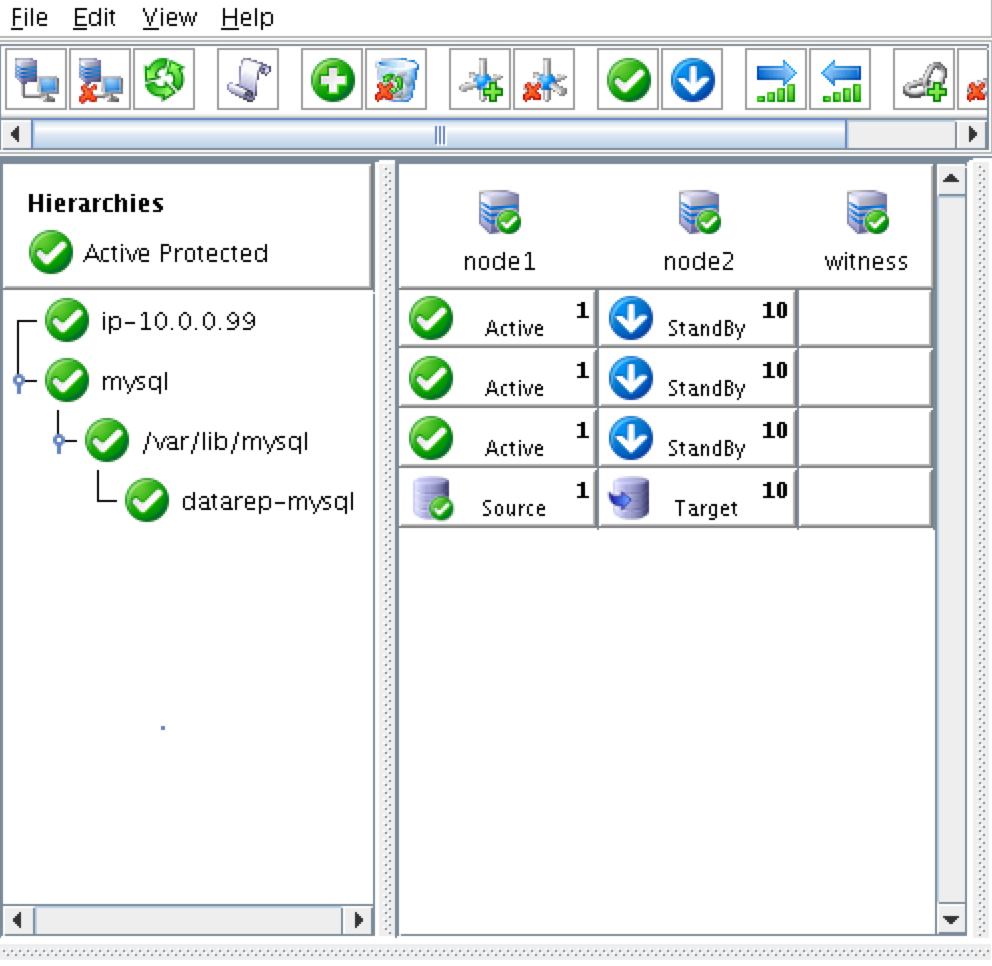
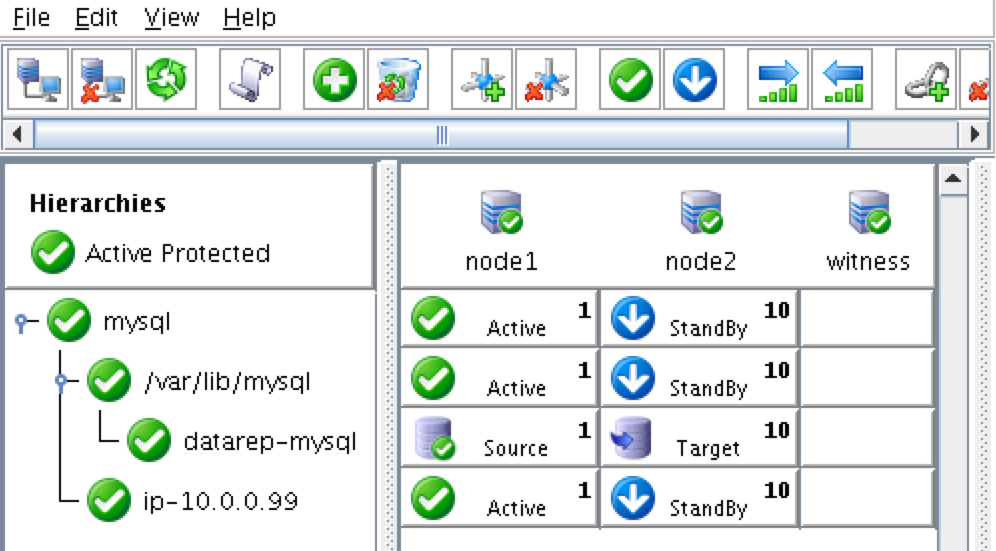
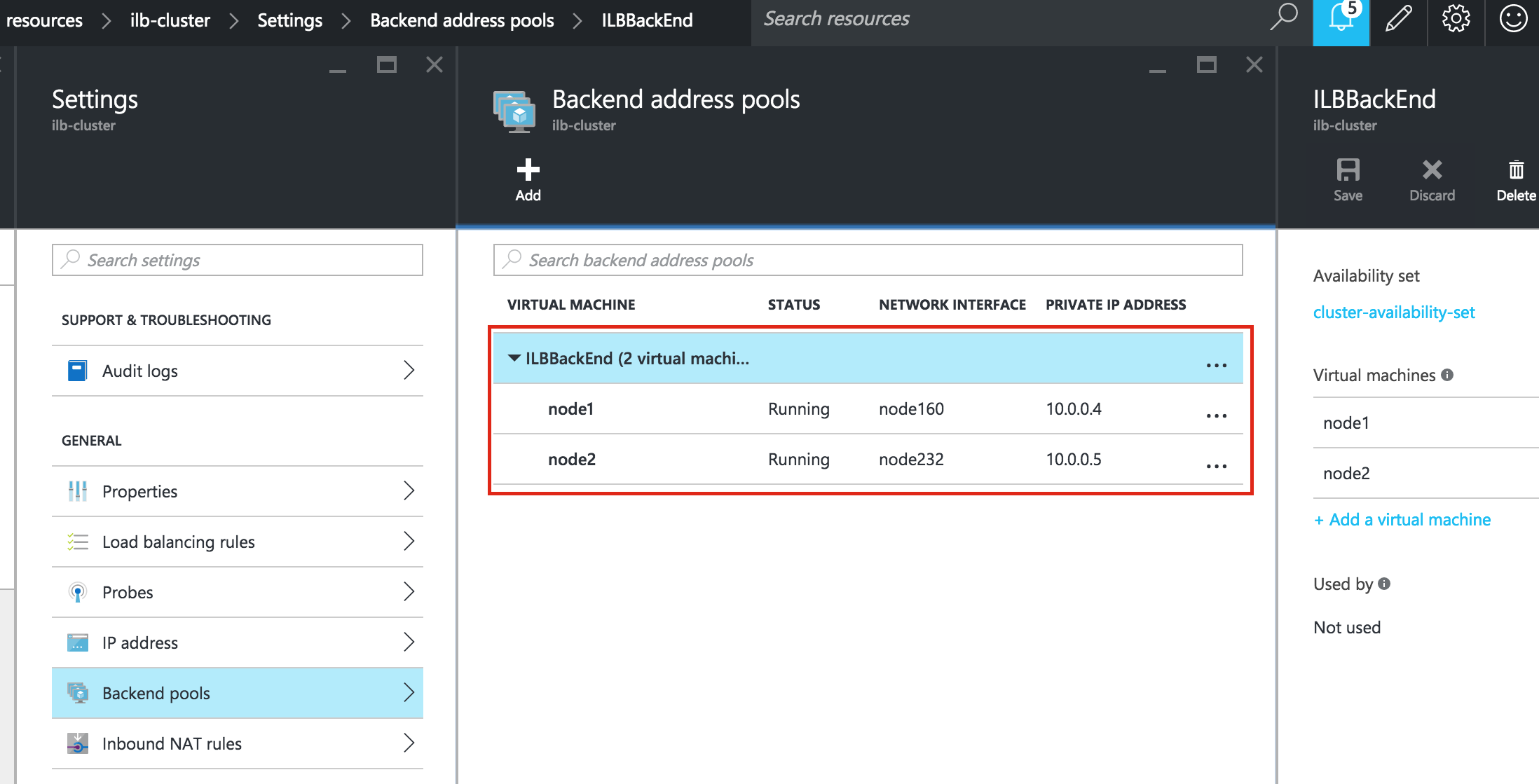
As a result, your cluster will look as follows. Notice that the Data Replication resource was automatically moved underneath the database (dependency automatically created) to ensure it’s always brought online before the database:
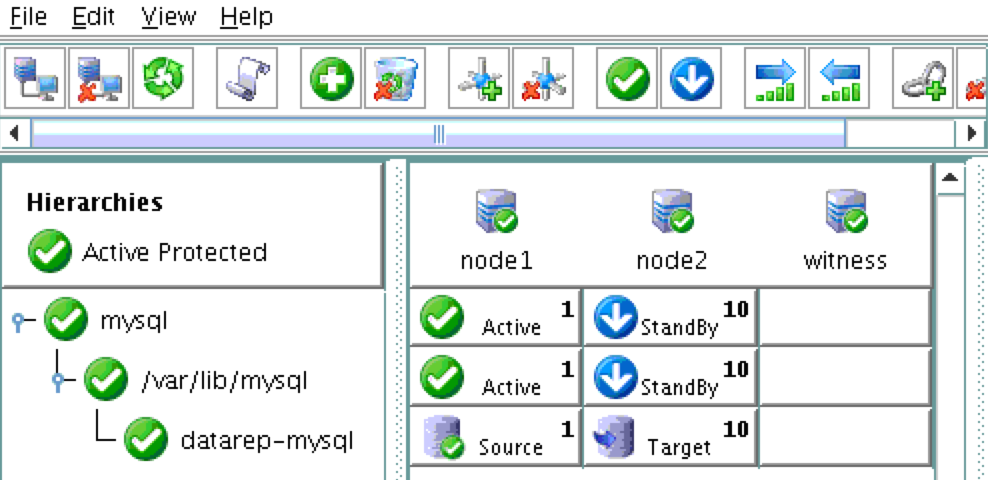
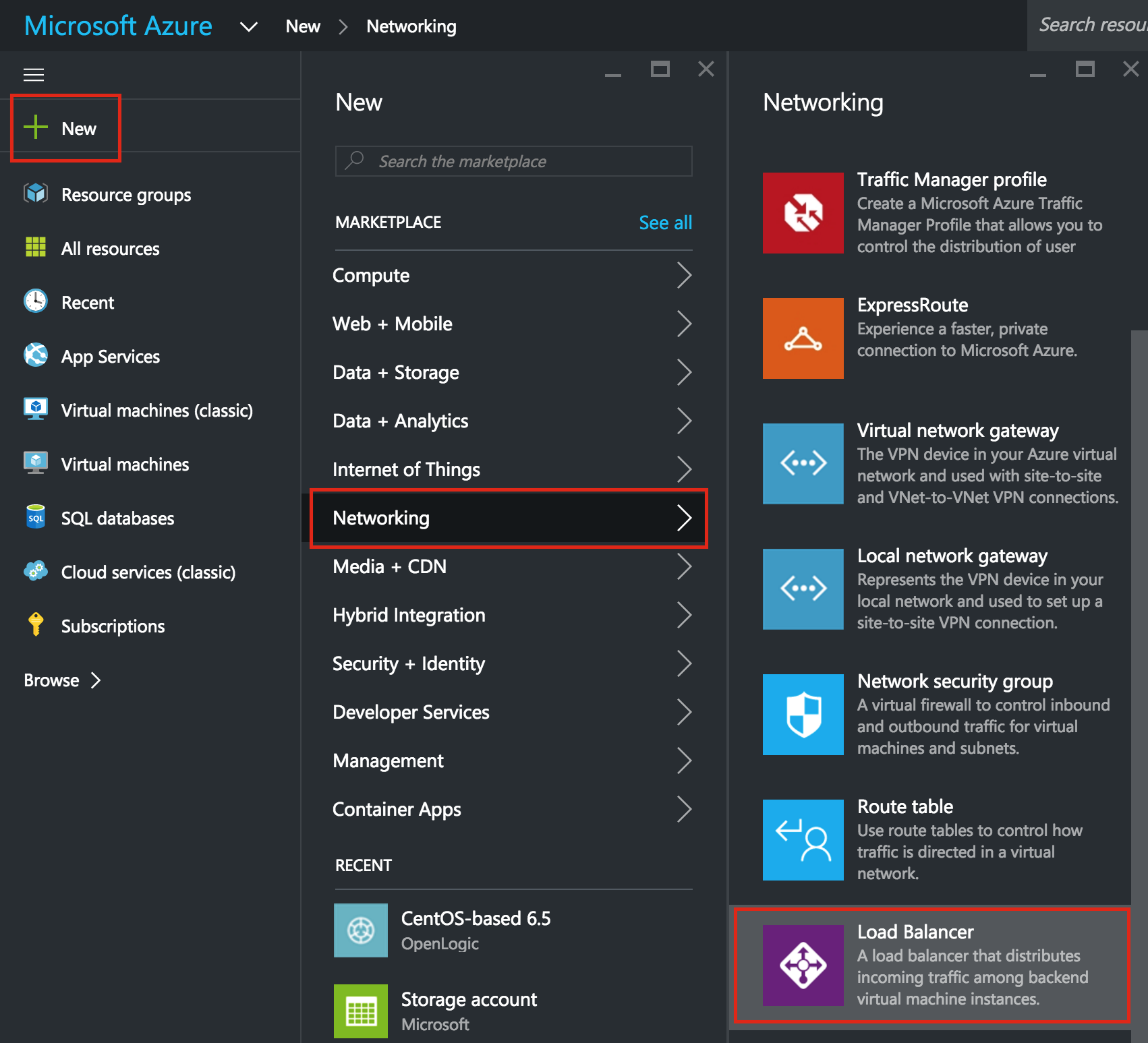
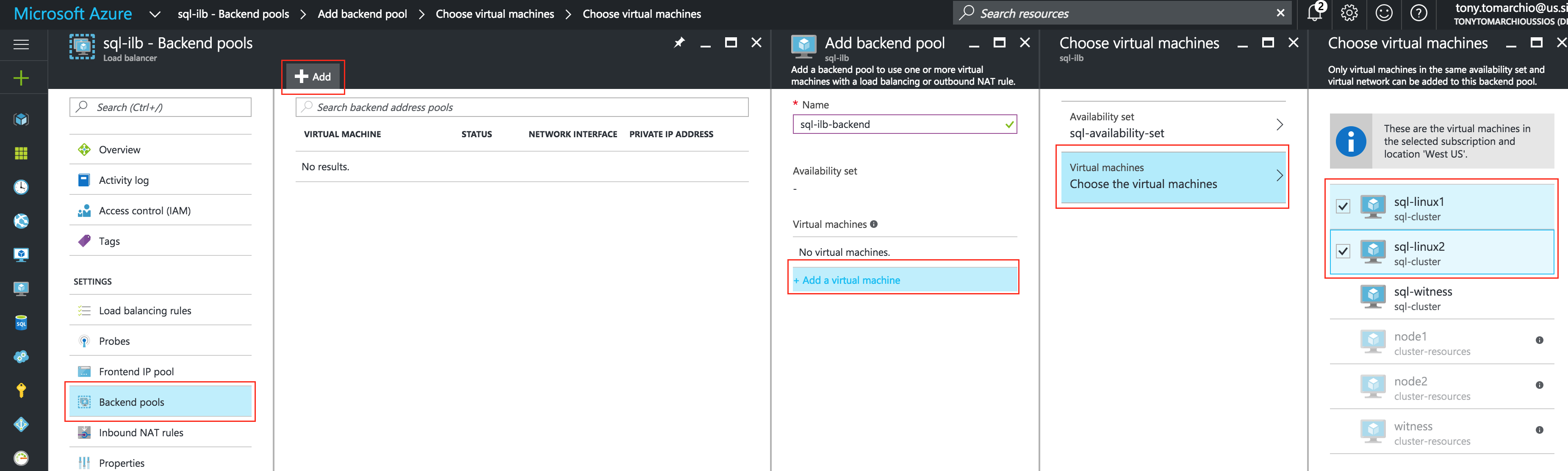
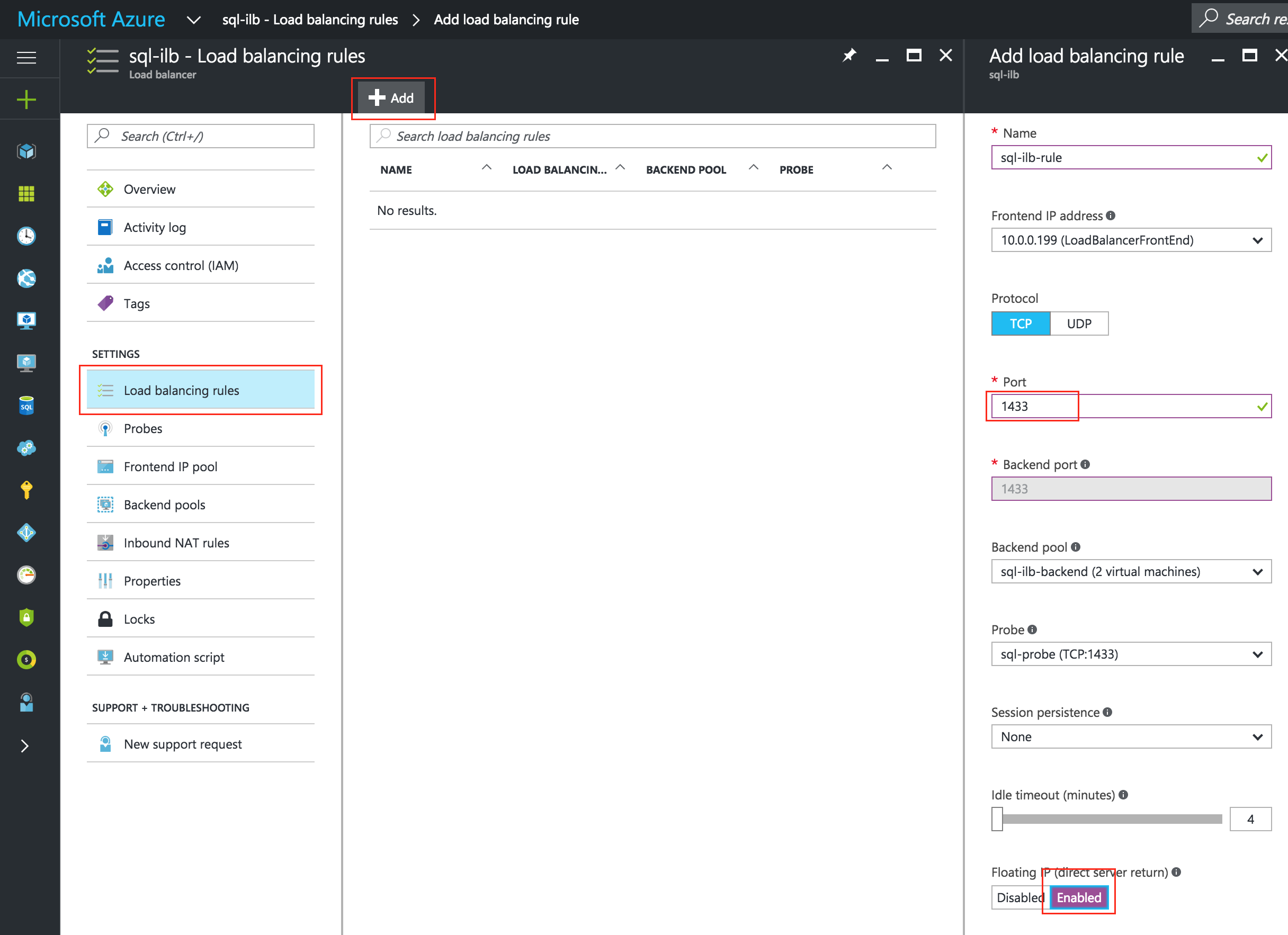
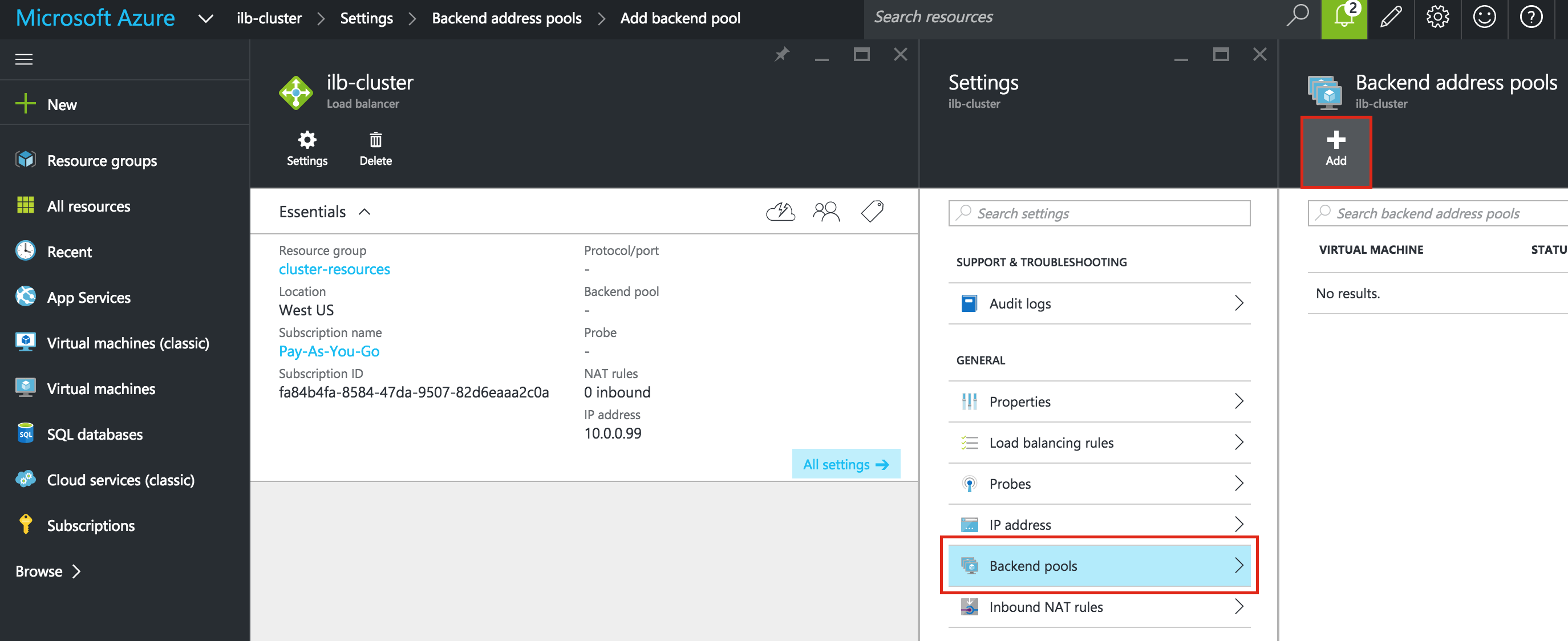
Create an Internal Load Balancer
If this was a typical on-premises cluster using either physical or virtual servers, you’d be done at this point. Clients and Applications would connect into the Virtual IP of the cluster (10.128.0.99) to reach the active node. In Google Cloud, this doesn’t work without some additional configuration.
To connect into the cluster, Google provides a feature were you can setup an Internal Load Balancer (ILB). Essentially, when you connect to the IP address of the ILB (which we will set to 10.128.0.99) you are routed to the currently active cluster node.
Create a TCP Load Balancer:
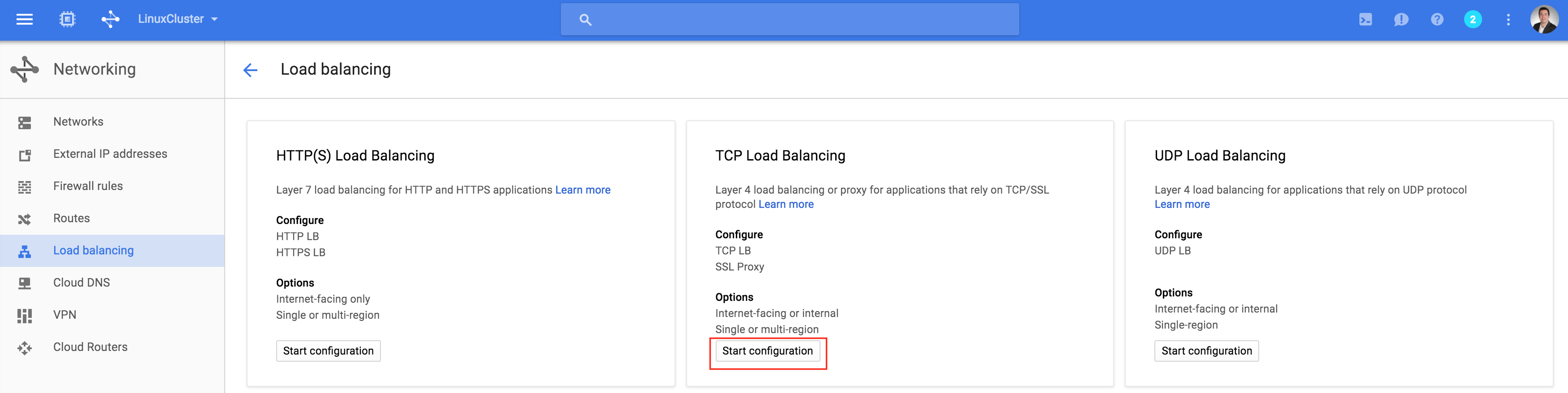
This will be an internal load balancer, so select “Only between my VMs”:
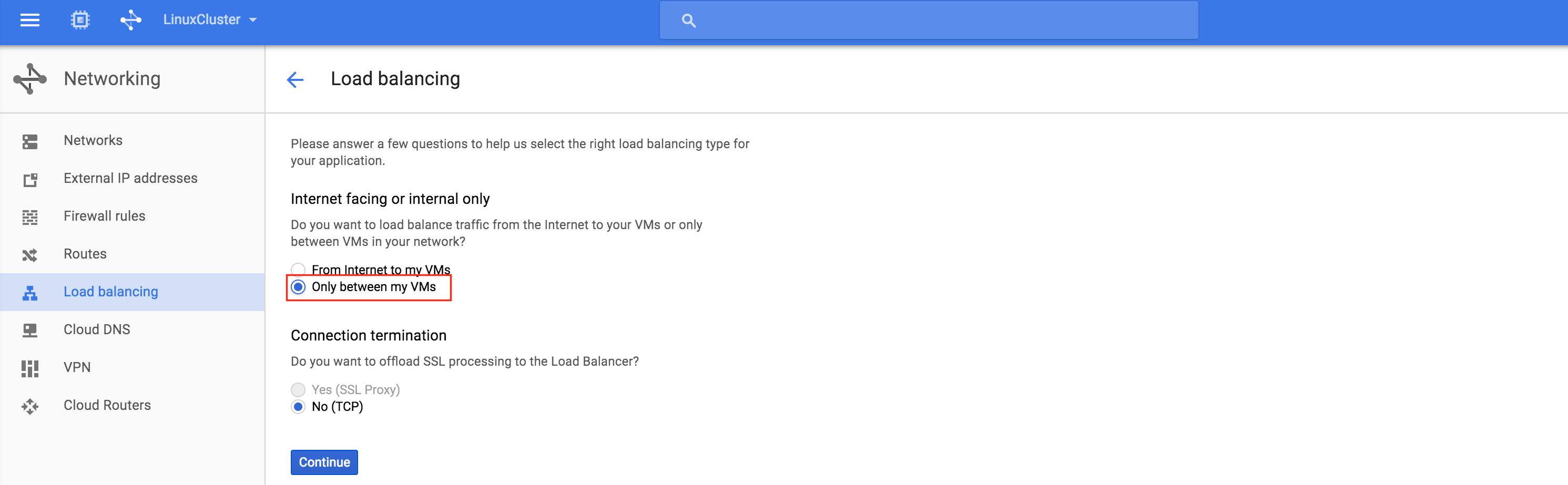
Next, give the load balancer a name (“internal-lb”) and then click Backend configuration:
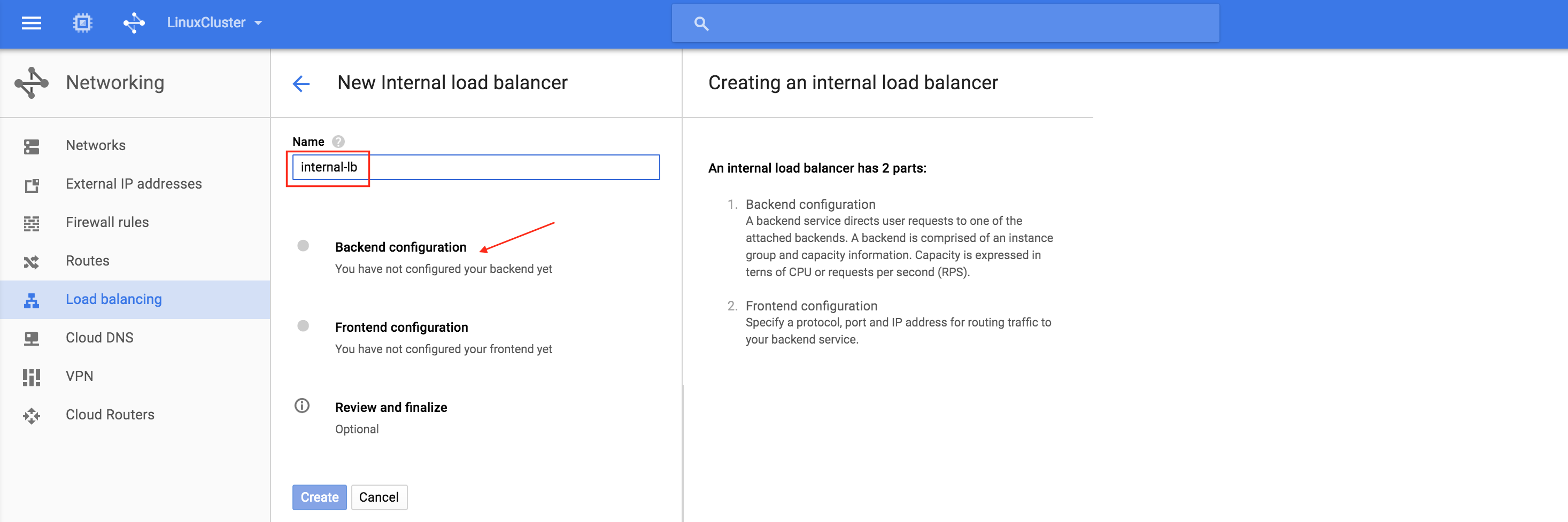
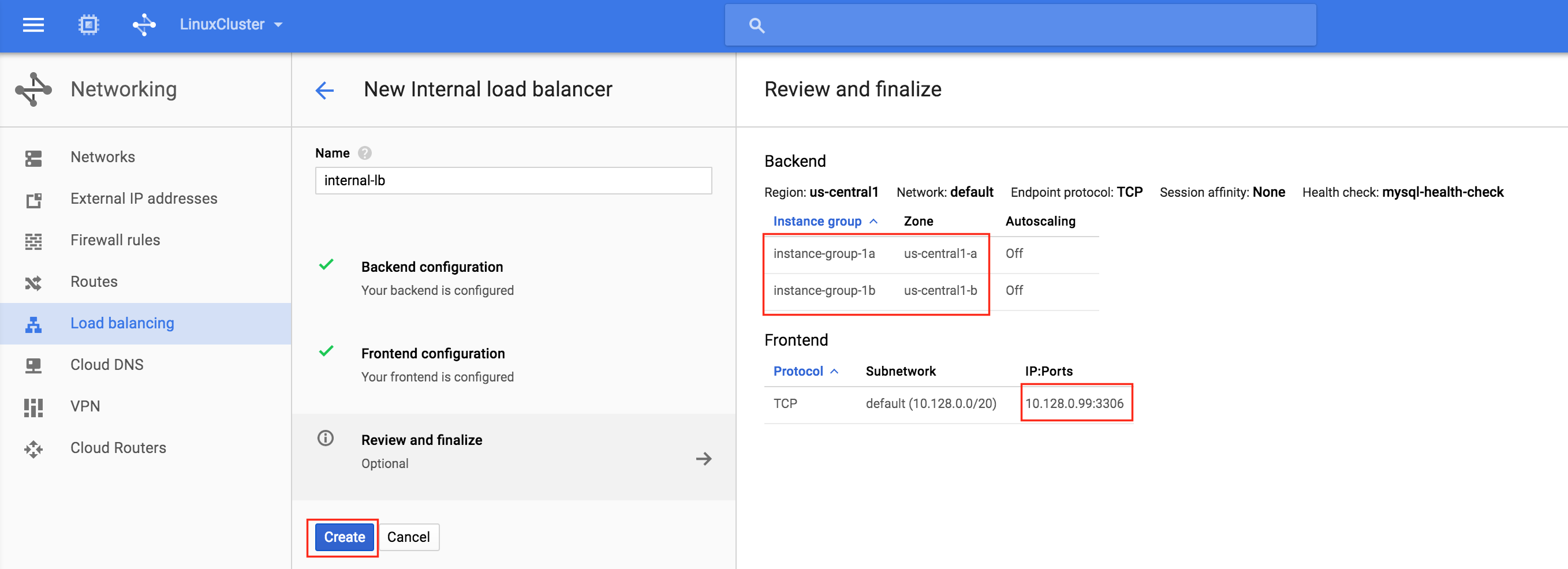
Make sure you select the proper region (“us-central1”) and configure the Backend. Click “+ Add backend” and add both instance groups (instance-group-1a AND instance-group-1b):
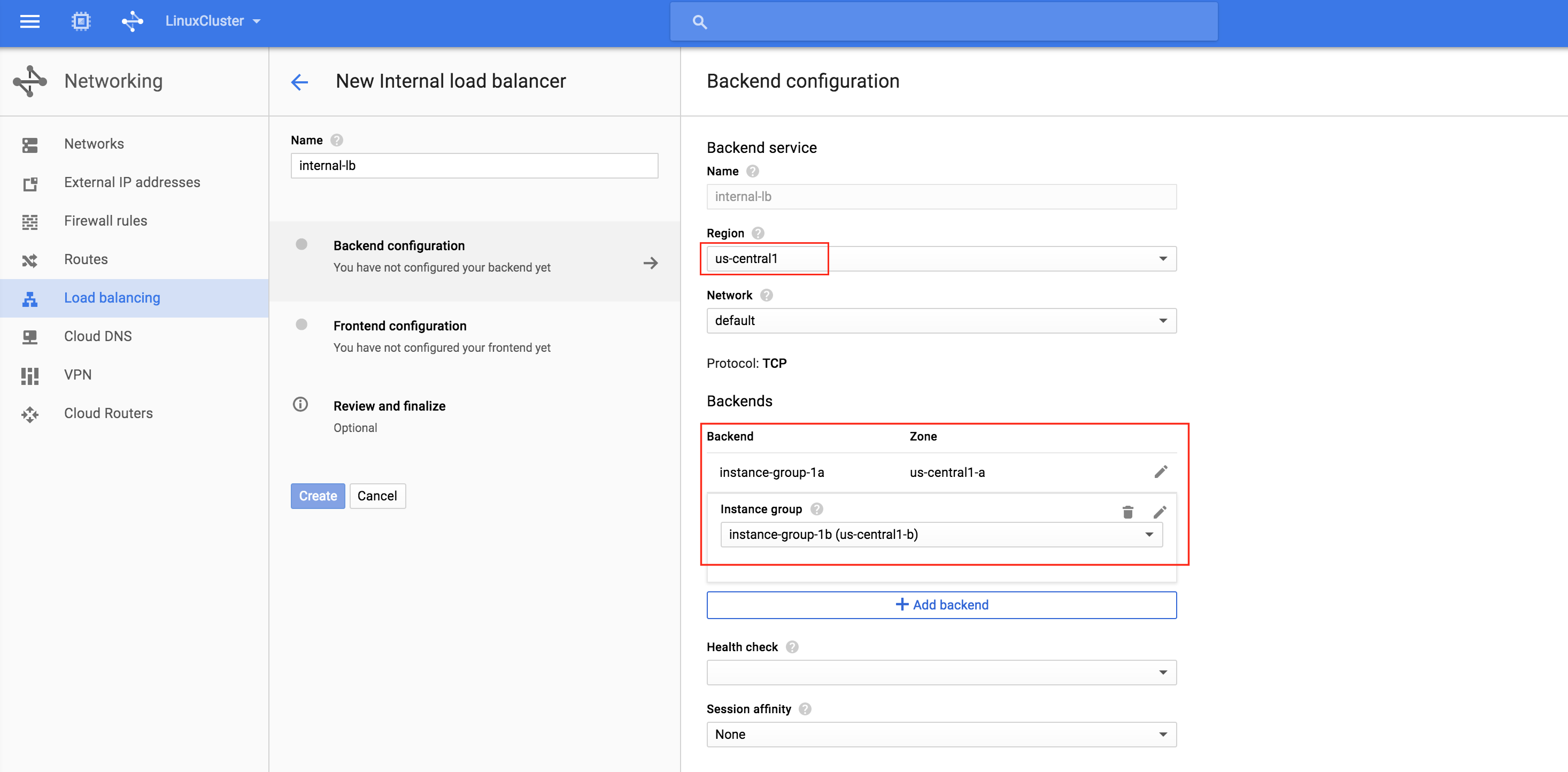
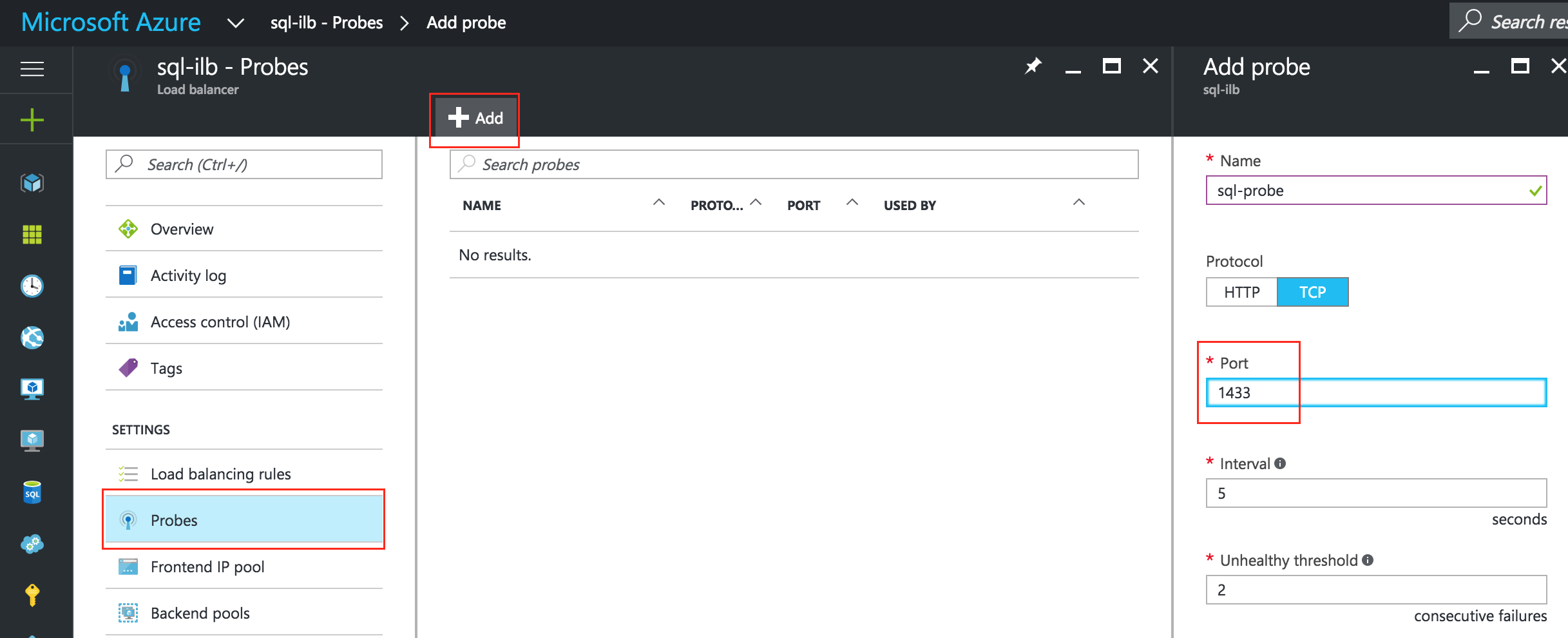
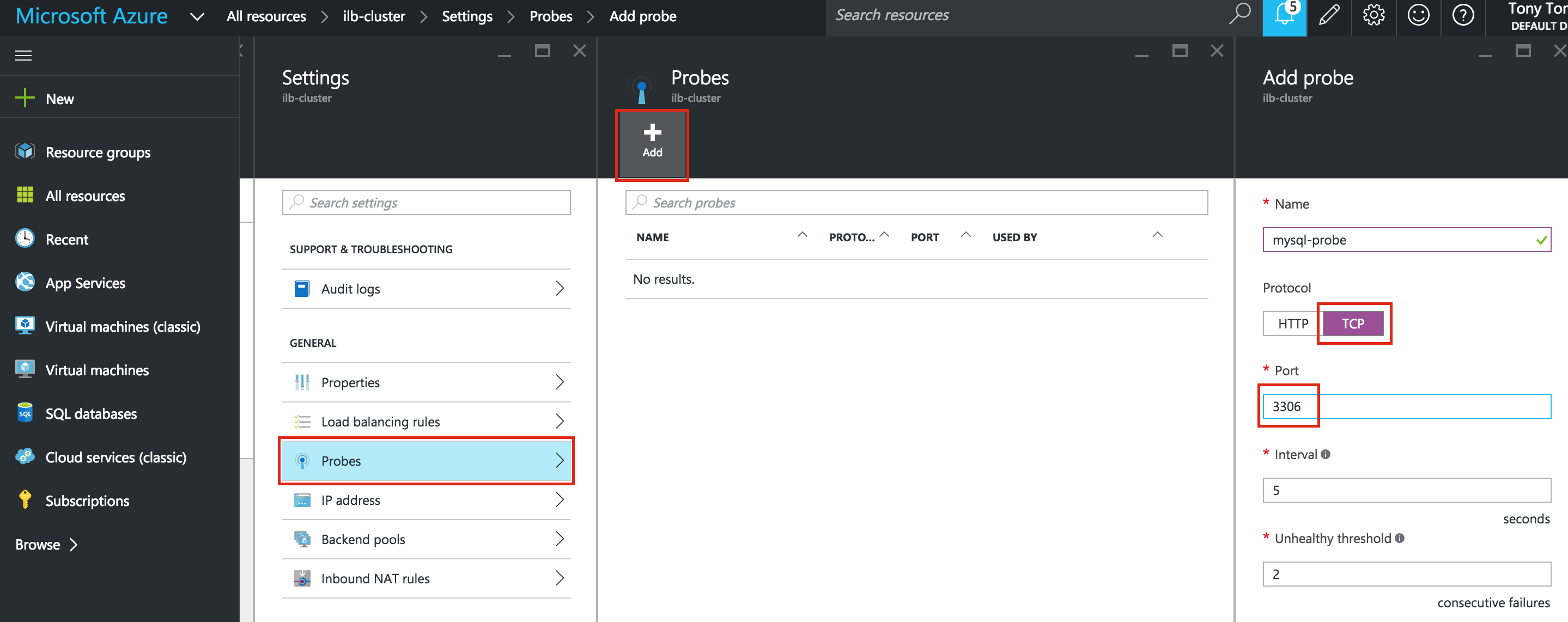
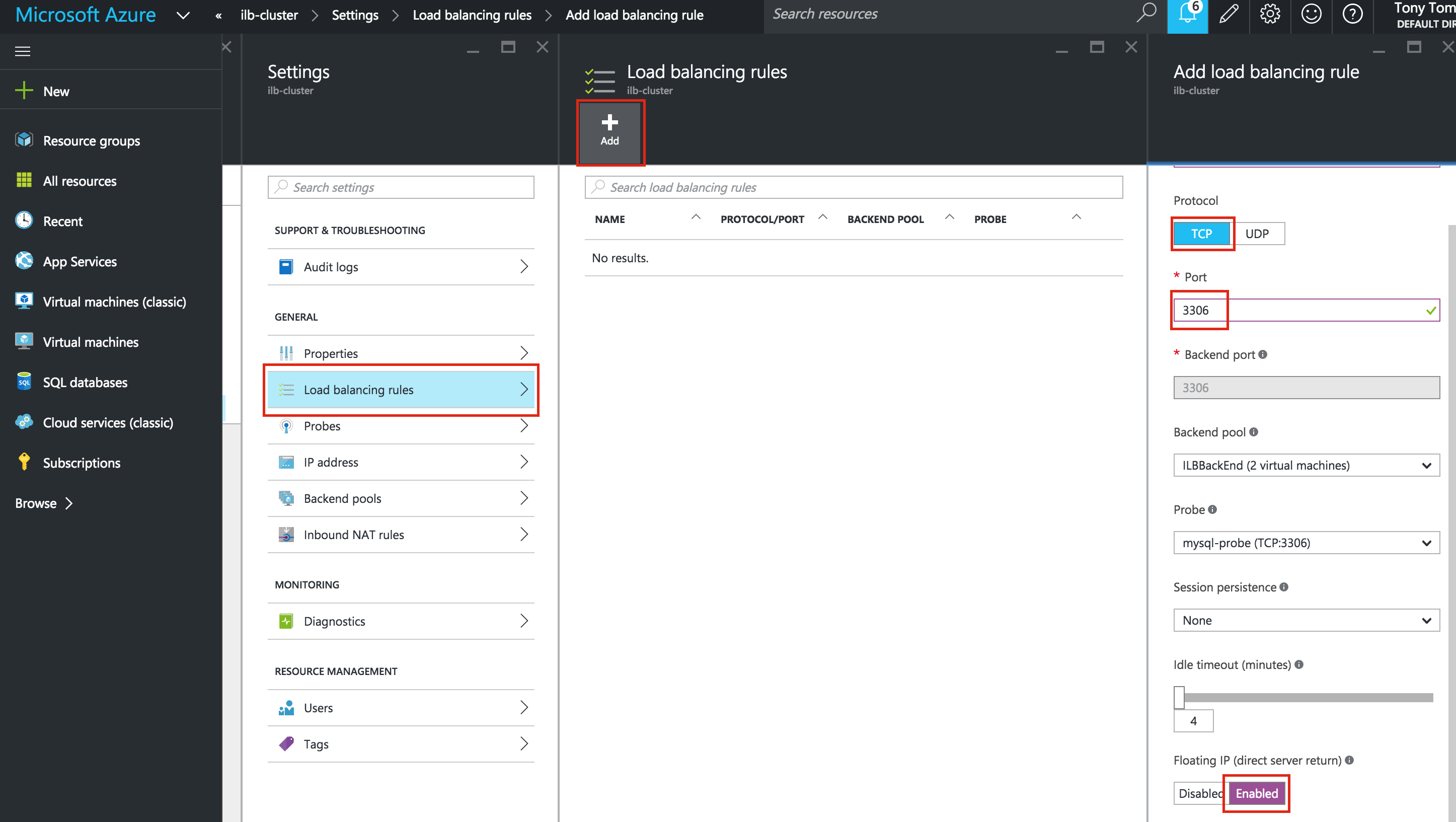
The load balancer decides which node to route traffic to based on a health check. In this example, a health check to see if MySQL is running (checking for default port 3306) will be configured. Select “Create a health check”:
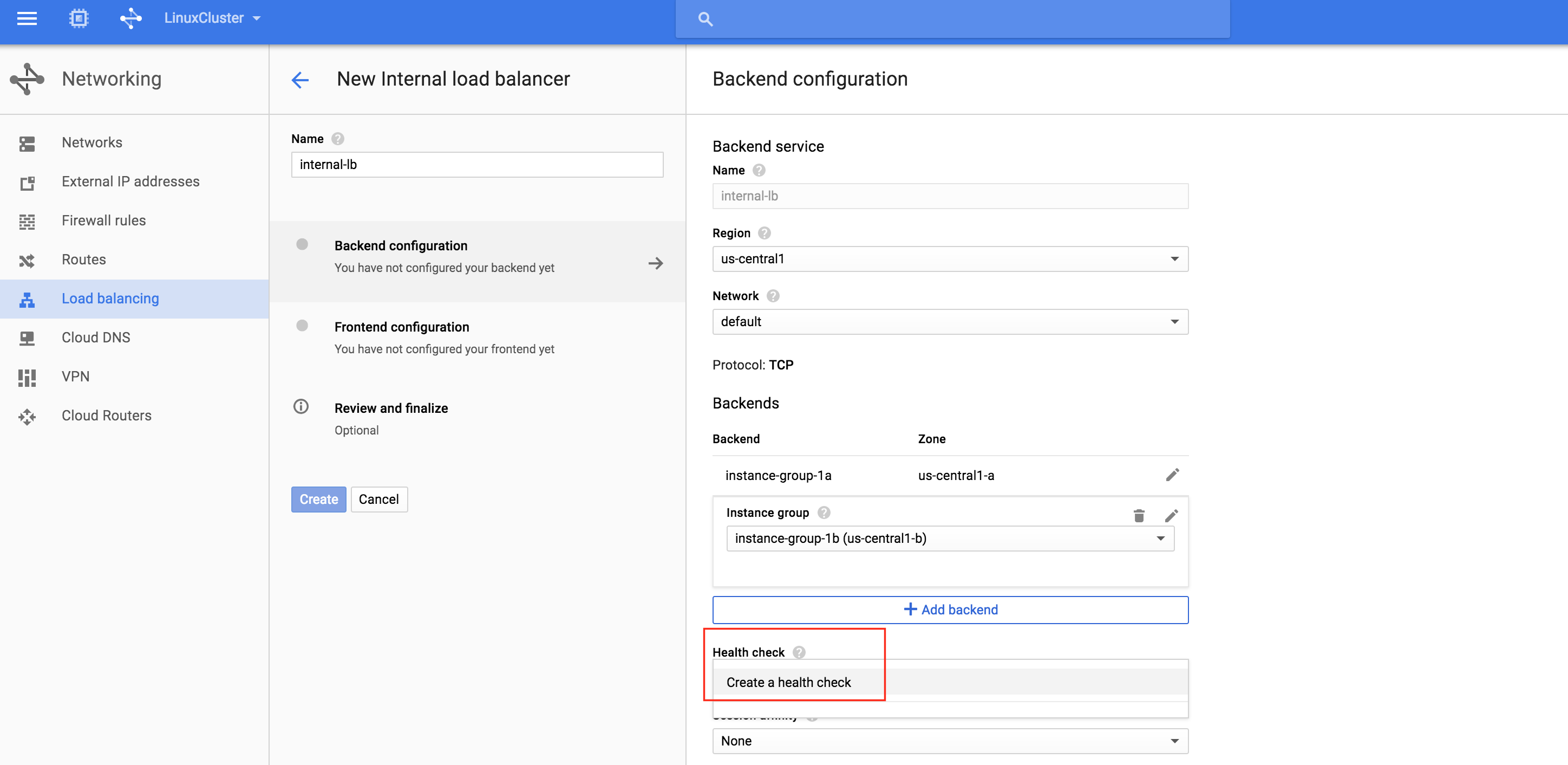
Give the new health check a name (“mysql-health-check”) and configured it for TCP port 3306:
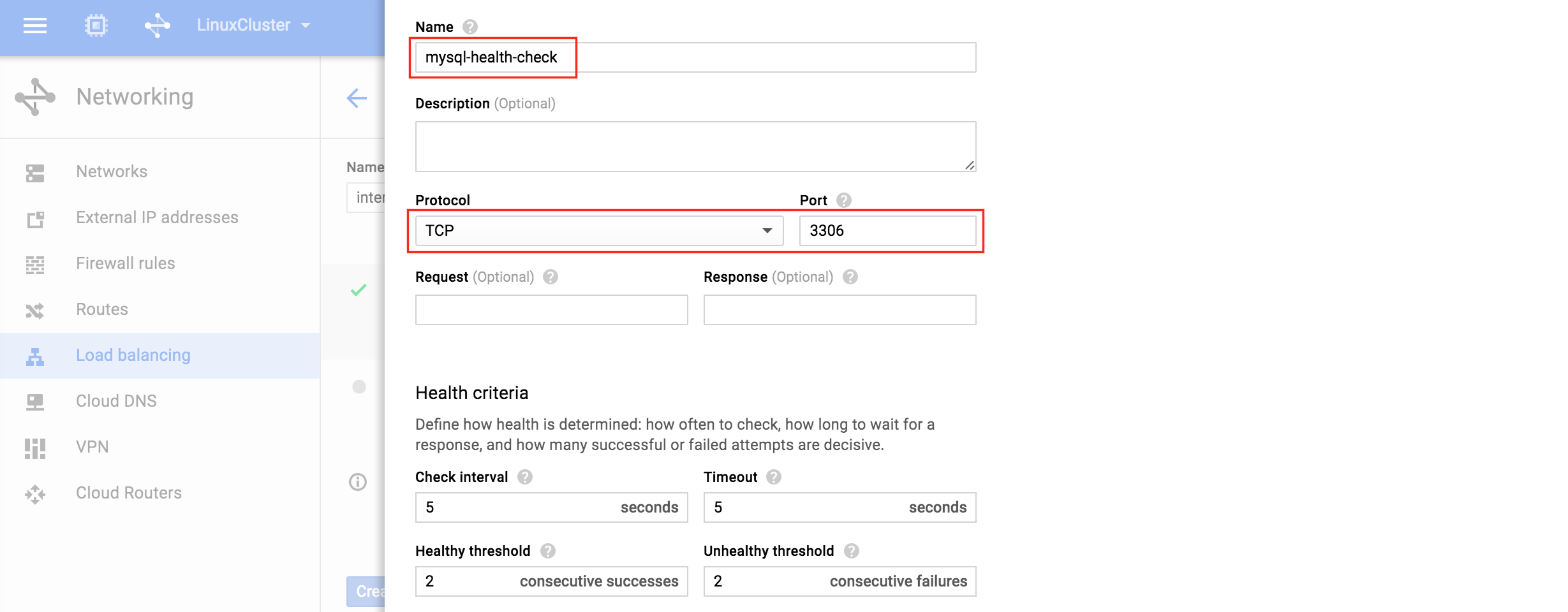
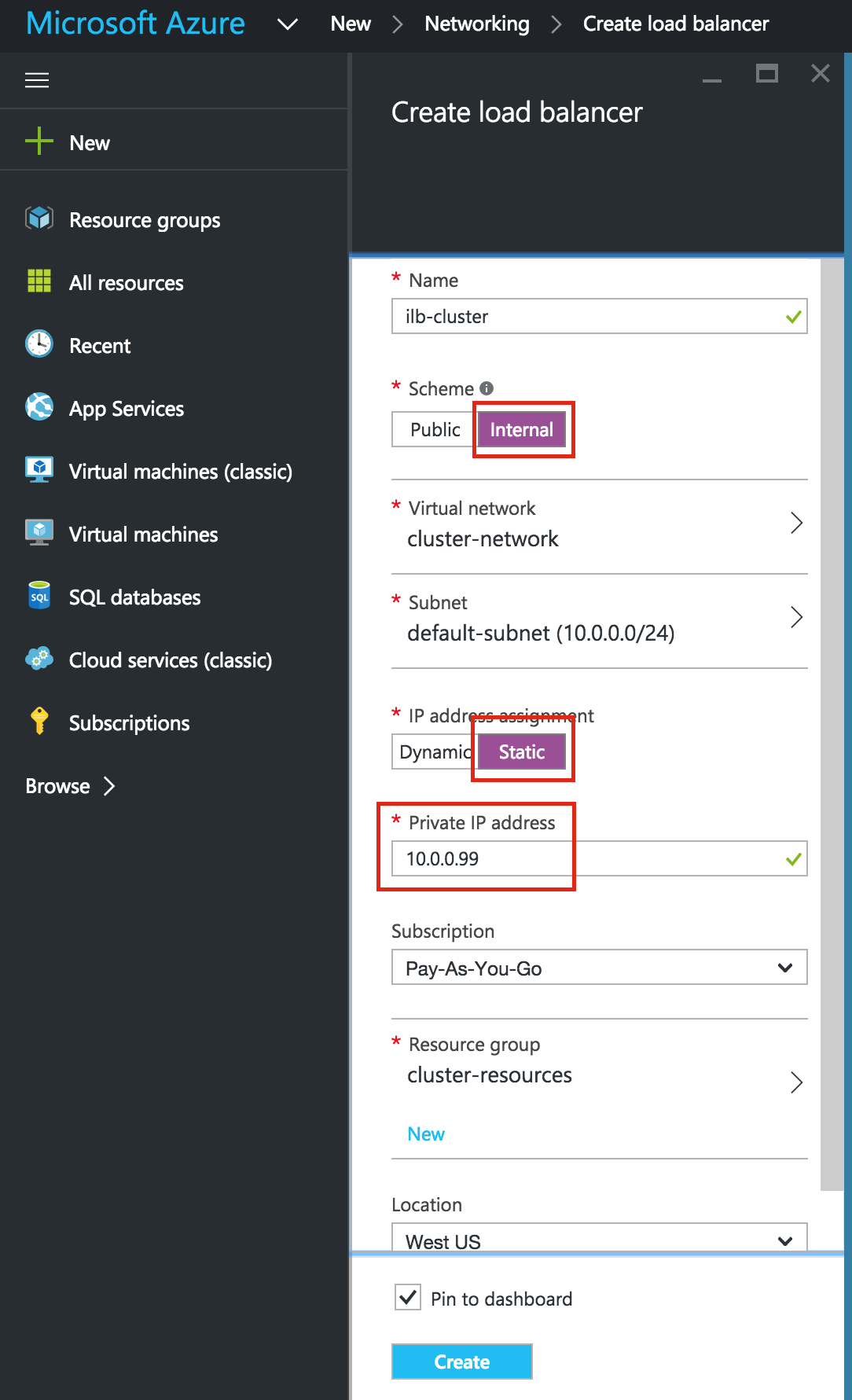
Next, configure the Frontend of the load balancer. Select “Frontend configuration” and under IP address, define a custom static internal IP of 10.128.0.99. The port should be 3306, which is the default port for MySQL:
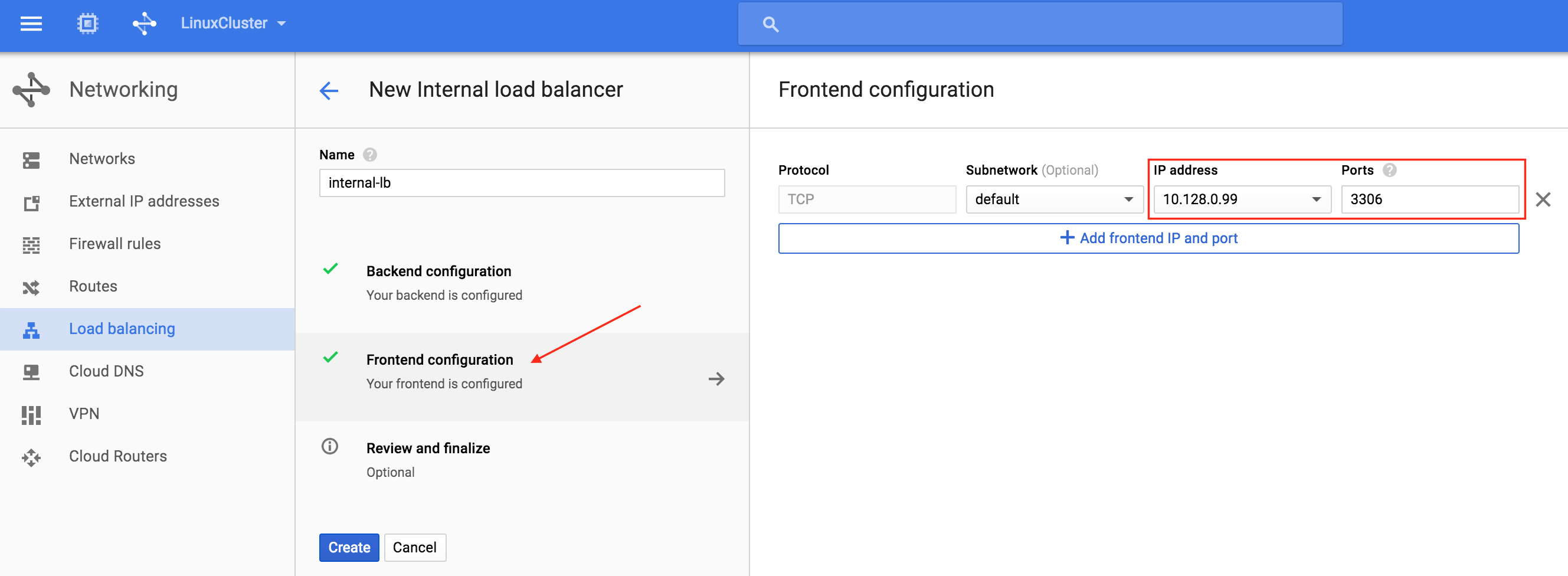
Finally, review and finalize load balancer creation. Click “Create”:
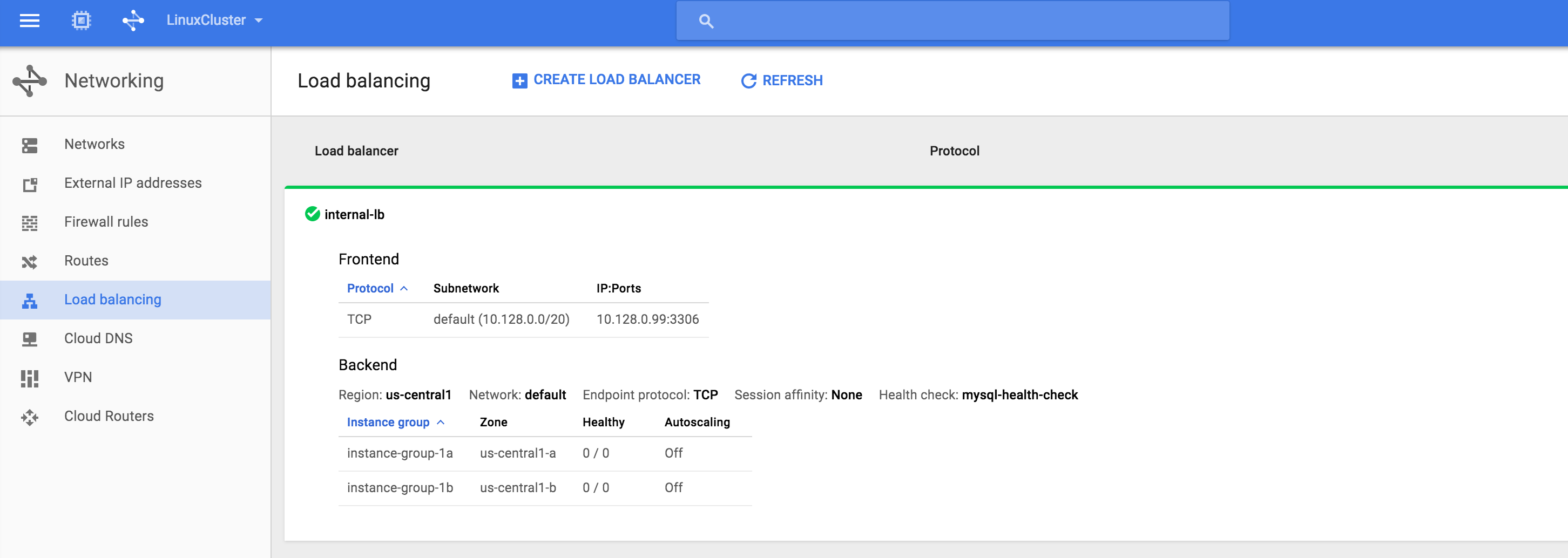
Result. You will see that the load balancer is online, however, it’s not showing either instance group as healthy! (as indicated by the 0/0). We will fix that in the next section:
Create Firewall Rules for Internal Load Balancer
Per Google documentation (see “Configure a firewall rule to allow internal load balancing” section), two firewall rules need to be created. The first allows traffic to the load balancer and from the load balancer to the instances. The second allows health check probes from the health checker.
Create a new firewall rule:
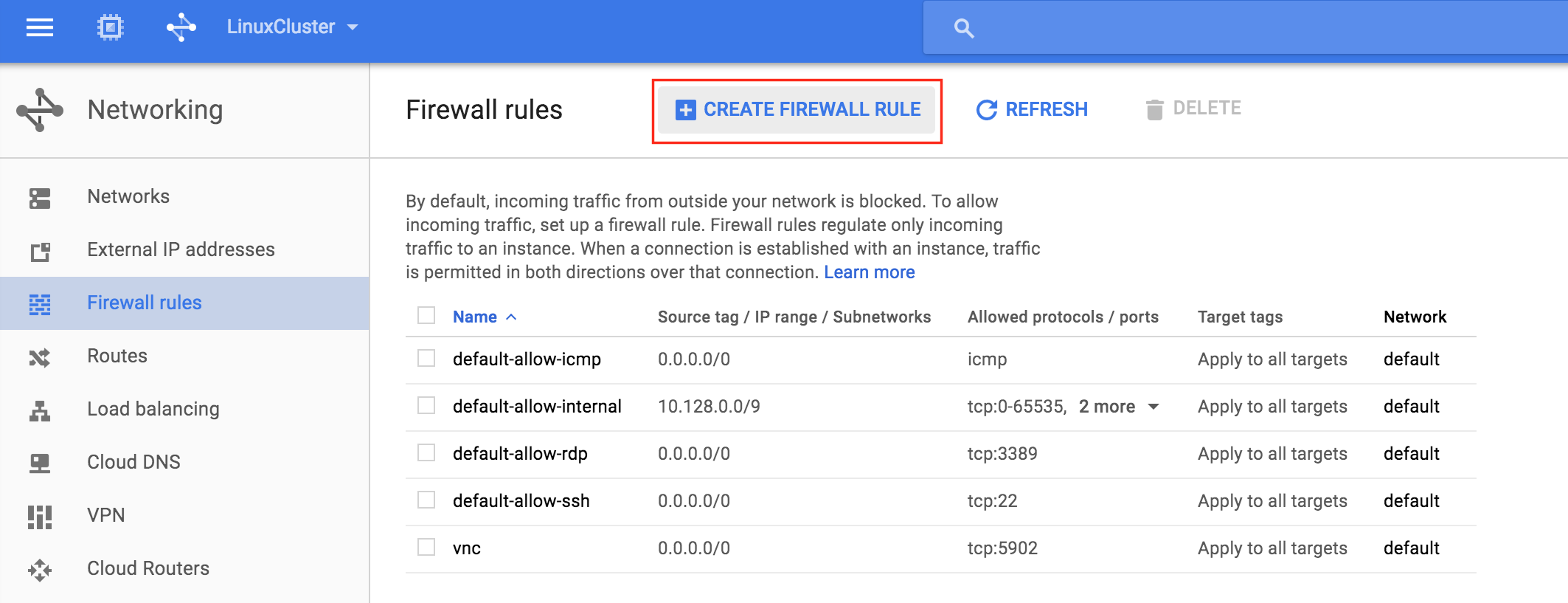
Give the new rule a name (allow-internal-lb) and specify “10.128.0.0/20” as the source IP range. The allowed protocols and ports should be “tcp:3306“:
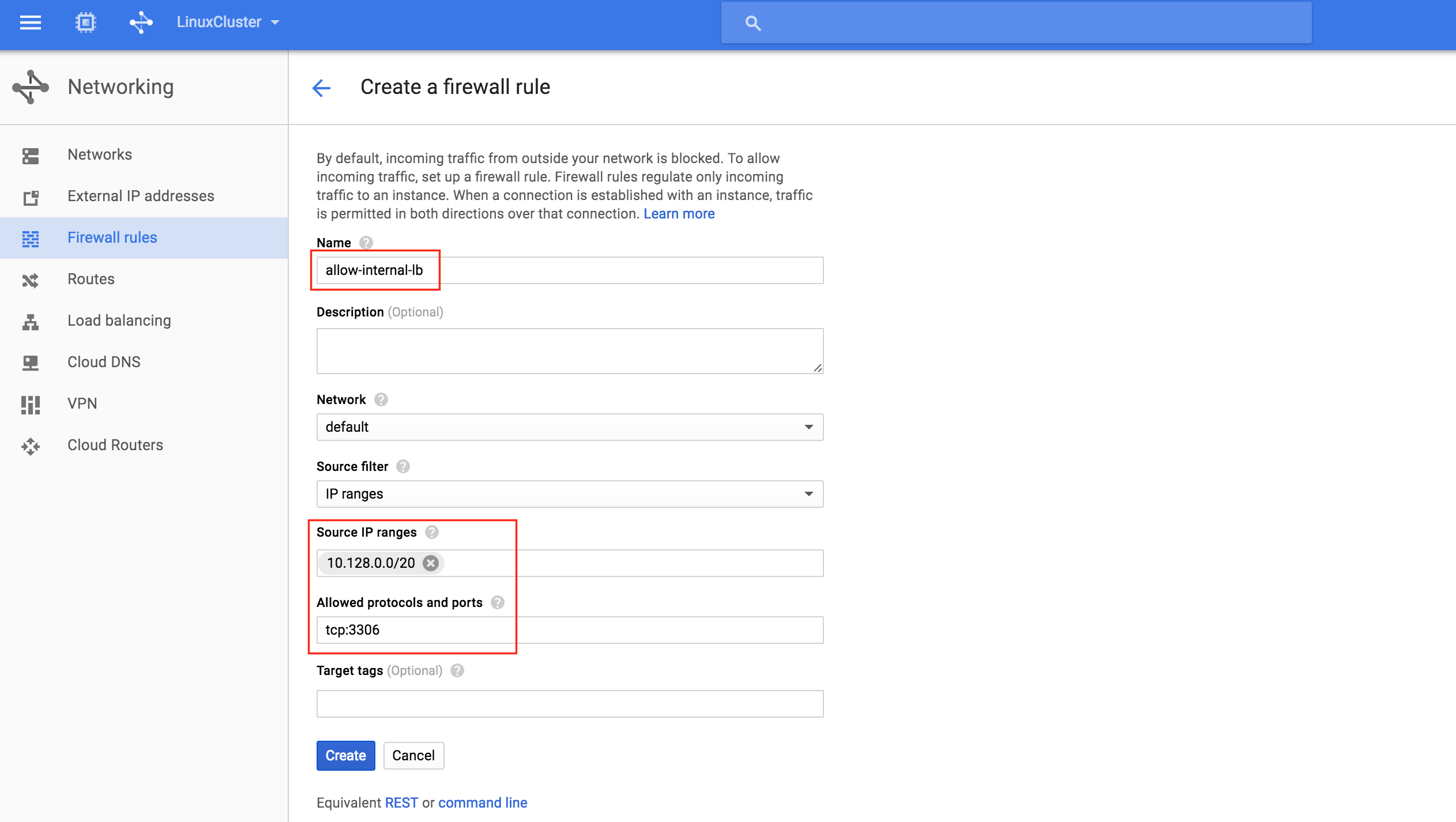
After clicking “Create”, you’ll be returned to the Firewall rules page and can see the newly created rule in the list. Click “Create Firewall Rule” again so we can create the 2nd required rule:
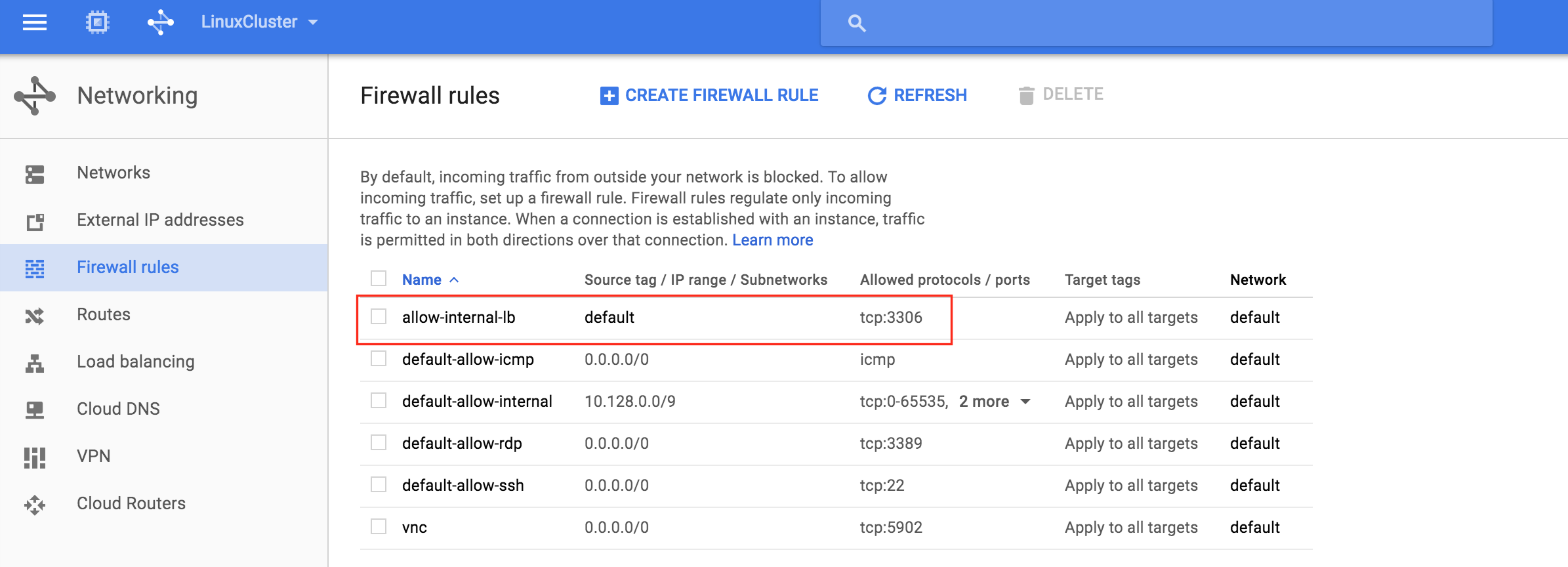
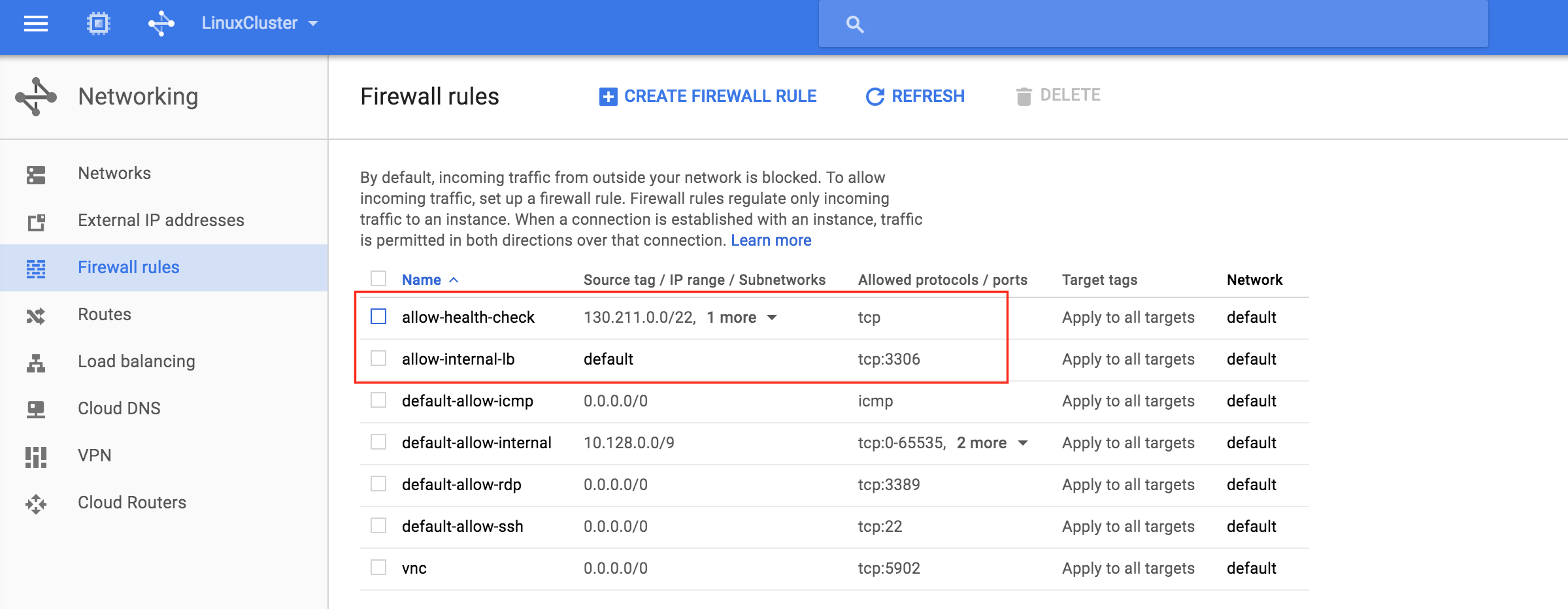
Give the 2nd rule a name (“allow-health-check”). TWO different source IP ranges will need to be defined:
- 130.211.0.0/22
- 35.191.0.0/16
Note: Always a good idea to double check with the google cloud documentation to make sure that these IP ranges are still valid.
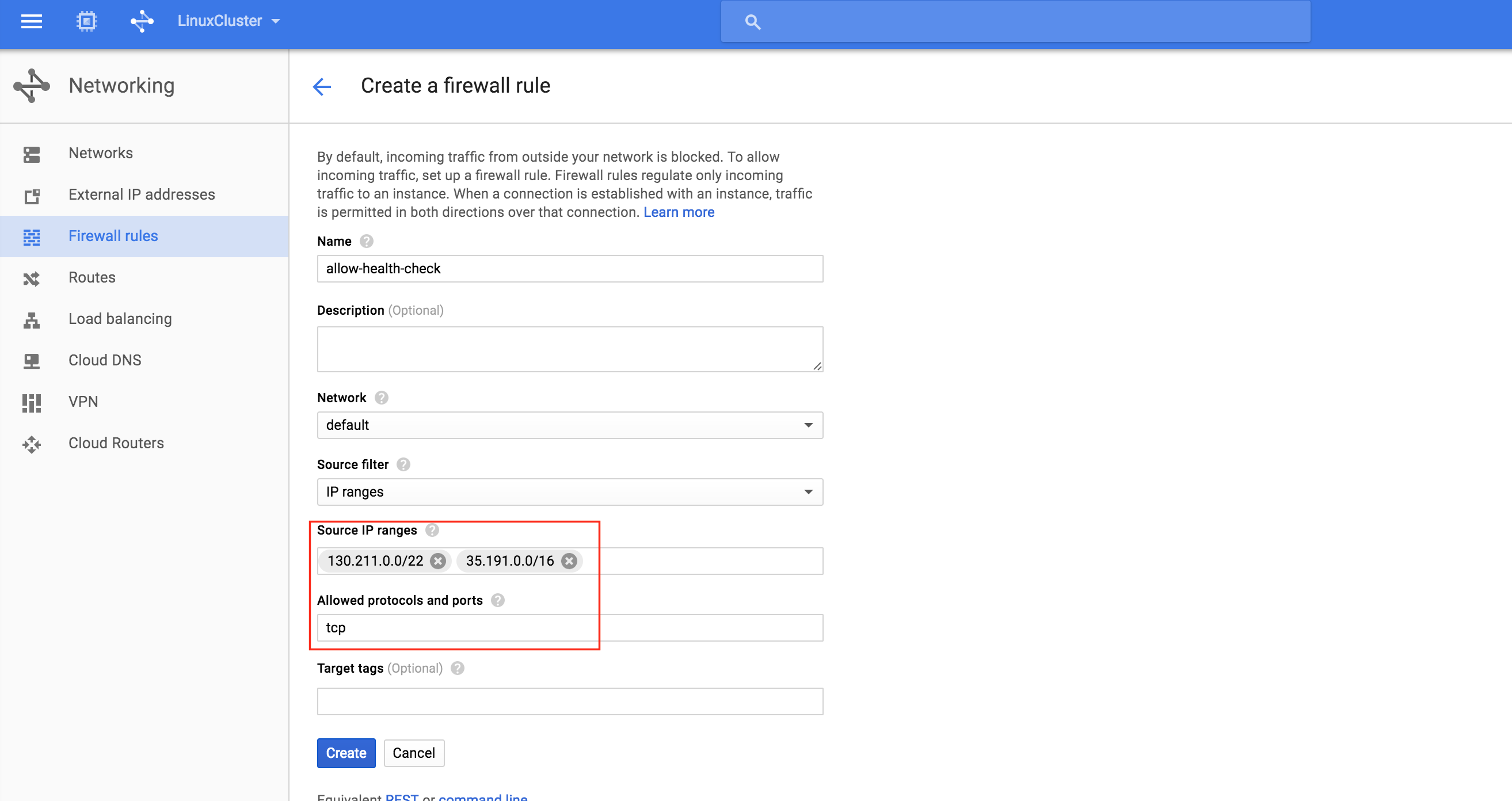
You should now see both newly created firewall rules in the list:
Test Cluster Connectivity
At this point, all of our Google Cloud and Cluster configurations are complete!
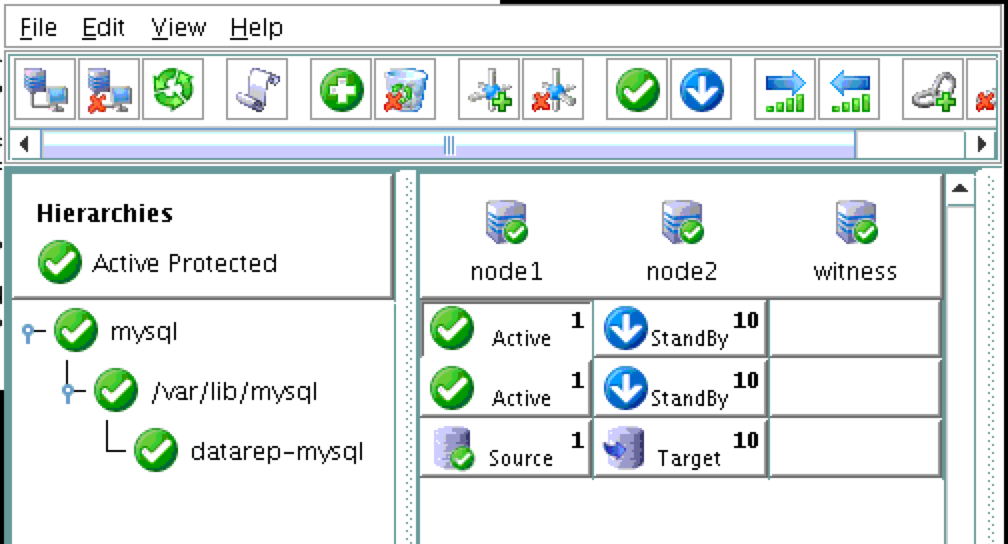
Cluster resources are currently active on node1:
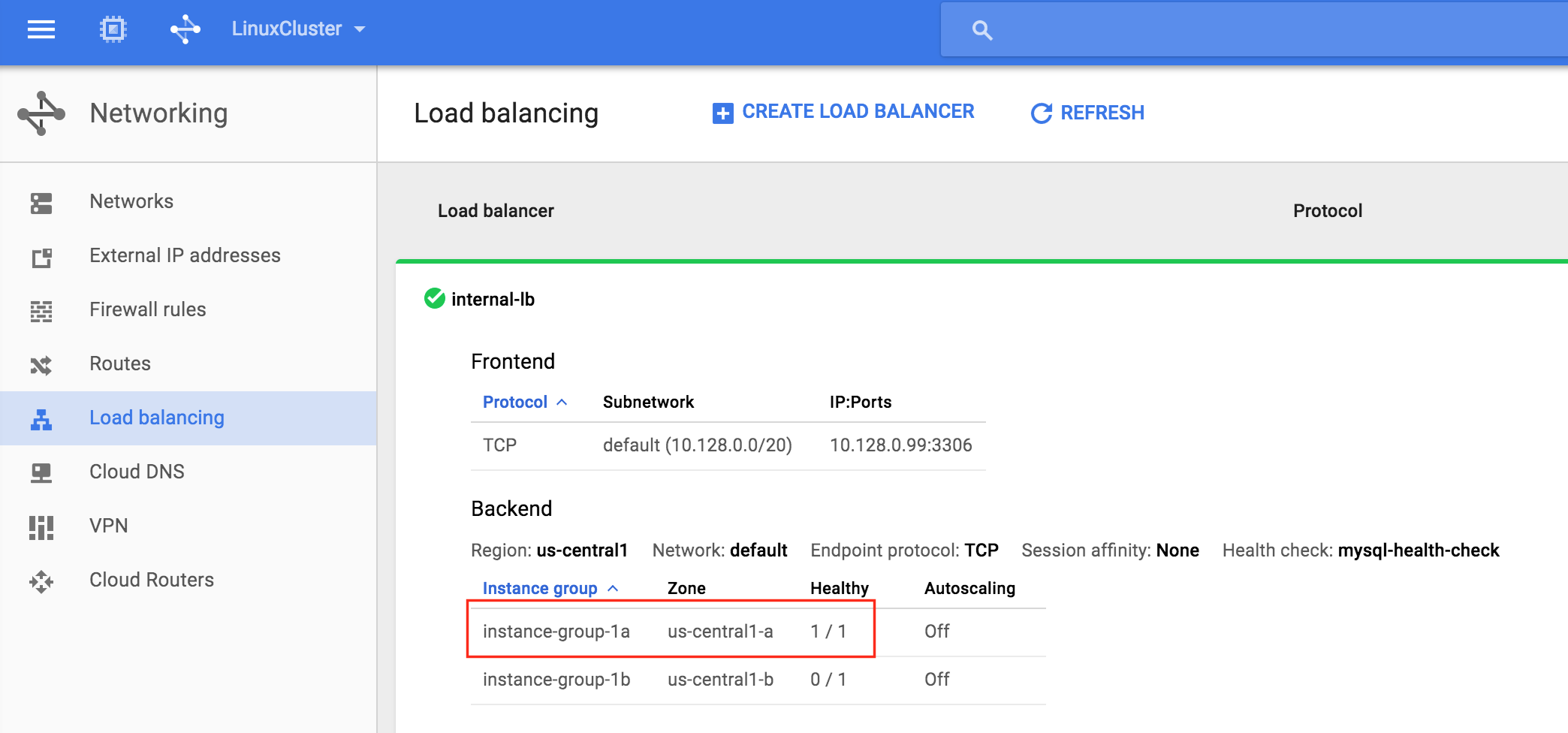
You will also notice that the Internal Load Balancer is showing node1, which is a member of instance-group-1a as “healthy” and as such, routing traffic coming into the virtual IP (10.128.0.99) to node1:
SSH into the witness server, “sudo su -” to gain root access. Install the mysql client if needed:
[root@witness ~]# yum -y install mysql
Test MySQL connectivity to the cluster:
[root@witness ~]# mysql --host=10.128.0.99 mysql -u root -p
Execute the following MySQL query to display the hostname of the active cluster node:
mysql> select @@hostname; +------------+ | @@hostname | +------------+ | node1 | +------------+ 1 row in set (0.00 sec) mysql>
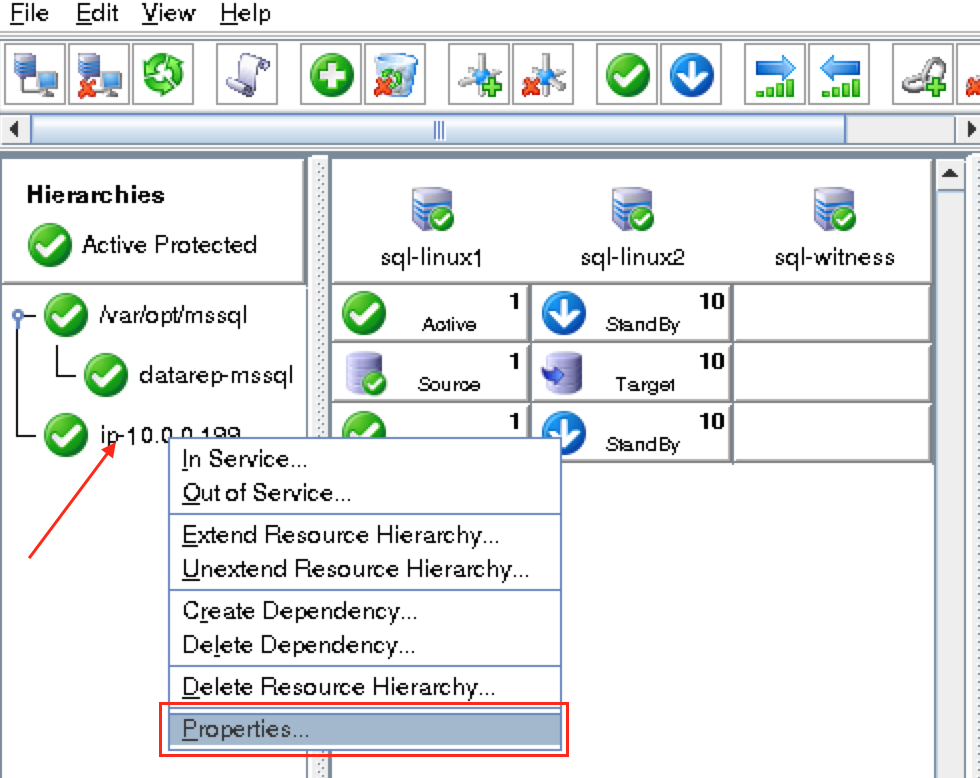
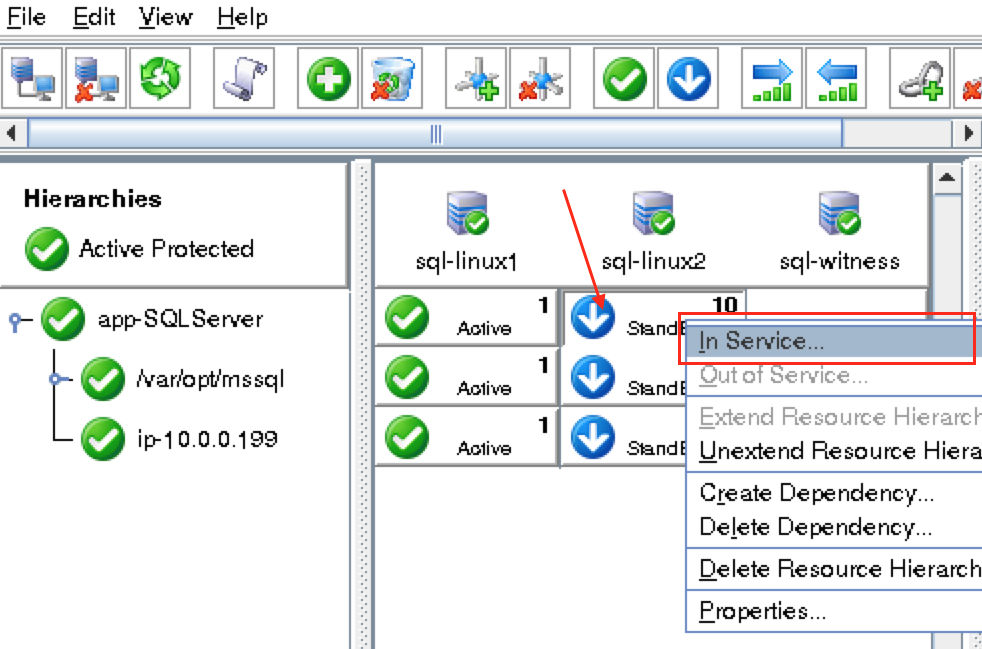
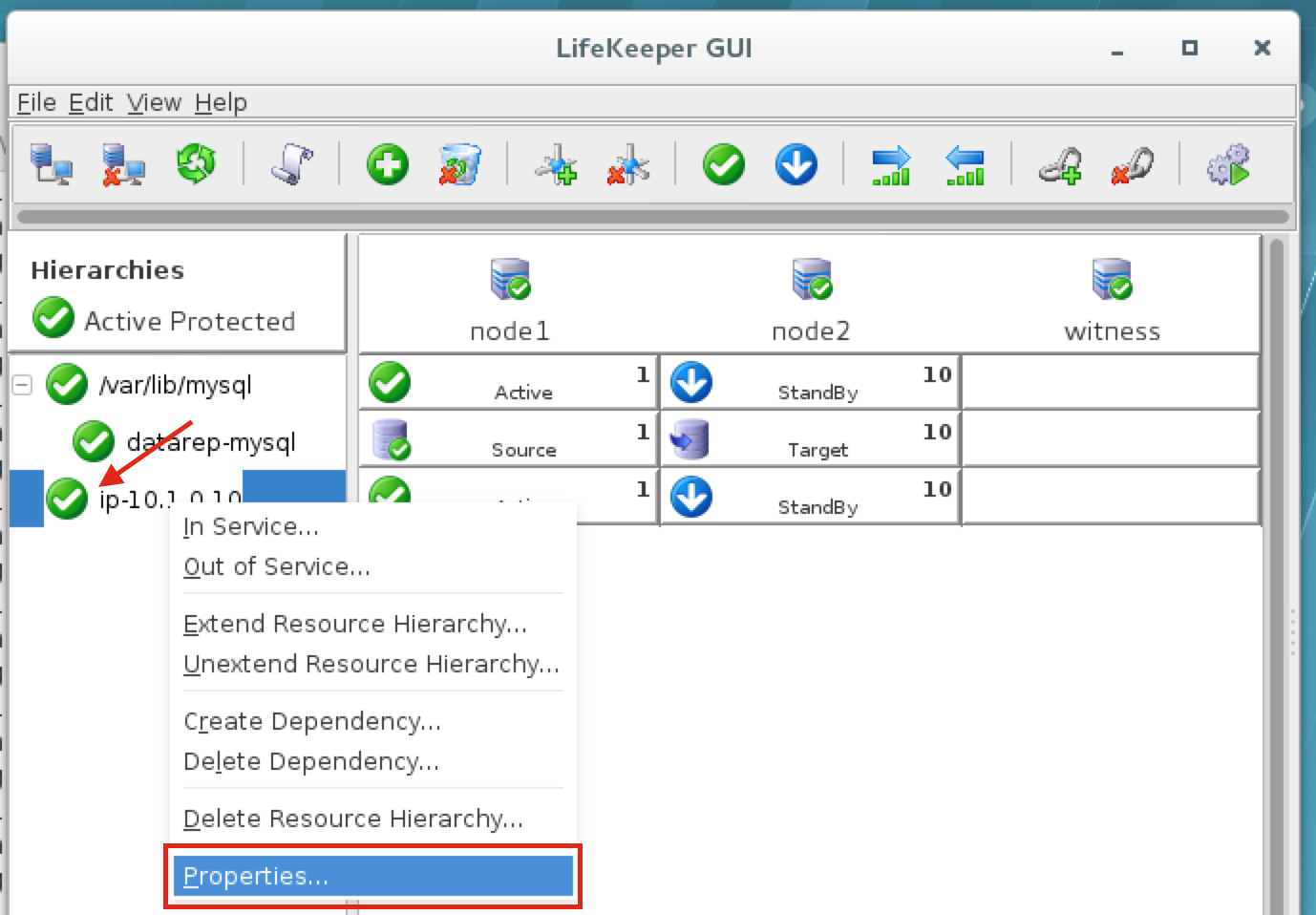
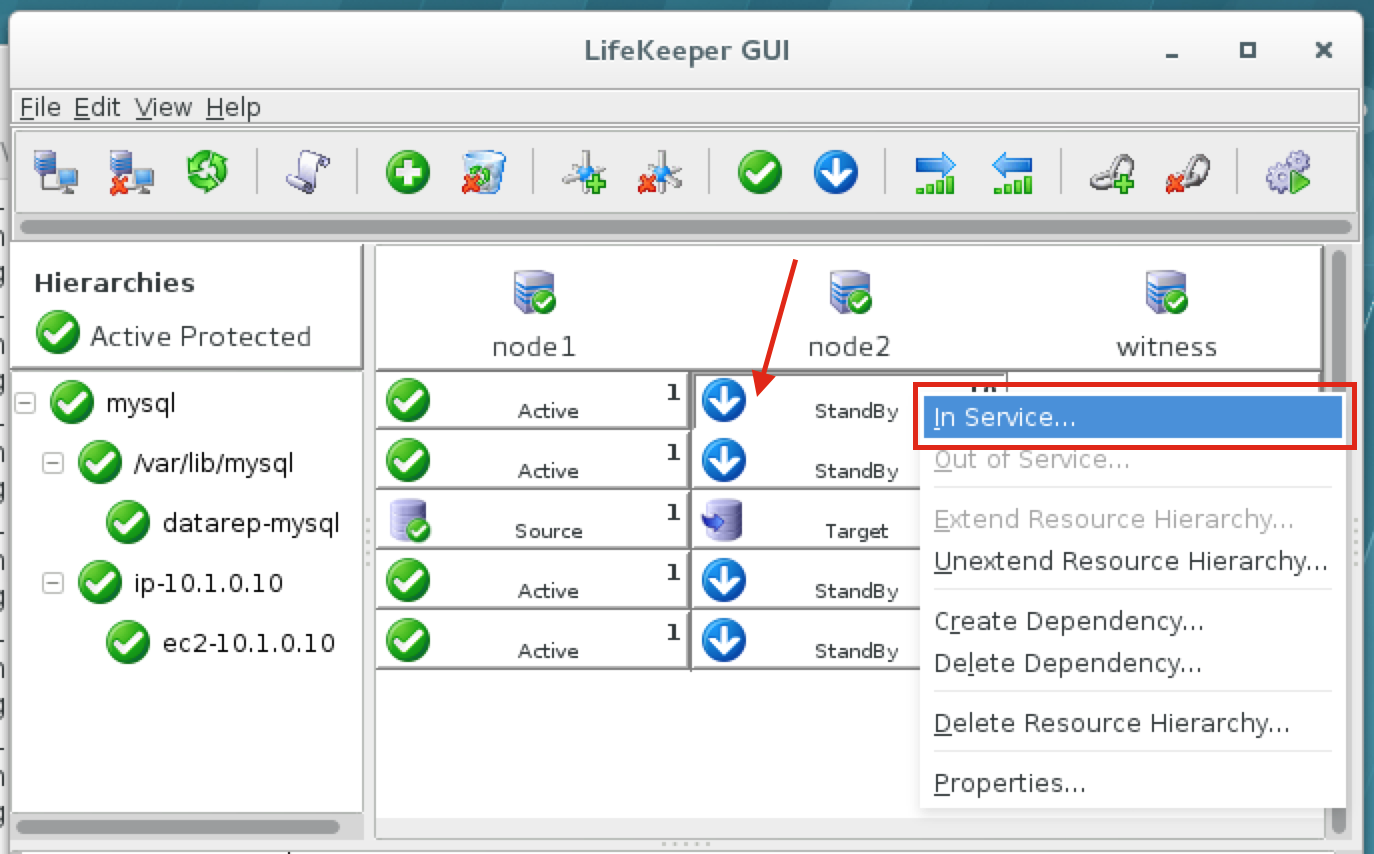
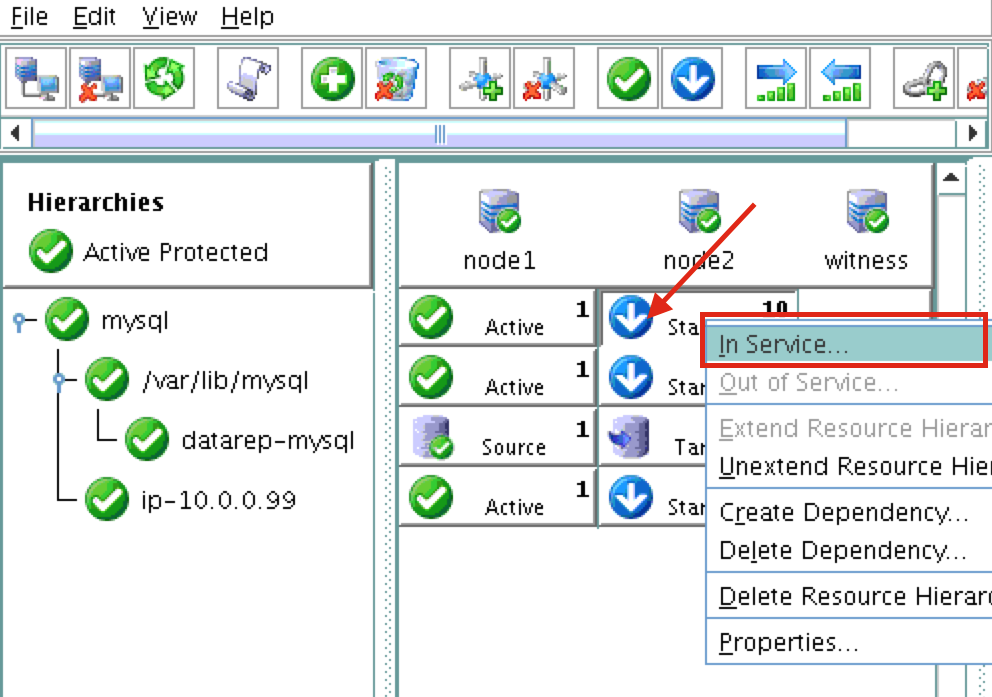
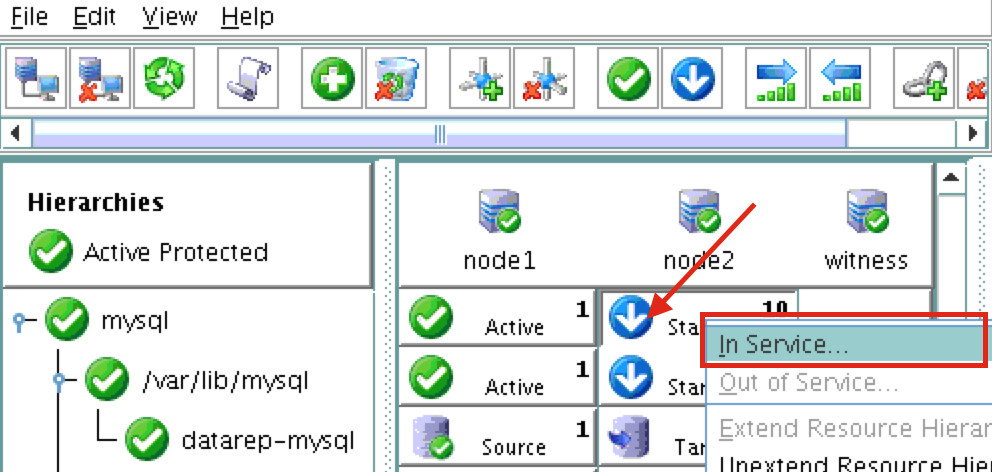
Using LifeKeeper GUI, failover from Node1 -> Node2″. Right click on the mysql resource underneath node2, and select “In Service…”:
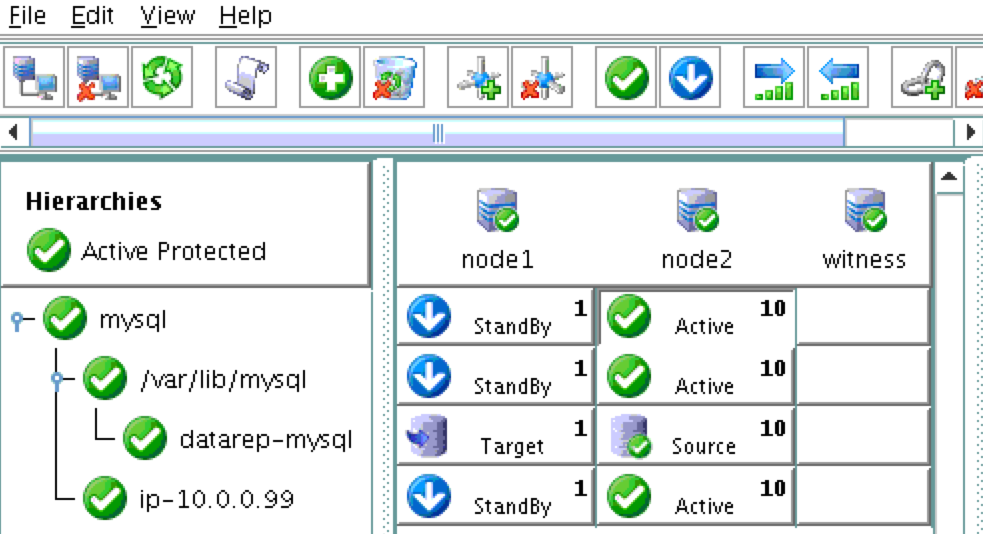
After failover, resources are brought online on node2:
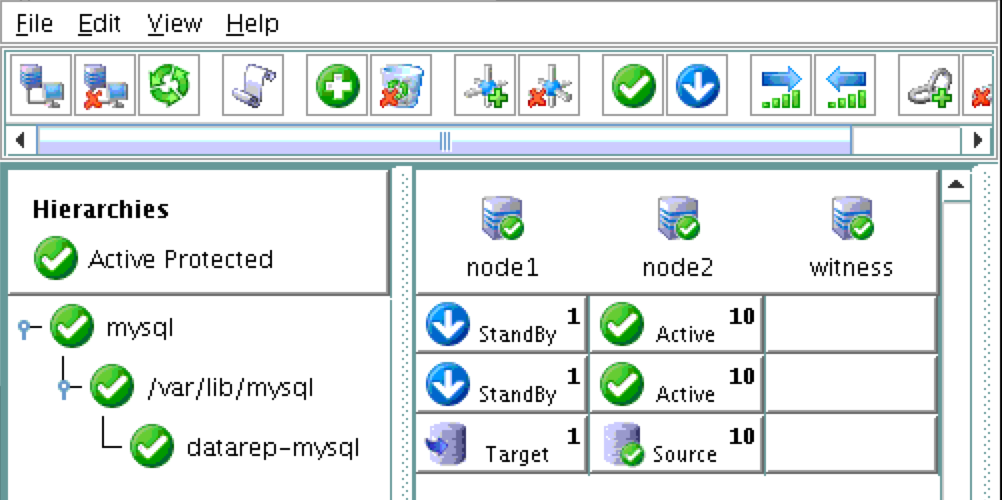
You will now see that the Internal Load Balancer is showing instance-group-1b, which contains node2, as healthy. Traffic is now routed to node2:
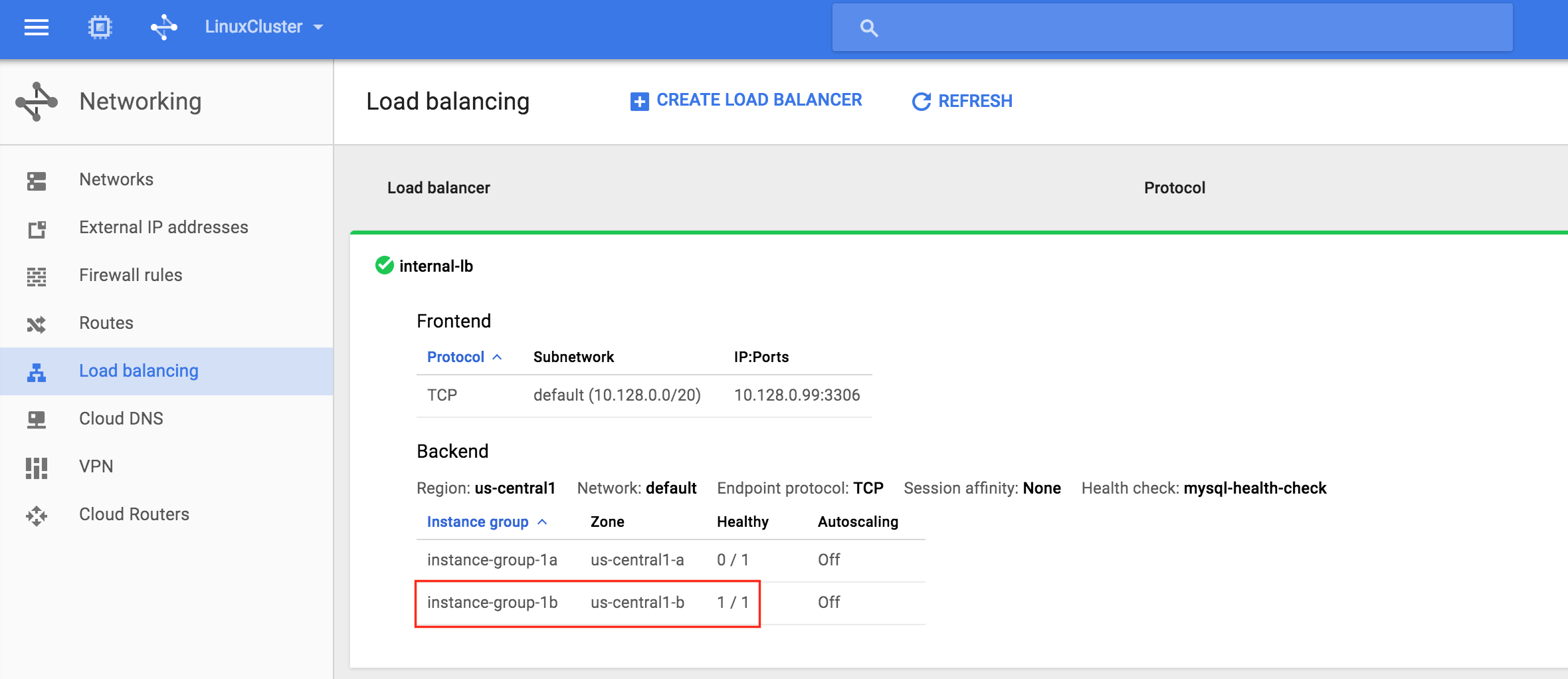
After failover has completed, re-run the MySQL query. You’ll notice that the MySQL client has detected that the session was lost (during failover) and automatically reconnects:
Execute the following MySQL query to display the hostname of the active cluster node, verifying that now “node2” is active:
mysql> select @@hostname; ERROR 2006 (HY000): MySQL server has gone away No connection. Trying to reconnect... Connection id: 48 Current database: mysql +------------+ | @@hostname | +------------+ | node2 | +------------+ 1 row in set (0.56 sec) mysql>